今天要介紹的是另一個主流的LLM開發框架LlamaIndex,
有沒有人也很常看到這隻草尼馬出現在各種技術架構圖上呢!
今天就讓我們來簡單介紹一下它,並且與它跟LangChain做比較
並說明為何最後我們會選擇使用LangChain 作為我們的Framework吧!
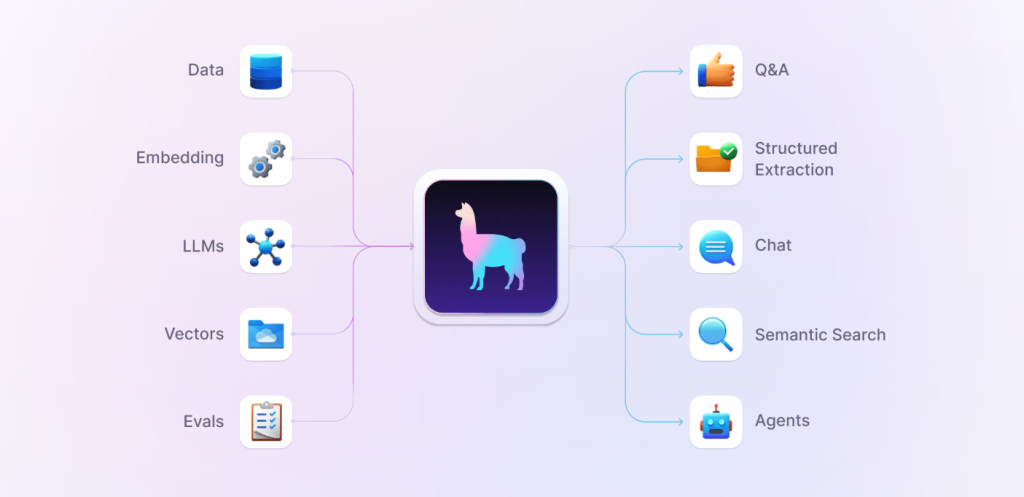
LlamaIndex(以前稱為GPT Index)專注於簡化資料檢索和處理,特別是在構建基於LLM的應用時。它提供了一個高效的索引結構,能夠快速查找和檢索資料,這對於需要大量資料支持的應用場景尤為重要。LlamaIndex的主要特點包括:
安裝核心LlamaIndex可再自行添加需要的LlamaIndex(在LlamaHub上有超過300個LlamaIndex集成包),這些即可無縫與core一起工作,允許自由選擇使用LLM、embedding和vector DB的地方。
LlamaHub 開源專案: https://llamahub.ai/
# 安裝LlamaIndex核心包
pip install llama-index-core
# 安裝OpenAI LLM集成包
pip install llama-index-llms-openai
# 安裝Replicate LLM集成包
pip install llama-index-llms-replicate
# 安裝HuggingFace嵌入模型集成包
pip install llama-index-embeddings-huggingface
這些命令分別安裝了LlamaIndex的核心包和幾個常用的集成包,這些包就可以使用不同的LLM(如OpenAI和Replicate)以及嵌入模型(如HuggingFace)。
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
這行代碼設置了OpenAI API金鑰,將其存儲在環境變量OPENAI_API_KEY中,用於身份驗證。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
這行代碼從LlamaIndex的核心包中導入了VectorStoreIndex和SimpleDirectoryReader類。
documents = SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data()
index = VectorStoreIndex.from_documents(documents)
SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data():從指定的目錄加載數據,返回一個文檔列表。VectorStoreIndex.from_documents(documents):從加載的文檔創建一個向量存儲索引。import os
os.environ["REPLICATE_API_TOKEN"] = "YOUR_REPLICATE_API_TOKEN"
這行代碼設置了Replicate API金鑰,將其存儲在環境變量REPLICATE_API_TOKEN中,用於身份驗證。
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.replicate import Replicate
from transformers import AutoTokenizer
這些代碼從LlamaIndex的核心包和集成包中導入了相關類和函數,用於設置LLM和嵌入模型。
llama2_7b_chat = "meta/llama-2-7b-chat:8e6975e5ed6174911a6ff3d60540dfd4844201974602551e10e9e87ab143d81e"
Settings.llm = Replicate(
model=llama2_7b_chat,
temperature=0.01,
additional_kwargs={"top_p": 1, "max_new_tokens": 300},
)
llama2_7b_chat:設置了Llama 2的模型標識。Settings.llm = Replicate(...):設置Replicate LLM,指定模型和相關參數。Settings.tokenizer = AutoTokenizer.from_pretrained(
"NousResearch/Llama-2-7b-chat-hf"
)
這行代碼從HuggingFace模型庫中加載與LLM匹配的tokenizer。
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
這行代碼設置了HuggingFace嵌入模型。
documents = SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data()
index = VectorStoreIndex.from_documents(documents)
與使用OpenAI時的步驟相同,這些代碼加載數據並創建向量存儲索引。
query_engine = index.as_query_engine()
response = query_engine.query("YOUR_QUESTION")
print(response)
index.as_query_engine():將索引轉換為查詢引擎。query_engine.query("YOUR_QUESTION"):執行查詢並獲取響應。現在大家對於LlamaIndex應該有了初步的了解,
最後再次與前面的LangChain來做個比較
| 比較項目 | LangChain | LlamaIndex |
|---|---|---|
| 特點 | - 多模塊集成 | - 數據索引和查詢 |
| - 上下文管理 | - 高效檢索 | |
| - workflow自動化 | - 自然語言查詢 | |
| 適用場景 | - 構建agent chatbot和對話系統 | - 對大規模數據進行索引和智能檢索 |
| - 整合多種data source進行複雜查詢 | - 構建需要自然語言查詢的數據檢索系統 | |
| - 構建需要上下文管理的應用程序 | - 集成多種數據源進行統一查詢 | |
| 主要功能 | - 支持多種LLM、數據源、工具和API的集成 | - 文檔存儲庫 |
| - 上下文狀態保持和多輪對話支持 | - 索引器 | |
| - 自動化工作流程定義和管理 | - 查詢引擎 |
考量到LangChain的優勢:
我們自家開發還是以LangChain為主,
(身邊認識的企業朋友,有在做RAG的,聽到的似乎也都用LangChain居多)
就依照情況自行評估使用的框架囉!
接下來就要開始談談LangChain語法囉
請持續關注:)


 iThome鐵人賽
iThome鐵人賽