而且提供 anyscale/aviary Docker image,pip install,或是 Ray Cluster 的方式來使用。
上一片介紹 LLMs on Ray 的幾種方式,這篇來是試試看吧。
就先照 Locally 試試看。
$ cache_dir=${XDG_CACHE_HOME:-$HOME/.cache}
$ docker run -it --gpus all --shm-size 1g -p 8000:8000 -e HF_HOME=~/data -v $cache_dir:~/data anyscale/aviary:latest bash
docker: Error response from daemon: invalid volume specification: '/home/ubuntu/.cache:~/data': invalid mount config for type "bind": invalid mount path: '~/data' mount path must be absolute.
See 'docker run --help'.
照著錯誤訊息重新設定 mount volume 語法。
$ docker run -it --gpus all --shm-size 1g -p 8000:8000 -e HF_HOME=~/data -v $cache_dir:/home/ubuntu/data anyscale/aviary:latest bash
==========
== CUDA ==
==========
CUDA Version 11.8.0
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
(base) ray@d6c43bb5bdfa:~$
照預設的 amazon--LightGPT.yaml 跑看看。
$ aviary run --model ~/models/continuous_batching/amazon--LightGPT.yaml
[WARNING 2023-10-12 01:34:46,218] api.py: 382 DeprecationWarning: `route_prefix` in `@serve.deployment` has been deprecated. To specify a route prefix for an application, pass it into `serve.run` instead.
[INFO 2023-10-12 01:34:48,538] accelerator.py: 216 Unable to poll TPU GCE metadata: HTTPConnectionPool(host='metadata.google.internal', port=80): Max retries exceeded with url: /computeMetadata/v1/instance/attributes/accelerator-type (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f4d21231250>: Failed to establish a new connection: [Errno -2] Name or service not known'))
[INFO 2023-10-12 01:34:48,540] accelerator.py: 171 Failed to detect number of TPUs: [Errno 2] No such file or directory: '/dev/vfio'
2023-10-12 01:34:48,543 WARNING services.py:1889 -- WARNING: The object store is using /tmp instead of /dev/shm because /dev/shm has only 1073741824 bytes available. This will harm performance! You may be able to free up space by deleting files in /dev/shm. If you are inside a Docker container, you can increase /dev/shm size by passing '--shm-size=5.01gb' to 'docker run' (or add it to the run_options list in a Ray cluster config). Make sure to set this to more than 30% of available RAM.
2023-10-12 01:34:49,729 INFO worker.py:1633 -- Started a local Ray instance. View the dashboard at 127.0.0.1:8265
[INFO 2023-10-12 01:34:50,909] api.py: 148 Nothing to shut down. There's no Serve application running on this Ray cluster.
[INFO 2023-10-12 01:34:50,998] deployment_base_client.py: 28 Initialized with base handles {'amazon/LightGPT': <ray.serve.deployment.Application object at 0x7f4d20f532b0>}
/home/ray/anaconda3/lib/python3.9/site-packages/ray/serve/api.py:519: UserWarning: Specifying host and port in `serve.run` is deprecated and will be removed in a future version. To specify custom HTTP options, use `serve.start`.
warnings.warn(
(HTTPProxyActor pid=788) INFO 2023-10-12 01:34:53,383 http_proxy 172.17.0.2 http_proxy.py:1428 - Proxy actor e30f062d1fd26c00612a158f01000000 starting on node 088dc3f0e1008053c151afc928afbc3b49647782954c27d248d65bdc.
(HTTPProxyActor pid=788) INFO 2023-10-12 01:34:53,402 http_proxy 172.17.0.2 http_proxy.py:1612 - Starting HTTP server on node: 088dc3f0e1008053c151afc928afbc3b49647782954c27d248d65bdc listening on port 8000
(HTTPProxyActor pid=788) INFO: Started server process [788]
[INFO 2023-10-12 01:34:53,468] api.py: 328 Started detached Serve instance in namespace "serve".
(ServeController pid=753) INFO 2023-10-12 01:34:53,634 controller 753 deployment_state.py:1390 - Deploying new version of deployment VLLMDeployment:amazon--LightGPT in application 'router'.
(ServeController pid=753) INFO 2023-10-12 01:34:53,638 controller 753 deployment_state.py:1390 - Deploying new version of deployment Router in application 'router'.
(ServeController pid=753) INFO 2023-10-12 01:34:53,743 controller 753 deployment_state.py:1679 - Adding 1 replica to deployment VLLMDeployment:amazon--LightGPT in application 'router'.
(ServeController pid=753) INFO 2023-10-12 01:34:53,753 controller 753 deployment_state.py:1679 - Adding 2 replicas to deployment Router in application 'router'.
(autoscaler +17s) Tip: use `ray status` to view detailed cluster status. To disable these messages, set RAY_SCHEDULER_EVENTS=0.
看起來好像正常,不過...
(ServeController pid=753) WARNING 2023-10-12 01:38:54,288 controller 753 deployment_state.py:1987 - Deployment 'VLLMDeployment:amazon--LightGPT' in application 'router' has 1 replicas that have taken more than 30s to be scheduled. This may be due to waiting for the cluster to auto-scale or for a runtime environment to be installed. Resources required for each replica: [{"CPU": 1.0, "accelerator_type_a10": 0.01}, {"accelerator_type_a10": 0.01, "GPU": 1.0, "CPU": 8.0}], total resources available: {}. Use `ray status` for more details.
(autoscaler +4m23s) Error: No available node types can fulfill resource request defaultdict(<class 'float'>, {'CPU': 9.0, 'accelerator_type_a10': 0.02, 'GPU': 1.0}). Add suitable node types to this cluster to resolve this issue.
先來看看 ray status。
$ docker exec -it d6c43bb5bdfa bash
(base) ray@d6c43bb5bdfa:~$ ray status
======== Autoscaler status: 2023-10-12 01:45:44.792184 ========
Node status
---------------------------------------------------------------
Healthy:
1 node_088dc3f0e1008053c151afc928afbc3b49647782954c27d248d65bdc
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
2.0/16.0 CPU
0.0/1.0 GPU
0B/9.11GiB memory
44B/4.56GiB object_store_memory
Demands:
{'CPU': 1.0, 'accelerator_type_a10': 0.01}: 1+ pending tasks/actors (1+ using placement groups)
{'accelerator_type_a10': 0.01, 'CPU': 1.0} * 1, {'GPU': 1.0, 'accelerator_type_a10': 0.01, 'CPU': 8.0} * 1 (STRICT_PACK): 1+ pending placement groups
檢查一下 container 的 GPU 資訊。
$ docker exec -it d6c43bb5bdfa nvidia-smi
Thu Oct 12 01:45:34 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 535.113.01 Driver Version: 535.113.01 CUDA Version: 12.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla P4 Off | 00000000:00:06.0 Off | 0 |
| N/A 35C P8 6W / 75W | 0MiB / 7680MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
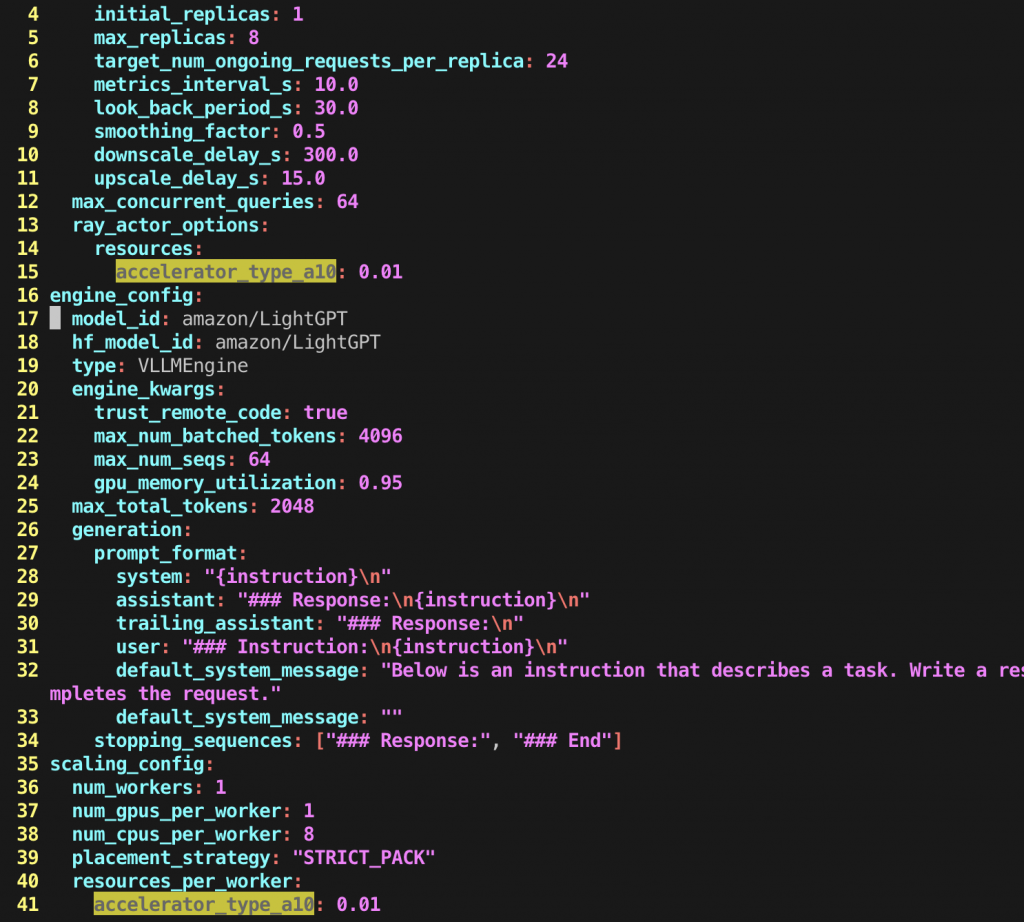
看來需要根據目前機器調整 amazon--LightGPT.yaml 有關 GPU 的部分。
scaling_config:
num_workers: 1
num_gpus_per_worker: 1
num_cpus_per_worker: 8
placement_strategy: "STRICT_PACK"
resources_per_worker:
accelerator_type_a10: 0.01
另外,deployment_config 也要調整。
deployment_config:
ray_actor_options:
resources:
accelerator_type_a10: 0.01
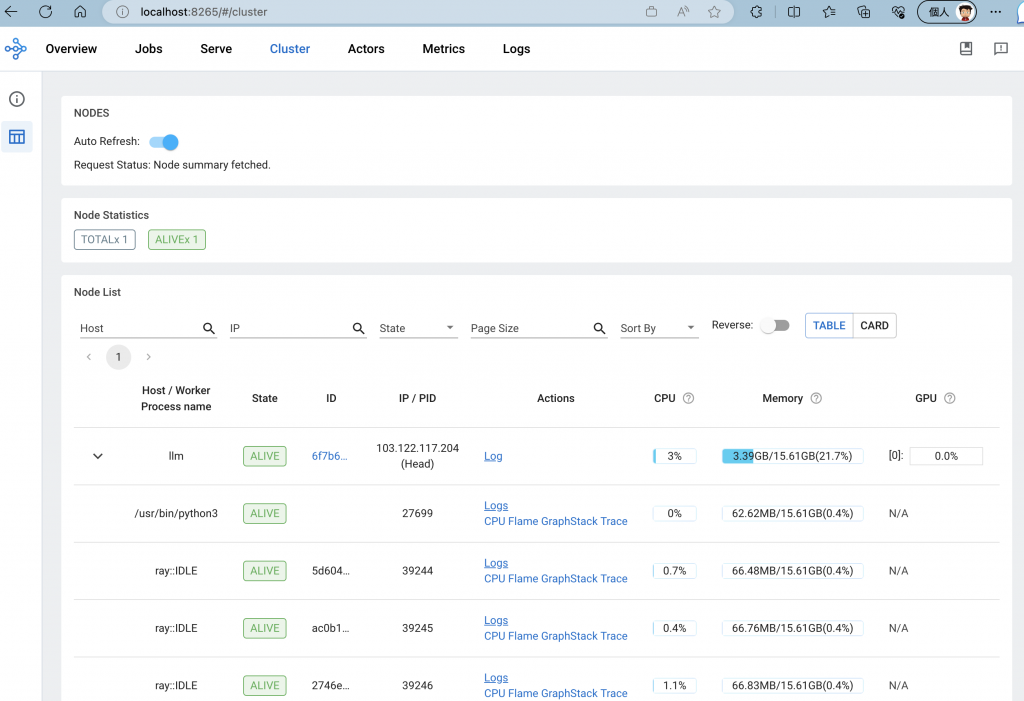
透過 ssh tunnel ,檢視一下 Ray Dashboard。
Reference:

