
Paper link | Note link | Code link | NeurIPS 2022
這項研究旨在使用語言模型作為代理,以預測強化學習任務中的下一個行動。
此外,他們還設計了一種數據收集方法,用於在探索過程中收集數據。
預訓練語言模型(PLMs)在處理各種語言處理任務方面具有高度的多功能性。
本研究旨在利用 PLMs 來解決一般的序列決策問題。
在這種方法中,將目標和觀察表示為嵌入序列,並使用預訓練語言模型初始化的策略網絡來預測下一個行動。
語言模型(LMs)能夠處理各種任務,例如:
本研究提出了一個有趣的問題:
即使是那些完全不涉及語言的任務,語言模型是否也能作為通用框架來使用?
本研究提出了 Pre-Trained Language Models for Interactive Decision-Making (LID),一個使用預訓練語言模型進行互動決策的框架。
此外,研究還引入了一種主動數據收集(ADG)程序到預訓練語言模型中,以解決專家數據不易獲得的挑戰。在這種情況下,代理必須主動收集自己的數據。
在深入了解方法之前,理解決策制定和語言建模的概念非常重要。
部分可觀察馬可夫決策過程(POMDPs)由以下組件定義:
狀態集:這些表示代理可能處於的不同條件或情況。
觀察集:這些是代理接收到的信號或數據,提供關於當前狀態的部分信息。
行動集:這些是代理可以根據觀察做出的決策或行動。
轉移模型:表示為 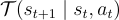 ,這是一個概率分佈,定義了在執行行動
,這是一個概率分佈,定義了在執行行動 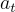 的情況下從狀態
的情況下從狀態 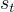 轉移到狀態
轉移到狀態 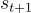 的可能性。
的可能性。
在他們的策略中,使用了表示為 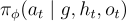 的參數模型,這些模型輸出在給定目標
的參數模型,這些模型輸出在給定目標 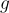 的情況下選擇行動
的情況下選擇行動 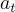 的概率。這裡:
的概率。這裡:
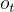 代表當前觀察。
代表當前觀察。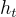 指的是歷史訊息,包括所有截至時間
指的是歷史訊息,包括所有截至時間 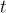 的過去觀察和行動,具體為
的過去觀察和行動,具體為 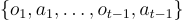 。
。
提出的方法可以總結如下:
序列轉換:所有政策輸入,包括目標、觀察和歷史,均轉換為序列,並作為輸入提供給 Transformer 編碼器。
行動預測:編碼器生成的表示將傳遞給任務專用的解碼器,該解碼器預測行動。
該程序的數據由 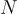 條訓練軌跡組成,表示為
條訓練軌跡組成,表示為 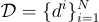 ,其中每條軌跡
,其中每條軌跡 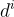 定義為
定義為 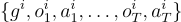 ,
,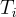 為軌跡的長度。
為軌跡的長度。
用於訓練模型的損失函數定義為:
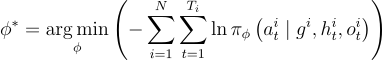
這個損失函數旨在通過最小化所有訓練軌跡中給定目標、歷史和觀察的行動的負對數似然來優化模型參數 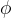 。
。
本研究中使用的語言模型是自回歸的並基於 Transformer 的。這些模型訓練以擬合文本序列 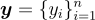 上的概率分佈,使用鏈式法則:
上的概率分佈,使用鏈式法則:
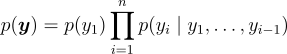
在這個框架中,序列中的每個單詞或標記是基於所有先前的標記來預測的。本研究中使用的模型是 GPT-2,auto-regressive Transformer-based 的語言模型。

在數據收集方面,這種方法涉及迭代重複探索、事後重新標註和策略更新的過程。
結合主動數據收集,它能夠在不依賴預先收集的專家數據的情況下學習有效的策略。
下表顯示了 BabyAI 任務的成功率。

下表顯示了 VirtualHome 任務的成功率。

