若把BERT視為Transformer Encoder的代表,那麼GPT則可以說是Decoder的最佳代表,不過基於Decoder的模型會有一些小問題存在,而該問題就是它較難以理解語意,不過但在GPT中透過增加模型大小和訓練資料,這種簡單但有效的方式解決這個問題,也因這兩種模型具有完全相反的特性,所以往往被用來進行比較,所以今天我們將重點探討GPT家族在訓練模型時所採用的方法。今天學習重點如下:
GPT的不同版本zero-shot與few-shot
MAML演算法與meta learning的概念GPT-1是在ELMo模型出現一年後誕生的這也是最初的GPT版本,而它之所以會出現,主要是因為傳統的自然語言模型需利用大量數據進行監督式學習以完成預訓練任務,然而這種基於監督式學習的語言模型,不但需要花費大量時間來標註標籤,並且訓練完畢後的模型也無法一次解決所有自然語言處理的任務。
因此GPT-1採用了一種稱為自回歸(Autoregressive)的訓練方式 (x(0)~x(t-1)用來預測x(t)),這是因為對於文字資料來說,當前時間點的起始值會受到先前時間點起始值的影響,因此只需利用過去的幾個時間點的資訊便能預測未來的起始值。
這種概念與我們之前學過的Word2Vec的CBOW相似,唯一的區別在於它是採用單向操作而非CBOW的雙向表示,不過GPT-1採用了12個Transformer Decoder,並充分利用了Transformer的Multi-head Attention特性,因此在語義表達上比Word2Vec更為豐富,而選擇使用Decoder的主要原因在於,因為作者希望透過生成而非分類的方式來完成所有的自然語言任務。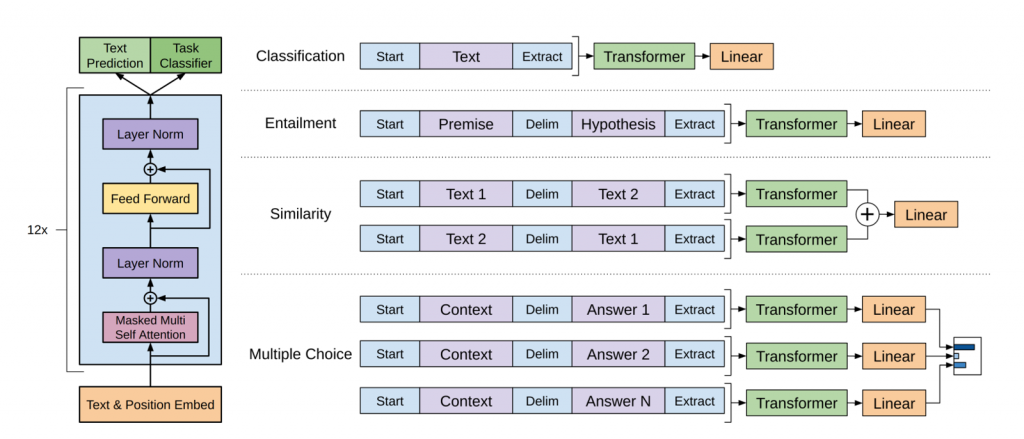
雖然GPT-1的設計讓它成為一個通用模型,但在特定領域的任務處理時仍然是需要微調的,如上圖所示在處理分類(Classification)的任務時,它會在輸出端接上一個線性分類器以進行分類;而第二項Entailment(文字蘊涵)的任務,它需要判斷兩句間的關聯性,這與BERT中的NSP任務有點類似;第三項任務它會進行相似度(Similarity)分析,是透過孿生網路(Siamese networks)的結構比對兩句的輸出並計算其關聯性;最後Multiple Choice任務,它就是我們昨天進行的QA任務,只不過它的作法是將文章內容與問題結合,並將答案視為第二句,因為GPT主要的主要概念是推理,而非跟BERT一樣是分類。
在2018年GPT-1在九項任務中表現卓越成為了該領域的領先模型(state-of-the-art, SOTA),雖然未經微調的GPT-1在各項任務中也顯示出一定的效果,但其在未經微調的任務中的泛化能力遠不及經過微調的有監督任務,因此該模型的的實驗結果可說是不如預期,因它最初的概念就是成為一個全面的語言模型。
GPT-1的模型擁有約1億的參數量,並採用了約5G的BooksCorpus資料集進行訓練,上面我們有提到雖然此方法取得了不錯的效果,但並未滿足GPT的野心。於是GPT-2在模型參數量和資料集的規模上進一步提升,它選用了約15億的參數量(48層的Transformer Decoder)並從Reddit收集了40GB的文本資料進行訓練。
而該模型的出現就是為了驗證GPT-1的理念「只要語言模型的容量和使用的資料量能夠充足,該模型便能適應多元的任務」,而這個理念相當直觀就是把所有的驗證集都都能被當成是訓練集就是GPT-3的核心原理
而經過實驗的結果GPT-2僅透過zero-shot的方式就在八項任務中的七項成為了SOTA模型,然而由於其參數量過大,所以導致在微調上基本上沒有太大的變化,甚至可能出現微調後效能反而降低的情況。
小提示:
「Zero-shot」指的是在輸入模型的文本中,不提供任何參考樣本的方式。例如當我們向模型提出問題:「數字8是多少?」模型需要自行推理出答案,這種方式就是zero-shot。然而如果我們提供一組參考數據,例如「2 4」、「6 8」,這樣子模型推理出的答案可能會更準確,這種方法則稱為「few-shot」。
雖然GPT-2在微調上的表現並未達到理想效果,但它卻證明只要不斷增加資料量與模型大小,便有可能達成通用模型的目標,因此GPT-3直接使用了1750億的模型參數量(當時第二大的模型參數量只有200億),並利用45TB從網路上取得的資料進行訓練,
而在GPT-3這個模型中,它所要完成的目標就是希望透過結合few-shot與zero-shot的概念來解答所有有關於文字的任務。因此它需要使用一種名為元學習(meta learning)的訓練方式,這種學習方式是一種透過學習結果進行學習的方法。
GPT-3則是使用了一種名為MAML(Model-Agnostic Meta-Learning)的元學習策略,該策略的目標是學習一個能夠代表所有任務的meta initialization(元初始化參數),為了學習這個參數,我們需要將每個自然語言任務依照其性質分為support set(支援集)和query set(查詢集)。
在MAML的過程中首先利用支援集來進行內循環(Inner Loop)的訓練,也就是針對每一個獨立任務進行學習,然後模型會進入外循環(Outer Loop)的階段,在此階段中則會檢視內循環得出的學習結果,以此並更新meta initialization,將其結果更新再回到內循環進行訓練,將下來不斷反覆循環到meta initialization不再有所變化時模型就訓練完畢了。
在該論文的圖片中,還介紹了一種名為In-Context Learning(上下文學習)的方法,這指的是在內循環中的每一個支援集的分類方式,所有相似的任務都應該劃分到同一個支援集裡,因為我們在詢問問題時通常是在同一個領域內,透過這種訓練方式,GPT-3能夠根據上下文更精準地回答問題。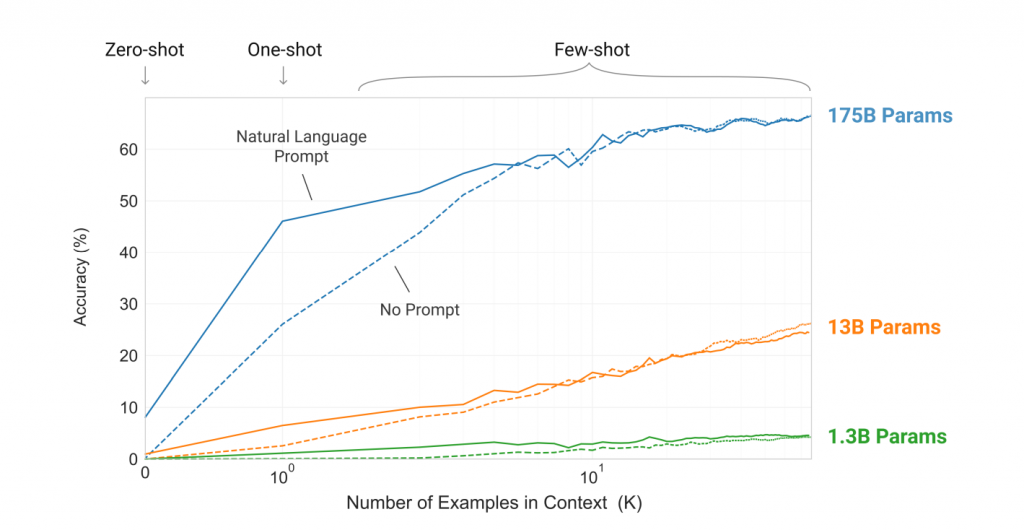
根據GPT-3的實驗結果,證實模型參數量越高,並配合越多的few-shot實際效果將越出色,而在GPT-3的實驗還比較了在有Prompt與無Prompt兩種情境下的效能差異。所謂的Prompt是指在問題開始處加入特定語境設定,例如當我們需要進行翻譯任務時,會輸入翻譯中文到英文:你好,其中的翻譯中文到英文:即是Prompt的一種應用。
GPT-3的效果無疑是2020年中最強的模型,而它與Google所開發的模型之間存在著深深的競爭關係,每當Google開發出新的模型,GPT就會響應著推出更強的模型從時間線上來看ELMo -> GPT1 -> BERT -> GPT2 -> T5 -> GPT3,不過前幾個模型之間的效能相差並不大,但自GPT-3誕生之後則遠遠超過了先前的模型。但GPT-3並未開源且在模型訓練上較困難,因此多數企業仍選擇使用BERT作為語言模型。
現在你應該能理解為何這篇文章的標題是「用暴力美學屹立於不敗之地」了吧!這種需要大量訓練的模型已變成現在自然語言處理的主流,他們被統稱為大型語言模型(Large Language Model, LLM),當然要建立出這類的模型還是依賴於我們先前所學習的所有技術。明天我將會透過GPT-J來教你如何微調只有Decoder架構的模型。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days

