Paper link | Note link | Code link | ICLR 2023
這項研究探討了使用提示策略配合大型語言模型(LLM)來訓練強化學習(RL)方法。
具體而言,它研究了如何利用LLMs生成與用戶目標一致的 reward,並使用如 DQN 或 on policy RL 來評估這些方法。
在強化學習中,設計有效的獎勵函數是一項具有挑戰性的任務。
本研究通過使用代理獎勵函數來解決這個問題,其中涉及到提示大型語言模型。
自主代理在今天變得越來越有價值,因為它們可以根據人類用戶行為來學習政策,以改善控制和決策。然而,實施這項技術面臨兩個主要挑戰:

強化學習可以建模為馬可夫決策過程(MDP),其中代理在每個回合中選擇行動,以最大化累積獎勳。
在本研究中,馬可夫決策過程定義為 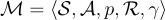 ,其中
,其中 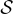 代表迄今為止談判中的話語表示空間,
代表迄今為止談判中的話語表示空間,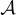 是狀態空間(所有可能話語的集合)。函數
是狀態空間(所有可能話語的集合)。函數  表示轉移概率,而
表示轉移概率,而 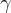 是折扣因子。
是折扣因子。
傳統上,獎勳函數 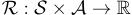 將狀態和行動映射為實數。
將狀態和行動映射為實數。
在本研究中,使用大型語言模型(LLM)作為代理獎勳函數,其中 LLM 接收文本提示並輸出字串。
在這裡,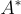 定義為所有字串的集合,而
定義為所有字串的集合,而 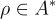 代表一個文本提示。大型語言模型表示為
代表一個文本提示。大型語言模型表示為 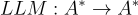 。
。
對於給定的提示 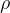 ,它包含以下部分:
,它包含以下部分:
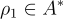 : 一個詳細描述當前任務的字串。
: 一個詳細描述當前任務的字串。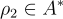 : 用戶提供的字串,概述了他們的目標,可以是提供
: 用戶提供的字串,概述了他們的目標,可以是提供 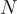 個示例或通過自然語言描述他們的目標。
個示例或通過自然語言描述他們的目標。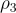 : 來自 RL 回合的狀態和行動的文本表示,使用解析器
: 來自 RL 回合的狀態和行動的文本表示,使用解析器 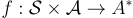 生成。
生成。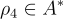 : 一個問題,詢問 RL 代理的行為(如
: 一個問題,詢問 RL 代理的行為(如 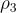 所述)是否符合
所述)是否符合 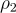 中概述的用戶目標。
中概述的用戶目標。最後,他們定義了一個二進制值 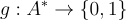 ,將 LLM 的文本輸出映射為二進制值。
,將 LLM 的文本輸出映射為二進制值。
在這一部分,他們評估了三種不同的問題和各種任務:



評估中使用了兩個指標:
標註準確率:這測量了在強化學習(RL)訓練期間,預測的獎勳值與真實獎勳函數的平均準確度。
代理準確率:這測量了RL代理本身的平均準確度。
在實驗中,與監督學習(SL)模型進行了比較。對於LLM,他們使用了GPT-3,並使用 DQN 算法或在政策RL方法進行訓練。

