雖然電腦的處理速度很快,但如果 DB 中的資料越來越多,查詢所花費的時間依然會增長。因此,我們可以建立索引,供 DB 在查詢時參考,藉此提升效率。
本文會介紹索引的概念、原理,以及相關的資料結構。閱讀前,建議讀者至少需要知道「二元搜尋樹」和「樹的平衡」是什麼,才比較容易看懂喔!
此篇亦轉載到個人部落格。
先以生活情境來想像,假設讀者在超市尋找一款已知名稱的沐浴乳。則可能有以下的尋找方式:
由以上的例子可看出,第 1 種方式的效率最差,甚至如果根本沒有這款沐浴乳,那就意味著浪費大量的時間。而第 3 種方式的效率最好,可以先快速定位出沐浴乳大概在什麼地方,同時縮小尋找範圍。
讓我們回到資料庫索引的話題。索引是一種可以增進查詢效率的資料結構,其內容會指向 DB 的原始資料。此外,由於索引中的內容是經過排序的,因此底層原理上會搭配演算法,使讓 DB 更快地定位出資料的位置。
讀者可以想像一下,如果超市的貨架上方有掛牌,依照順序寫著「1. 飲料」、「2. 寵物食品」、「3. 個人清潔」、「4. 居家清潔」。當店員告訴我們沐浴乳在 3 號貨架,這樣尋找起來不是快速多了嗎?
假設我們有下的員工資料表。
| emp_id | name | age |
|---|---|---|
| 1 | 小紅 | 31 |
| 2 | 小橙 | 28 |
| 3 | 小黃 | 39 |
| 4 | 小綠 | 22 |
| 5 | 小蘭 | 35 |
| 6 | 小青 | 28 |
| 7 | 小紫 | 41 |
如果想查詢年齡為 28 的員工,語法如下。
SELECT * FROM `employee` WHERE `age` = 28;
在沒有建立索引的情況下,此時 DB 將從第一筆資料開始比對,首先將「小橙」納入查詢結果。但還沒結束,要一直比對到最後一筆,才代表看完所有資料了。這種現象稱為「全表掃描」,效率最差。
索引是如何提升查詢效率呢?這就牽涉到「資料結構」的領域了。索引使用「樹狀結構」來儲存經過排序後的資料。而排序的依據是資料的欄位值,例如編號、年齡或薪水等。
剛認識索引的讀者,可以用相對簡單的「二元搜尋樹」(Binary Search Tree,BST)來幫助思考。索引中的每個樹節點,除了紀錄資料的排序欄位值,也會包含原始資料的位置。
binary-search-tree.png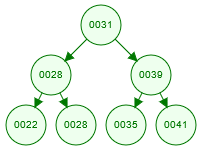
從上圖的 BST,可看出任一樹節點的左子樹,值都小於自己,右子樹則大於等於自己。
又因為樹狀結構中的資料是經過排序的,因此無論是查詢速度或針對結果做排序,效率都比全表掃描更高。不過 DB 底層並非使用 BST,此處是為了方便讀者理解,才這麼舉例。
至於索引所帶來的缺點,是會額外佔用硬碟空間。此外,對資料表進行寫入操作(增、刪、改)時,DB 需要去維護索引內容。
然而我們不必太在意這些副作用,畢竟增加硬碟空間並不難。且在應用程式中,通常希望查詢快一點,而可以接受寫入慢一點,畢竟前者較頻繁發生。
本節筆者將針對各種樹狀結構進行比較,藉此說明為何資料庫最常採用「B+Tree」資料結構來實作索引。
以二元搜尋樹為例子。首先,由於插入資料時,並不能保證樹是「平衡」的,因此最糟的情況是長得像鏈結串列,導致趨近於全表掃描。
skewed-binary-search-tree.png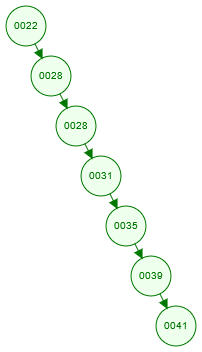
再者,每個樹節點最多只有兩個子節點,一旦資料量太多,樹就會長得很高,使得查詢效率的提升越來越有限。
接著以紅黑樹為例,這是一種會盡可能維持平衡的樹狀結構。但它本身仍是一種二元搜尋樹,同樣存在上述樹太高的問題。
red-black-tree-not-exactly-balance.png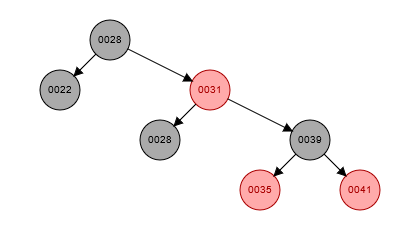
最後是「B+tree」,它可以比二元樹擁有更多的子節點,任由我們定義。因此當資料量一樣多,B+tree 反而較矮,使得搜尋速度更快。此外也具備保持平衡的特色。
b-plus-tree.png
其實 B+tree 是基於「B-tree」做了優化。兩種樹的差異在於,後者的資料是分布在樹的各個節點。而前者是將實際資料都存放在葉節點。對 B+tree 而言,其他節點只是用於搜尋葉節點時,判斷行進方向而已。
從上面的 B+tree 示意圖還可看到,左邊的葉節點會用一個指標連接上右邊的葉節點,形成類似鏈結串列的樣子。而 MySQL 又進一步將右邊葉節點連回去左邊葉節點,形成有順序的「雙向鏈結串列」。這樣的設計,有利於 DB 執行範圍條件的查詢(例如年齡 28 ~ 35 的員工)。
想更加了解的讀者,可參考以下影片的介紹。
在我們建立資料表時,MySQL 本身就會默默地自動建立索引。主要分成叢集索引(clustered index)與次級索引(secondary index)兩種。
本節內容參考自此影片。
叢集索引是資料表實際資料內容的存放之處,每張表必須而且只能有一個。我們知道在樹狀結構中,每個節點都有一個「key」來做為代表。在索引的應用中,節點 key 的產生方式,是按照以下的順位。
PRIMARY KEY 語法修飾。UNIQUE 語法修飾。如果有多個,則採用第一個。以下是叢集索引樹狀結構的示意圖。
clustered-index-tree.png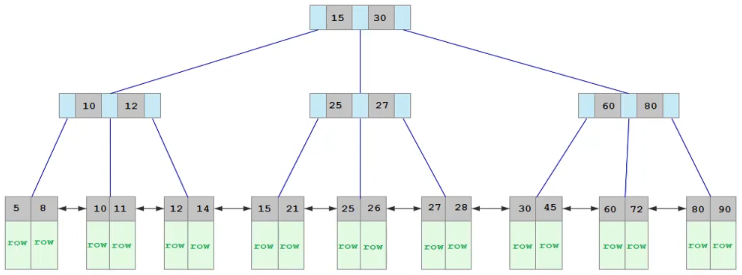
次級索引是我們針對自己想要的欄位去建立,故一張資料表可能有多個。在樹狀結構中,葉節點的 key 將會是欄位值(例如年齡、部門編號),而葉節點的資料則是叢集索引的樹節點 key。
為了方便說明,筆者假設資料表設有主鍵,所以叢集索引樹節點的 key 就是主鍵值。以下是次級索引樹狀結構的示意圖。
secondary-index-tree.png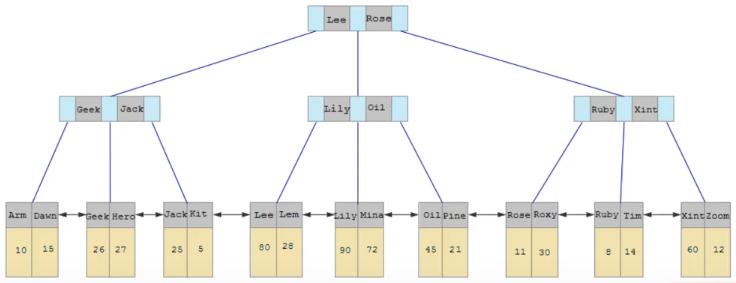
當我們想查詢名字為「Jack」的員工資料,DB 會從次級索引尋找符合條件的資料的主鍵。再到叢集索引找出那些資料的實際內容,最後回傳結果。這個步驟稱為「回表查詢」。
今日文章到此結束!
最後宣傳一下自己的部落格,我是「新手工程師的程式教室」的作者,主要發表後端相關文章,請多指教

