
在本系列章節中,我們即將踏入分佈式追蹤的神聖領域,這是一個伴隨著雲原生技術和 Kubernetes 容器編排工具的興起,在近十幾年逐漸形成的專業領域。隨著微服務的複雜性日益加劇,人們漸感其如同黑盒子般的除錯體驗,因此開始尋找各種理想的解決方案。分佈式追蹤雖具有比傳統日誌更高的概念門檻,但得益於社群的積極參與和不斷努力,它逐漸變得更加完善和易於理解。作為開源可觀測性的代表性組織,Grafana 團隊推出了其自家研發的 Grafana Tempo,這一工具秉持著易用性和高性價比的原則,與 Grafana 的可視化界面緊密整合,為我們帶來了前所未有的可觀測性體驗。面對 Grafana Tempo 如此多的優勢,我們還有什麼理由不被它深深吸引呢?

Grafana Tempo 是一款由 Grafana Labs 推出的開源大規模分佈式跟踪後端系統,以 Go 語言實現,設計之初就注重易用性和高效益。與市場上知名的 Jaeger、Zipkin 和 OpenTelemetry 等分佈式追踪協議系統相比,Tempo 以其深度集成 Grafana、Prometheus 和 Loki 的特點,以及僅依賴於對象存儲進行運行的低成本和簡單操作而脫穎而出。
Grafana Tempo支持與任何開源跟踪協議一起使用,無論是 Jaeger、Zipkin 還是 OpenTelemetry,都能與之兼容。它專注於批次提取數據,進行緩存,然後將數據寫入GCS,S3 或本地硬碟,高性價比且易於操作。相較於其他解決方案,Tempo以其簡單而高效的設計,能夠應對大容量的分佈式追踪需求。
為了增強搜索,大多數開源分散式追蹤框架都會對追蹤中的許多欄位進行索引,包括服務名稱、操作名稱、標籤和持續時間,為此大多依賴於 Elasticsearch 或 Cassandra 這類複雜索引系統。後來,Grafana Labs 意識到,追蹤信號不一定需要使用索引,通過日誌和樣本就可以發現追蹤信號,因此不必為其添加索引花費額外的成本。基於這些考慮,他們創建了 Grafana Tempo,一個精簡、簡單且按 id 進行追踪的存儲機器,滿足用戶對於分佈式追踪的各種需求。
分佈式追踪是一項技術,專門用於搜集應用程式內部與端到端請求相關的資料,以實現對整個系統的監控和分析。在這個過程中,一個追踪會被分解成一個或多個「跨度 Span」,每個跨度代表請求中的一次呼叫,這可能是一個微服務,或者是微服務內的一個函數。追踪的基本結構如下所示:
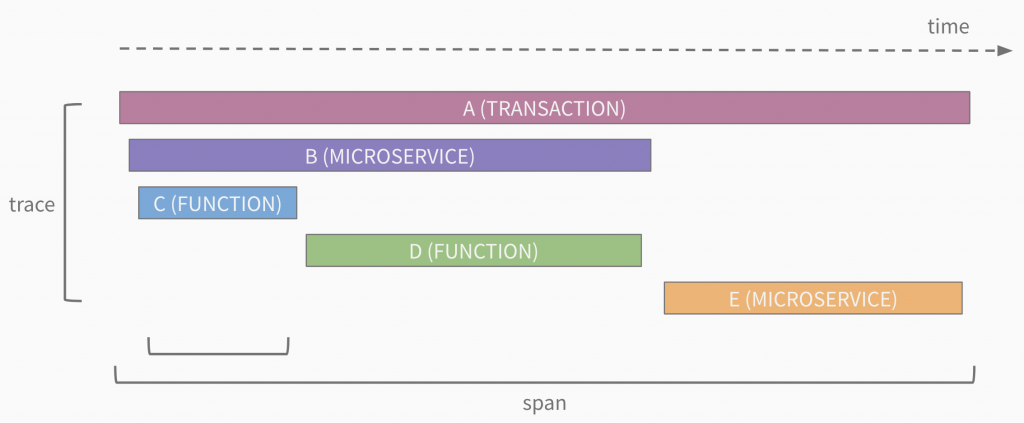
追踪的起點是根跨度,其後可以跟隨一個或多個子跨度。這些子跨度可根據呼叫堆疊的深度進行嵌套。每個跨度都會包含服務名稱、操作名稱、持續時間,還可以選擇性地附帶額外的元數據。
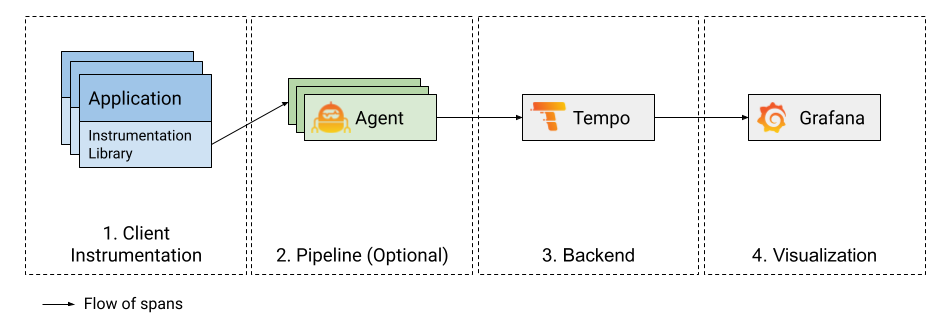
現有的分佈式追踪工具的工作方式大致相同,通常使用相同的架構組件。然而,在實現方式和使用的追踪協議上,它們之間可能存在差異。以下將以Grafana Tempo為例來說明:
上圖顯示了 Grafana Tempo 如何與追踪協議、對象存儲和 Grafana 一起工作。與大多數分布式追踪生態系統一樣,Grafana Tempo 依賴四個主要組件來發揮其用途:
這些組件共同形成了 Grafana Tempo 分布式追踪工具的基礎,使其能夠靈活應對各種應用場景和需求。
市面上有眾多工具值得我們深入了解幾個最受歡迎的開源分佈式追踪解決方案,它們都是為容器化運行環境所設計且工作原理都相似,因此對它們進行高層次的比較相對直接。
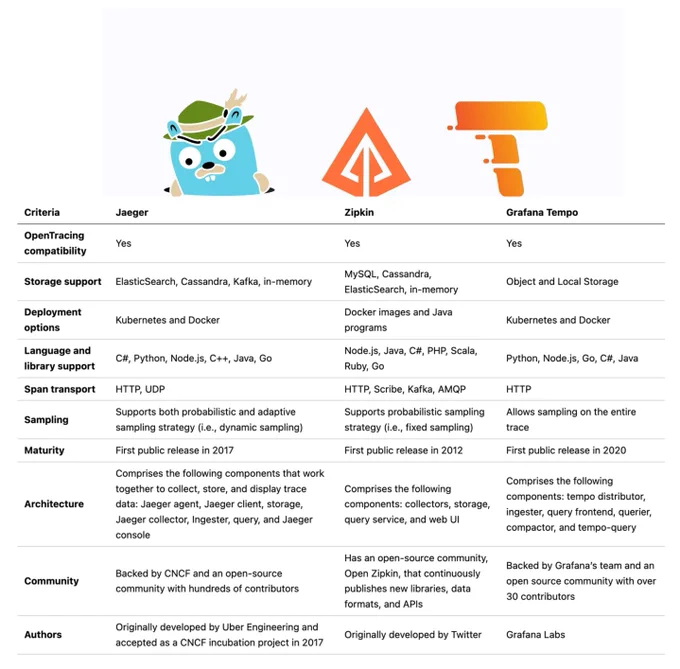
當我們深入了解 Grafana Tempo 的各個組件前,值得一提的是 Grafana Tempo 和 Grafana Loki 甚至是 Grafana Mimit 在組件概念上都展現出了高度的相似性,這種相似性意味著,當我們學習或熟悉了其中一套工具後,將能夠非常迅速和輕松地掌握另一套,並且大幅減輕了我們的維護難度及時間成本。
<bucketname> / <tenantID> / <blockID> / <meta.json>
/ <index>
/ <data>
/ <bloom_0>
/ <bloom_1>
...
/ <bloom_n>
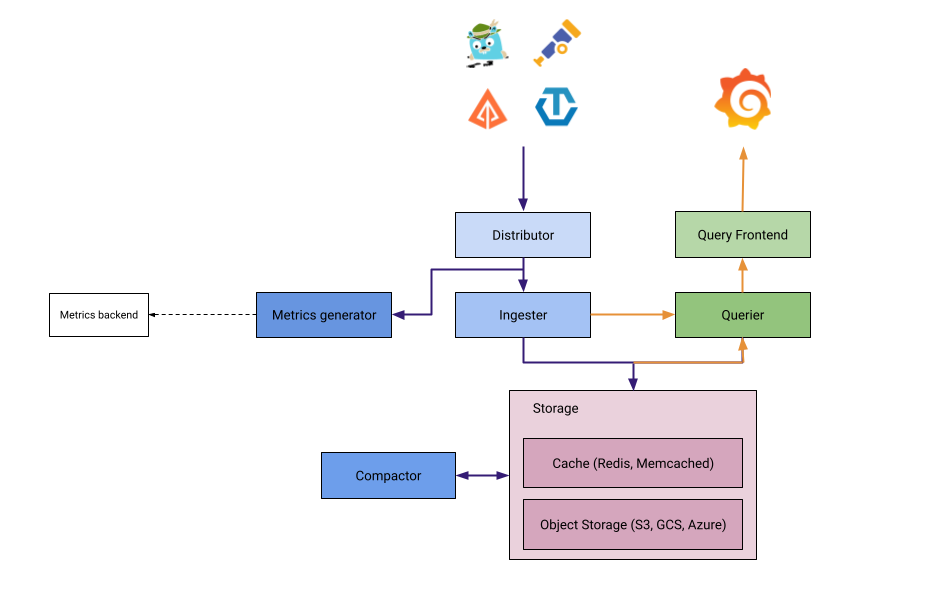
Metrics-generator 是一個可選的 Tempo 元件,它從 Ingester 組件的追蹤數據中產生對應指標。如果存在,Distributor 會將接收到的跨度寫入Ingester 和 Metrics generator。指標產生器使用 Prometheus Remote Write 處理跨度指標並將指標寫入 Prometheus 資料源。我們將隨後對其進行詳細介紹。
服務端指標是一種從將被寫入的指標中額外產生 Metrics 的功能,而 Metrics-generator 組件就是擔任此角色的存在,Distributor 組件會同時將接受到的跨距寫入 Ingester 及 Metrics-generator 中,目的在於使 Metrics-generator 專注於處理生成寫入 Metrics 的分工職責。
Metrics-generator 內部會運作一組 Processor(處理器),每一組處理器都可以透過將被寫入的指標再產生出額外附加價值的 Metrics。
目前,提供的以下處理器可以使用:
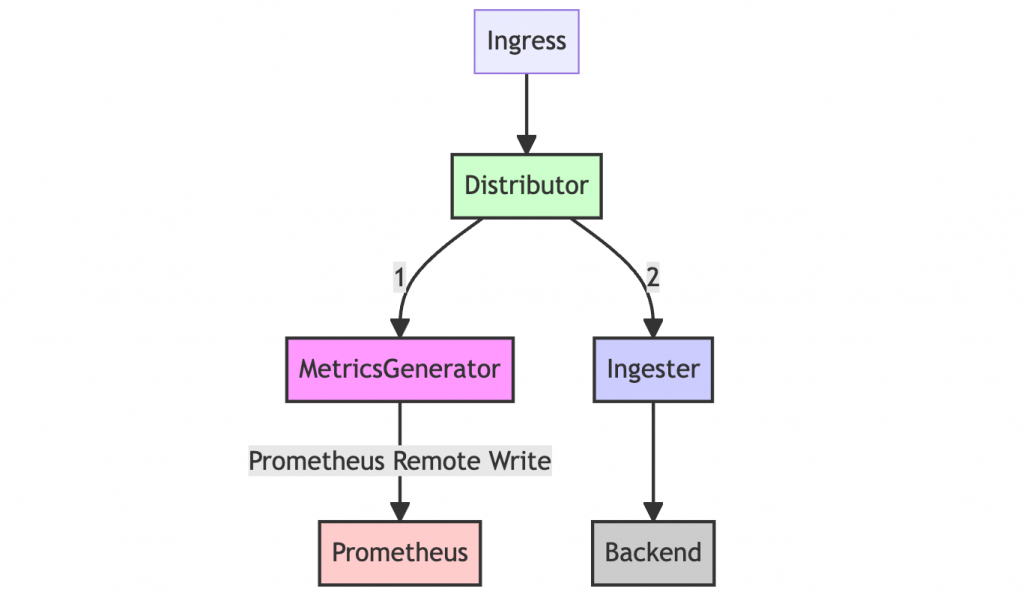
Span Metrics 處理器從接收到的追蹤數據中生成指標,包括請求、錯誤和持續時間(RED)指標。
Span Metrics 會生成兩種指標:
即便我們已有監控指標,Span Metrics 能為系統提供更深入的監控。生成的指標將展示追踪在我們的應用服務中傳播的程度,從而提供對應用層面的洞察。
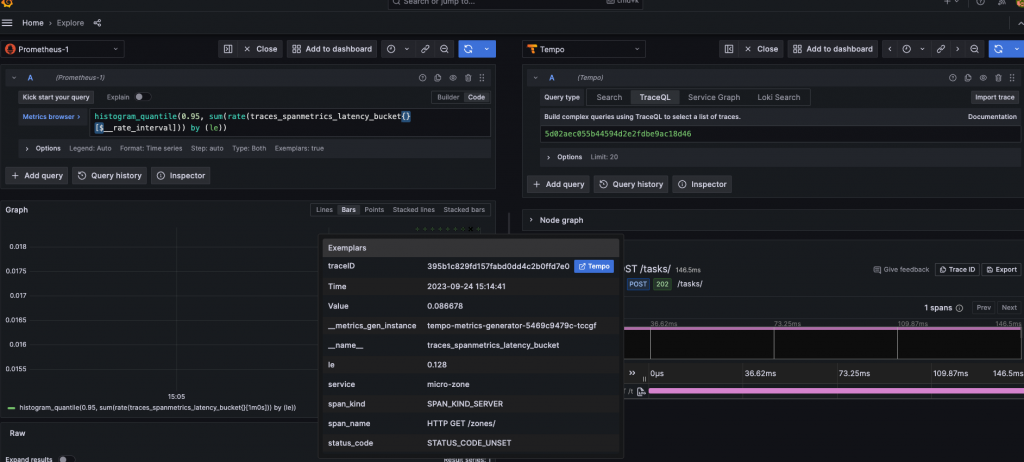
最後,但同樣重要的是,Span Metrics 降低了使用 exemplars 的入門門檻。Exemplar 是在給定時間間隔內進行的測量的具體追踪代表。由於追踪和指標在 Metrics-generator 中共存,因此可以自動添加 exemplars,為這些指標提供額外的價值。
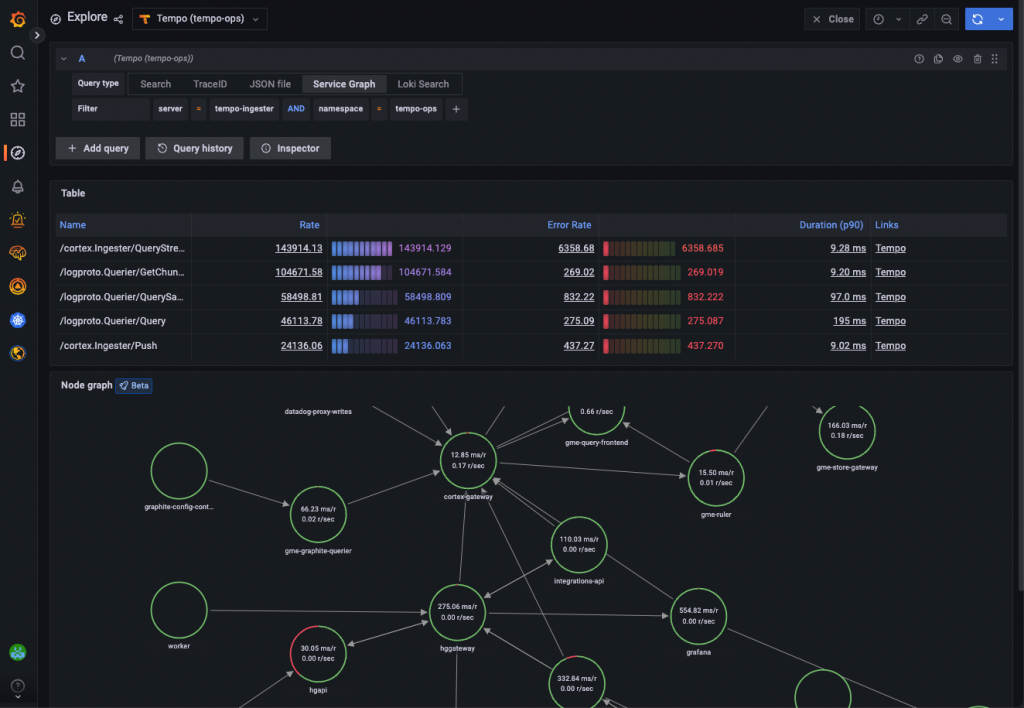
Grafana Tempo 中的 Service Graph 利用由 Metrics-generator(或 Grafana Agent)生成的指標,展示跨度請求率、錯誤率、持續時間以及服務圖。一旦完成設置要求,這個預配置的視圖便立即可用。
通過使用服務圖視圖,我們可以:
在仔細了解 Grafana Tempo 之後,我們可以看到,Grafana 團隊一如既往地帶給我們超乎預期的驚喜。他們不僅解決了現有分佈式追蹤工具在成本上的挑戰,還借鑒了自身的開源工具架構來開發出 Grafana Tempo。更值得一提的是,他們在這個基礎上創建了前所未有的 Metrics generator 概念,更進一步提升了每個追踪信號的價值。
對於一直堅持到現在同學,無論是感受到了耳目一新的啟發,還是覺得學習有些吃力,打起精神!我們現在即將進入實戰演練環節,探索 Grafana Tempo 的神秘面紗!
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day25
