在 Reference 的這篇文章 提到兩個經典的 deployment patterns,在鐵人賽即將結束時,重新檢視一下。
模型是由程式碼建立的,但是產生的模型 artifacts 和建立它們的程式碼可以非同步的運作。也就是說,新的模型版本和程式碼變更可能不會同時發生。例如,考慮以下情況:
為了偵測詐欺交易,你開發了一個 ML pipeline,每週重新訓練一個模型。程式碼可能不會經常變更,但是模型可能每週重新訓練一次,以納入新的資料。
你可能會建立一個大型的深度神經網路來分類文件。在這種情況下,訓練模型是計算密集型和耗時的,重新訓練模型可能不會經常發生。但是,部署、服務和監控此模型的程式碼可以在不重新訓練模型的情況下更新。
這兩種 patterns 的差異在於模型 artifacts 或是產生模型 artifacts 的訓練程式碼,哪一個會被推上 production。
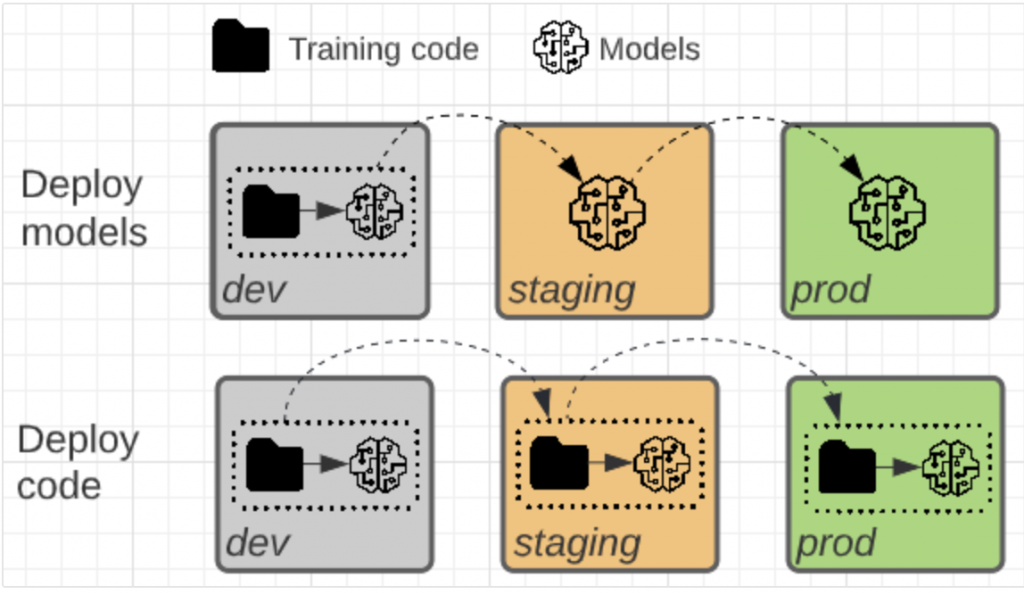
將有關 model training (or workflow) 相關的程式碼作佈署。好處有:
以公司組織面來看,production data 的存取權限受到限制,這個 pattern 允許讓模型在 production data 上訓練。
自動化的模型重新訓練更安全,因為訓練程式碼是經過審查、測試和核准的。
支援程式碼遵循相同的模式,模型訓練程式碼也是如此。兩者都會在 staging 環境中進行整合測試。
缺點:
Reference:

