Day 5 - 機器學習的開始 - 資料蒐集與整理
蒐集資料
機器學習不同於人類學習,通常需要大量的資料來進行訓練。特別是近年來流行的深度學習技術,僅僅是辨認物件可能就需要數百萬張圖片才能達到高準確率。
資料來源
-
自行蒐集:
- 對於涉及人類行為的研究,最傳統的方法是進行問卷調查。
- 若研究對象不是人類,則可以使用物聯網(IoT)設備進行資料蒐集。
-
公開資料庫:
-
公司內部資料:
- 使用公司內部的資料,這些資料通常因隱私問題無法公開,但如果你是該公司的成員,則可以使用這些資料。
數據補遺
數據遺失是常見的問題,可能是因為儀器失靈或資料蒐集不仔細等原因造成的。
補遺方法
-
時間序列資料:
- 使用內插或外插法:
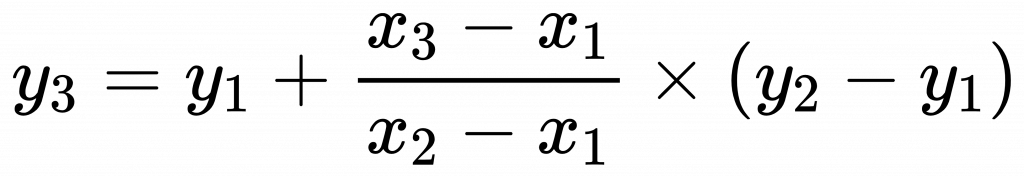
-
其他資料:
- 使用平均數或中位數來填補。
- 如果資料量足夠,可以直接捨棄缺失資料。
資料正規
資料在以下幾種情況下需要正規化:
-
資料非數字:
- 電腦只能處理數字資料,因此需要將非數字資料轉換為數字。
-
資料間物理意義不同:
- 例如氣溫與濕度,雖然都是數字,但範圍不同(氣溫可能是-50到50,濕度是0到100)。
正規化方法
- 將資料轉換為0到1或-1到1之間。
- 使用One-hot Encoding方法處理非數字資料:
{1, 0, 0, 0, 0, ...}
數據異常
數據異常也是常見問題,例如某一天的氣溫突然出現100度。這種情況下一般會刪除該筆異常數據。
異常處理方法
- 使用去頭去尾法,通常採用標準差來篩選數據。
- 假設數據呈現高斯分布,刪除2到2.5個標準差以外的數據。
數據洩漏
數據洩漏是指資料與結果高度相關,但在實際應用中卻沒有意義。例如,使用是否服用抗生素來預測肺炎,因為得到肺炎後通常會服用抗生素。
處理方法
- 如果模型準確率高得不合理,可能存在數據洩漏。
- 檢查是否存在洩漏特徵,若有則刪除。


 iThome鐵人賽
iThome鐵人賽