
Python爬蟲是指使用Python程式語言來從網頁上抓取資料的技術。這個過程涉及發送請求到網站,獲取網頁內容,然後解析這些內容以提取有用的資訊。以下是Python爬蟲的一些關鍵點和常用的工具:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 提取數據的例子
for heading in soup.find_all('h1'):
print(heading.text)

網站的HTML(超文本標記語言)是用於建立和設計網頁的標準標記語言。它使用各種標籤來定義網頁的結構和內容。下面是一些基本的HTML元素和它們的功能:
<!DOCTYPE html>:聲明文檔類型,告訴瀏覽器這是一個HTML5文檔。<html>:這個標籤包圍了整個HTML文檔的所有內容。<head>:包含了文檔的元數據,如標題、鏈接到樣式表和腳本的引用。<title>:定義了網頁的標題,這個標題會顯示在瀏覽器的標籤欄中。<body>:包含了網頁的主要可見內容,如文本、圖片、連結、列表等。<h1> 到 <h6>:這些是標題標籤,用於定義文檔中的標題。<h1> 是最高級別的標題。<p>:段落標籤,用於定義文本的段落。<a>:錨點標籤,用於創建超鏈接。<img>:圖片標籤,用於在網頁上嵌入圖片。<ul>、<ol>、<li>:分別用於創建無序列表、有序列表和列表項目。這些只是HTML中的一些基本元素。HTML能夠與CSS(層疊樣式表)和JavaScript程式一起工作,創建更復雜和動態的網頁。
一個基礎的HTML網頁範例包含了標準的結構元素,如下所示:
<!DOCTYPE html>
<html>
<head>
<title>我的網頁標題</title>
</head>
<body>
<h1>我的第一個標題</h1>
<p>我的第一段文字。</p>
</body>
</html>
這個範例解釋如下:
<!DOCTYPE html>:宣告文檔類型,告訴瀏覽器這是一個HTML5文檔。<html>:HTML文檔的根元素。<head>:包含了文檔的元數據(metadata),如標題、字符集等。
<title>:設定網頁標題,會顯示在瀏覽器的標籤上。<body>:包含了網頁的可見內容。
<h1>:一個主標題。<p>:一段文字。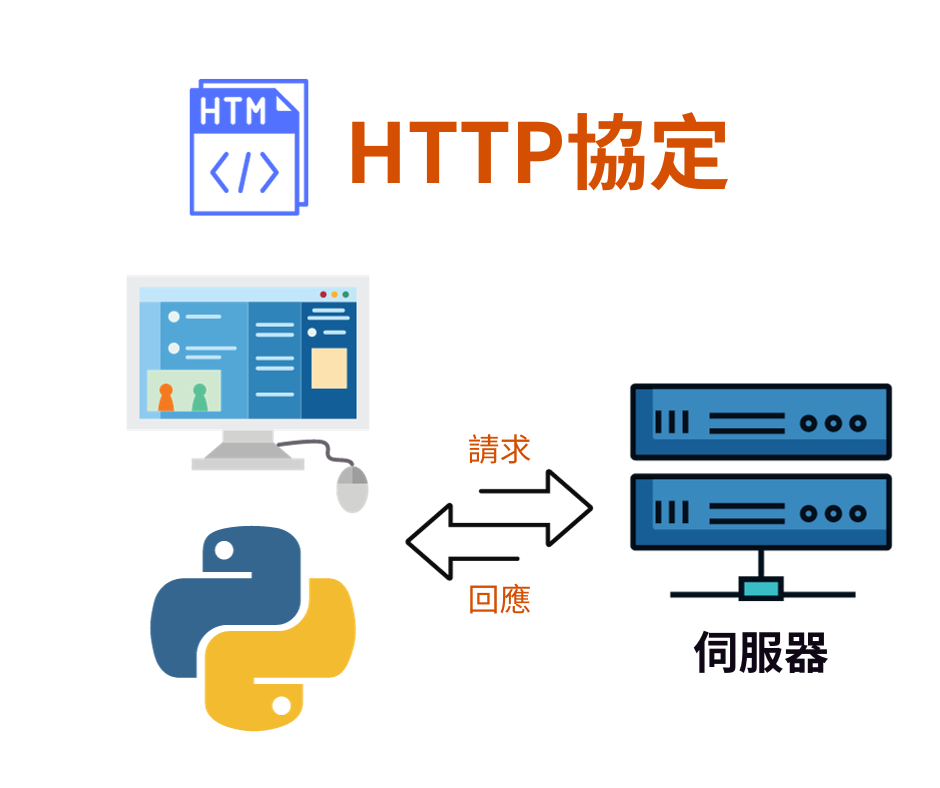
HTTP(超文本傳輸協議)是一種用於傳輸超媒體文件(如HTML)的應用層協議,是網際網路上數據交換的基礎。它遵循客戶端-服務器模型,其中瀏覽器通常充當客戶端,而網站則是服務器。
HTTP通訊的基本過程如下:
HTTP協議是網際網路日常操作的核心部分,支撐著現代網絡應用的大多數功能。隨著技術的發展,HTTP/2和HTTP/3等新版本的協議被引入,進一步提高了性能和效率。
網路爬蟲是一種廣泛應用於數據收集的工具。在這方面,Python擁有眾多易於使用的第三方套件,能夠快速實現功能開發。然而,在著手編寫爬蟲程式之前,首先需要對目標網站的架構進行詳細分析。這一過程中,對網站的基本知識,特別是HTML結構與HTTP通訊協定的理解,成為了關鍵的學習要點。了解這些基礎知識對於實現有效且穩定的網路爬蟲程式至關重要。
分享所學貢獻社會
[Python教學]開發工具介紹
[開發工具] Google Colab 介紹
[Python教學] 資料型態
[Python教學] if判斷式
[Python教學] List 清單 和 Tuple元組
[Python教學] for 和 while 迴圈
[Python教學] Dictionary 字典 和 Set 集合
[Python教學] Function函示
[Python教學] Class 類別
[Python教學] 例外處理
[Python教學] 檔案存取
[Python教學] 實作密碼產生器
[Python教學] 日期時間
[Python教學] 套件管理
最後最後有一件小小的請求,請大家幫我填寫一下問卷,
讓我們知道你想上怎麼樣課程,感激不盡。
問卷這邊
Facebook 粉絲頁 - TechMasters 工程師養成記
 pellok
pellok
