在前兩天的內容中,我們依序介紹了標註詞性(POS Tagging)和提取實體(NER)的技術,對於探索句子的本質又更近了一步,接下來就可以進入到解析句子結構的主題了!
句法分析 ( syntactic parsing ) 同樣是 NLP 領域中非常重要的主題,它可以完整解析句子的結構,對於語意理解具有關鍵性的作用。
無論中文、英文、日文還是世界上其他的語言,雖然長相不同,用法也不同,但他們大多遵循著一定的結構來將單詞組合成完整的句子。
也因為如此,我們在學習語言的時候才能依據這些文法建立起基本的認知,從而與人交流。
而電腦在解析一個句子的時候,也可以按照同樣的模式,比方說:
Tom tripped and hurt his foot.
這是一個完整的句子,我們不單單可以用 POS 和 NER 標註出他們的詞性和實體,還可以確認哪些單詞是主語、謂語、賓語等,進而畫出整個句子的結構。
我們先拿上次教的 POS 把這個句子標註上詞性:
import spacy
nlp = spacy.load("en_core_web_sm")
sentence = nlp("Tom tripped and hurt his foot.")
print([(token.text, token.tag_) for token in sentence])
[('Tom', 'NNP'), ('tripped', 'VBD'), ('and', 'CC'), ('hurt', 'VB'), ('his', 'PRP$'), ('foot', 'NN'), ('.', '.')]
我們可以按照文法的概念從這張圖去逐層解析整個句子:
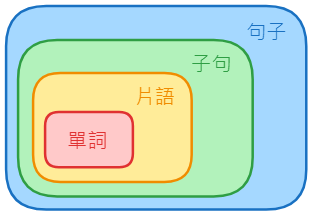
首先從單詞開始,也就是我們剛剛程式碼所輸出的這些單詞的詞性,像是名詞、動詞或形容詞,他們就是整個句子的結構中最基本的第一層。
接著,我們發現有一些單詞可以組成擁有更豐富意思的短語 ( phrase ),也可以叫做片語,像是名詞短語 ( Noun Phrase, NP )、動詞短語 ( Verb Phrase ) 或形容詞短語 ( Adjectival Phrase, AP )。
如果句子再更複雜一點的話,短語可以再組成子句 ( clause ),也就是包含主詞和動詞但還不是完整句子的一組單詞,包含獨立子句和從屬子句。
按照這個規則一直往上歸納的話,最後可以得到整個句子 ( Sentence, S ),也就是像這個樣子:
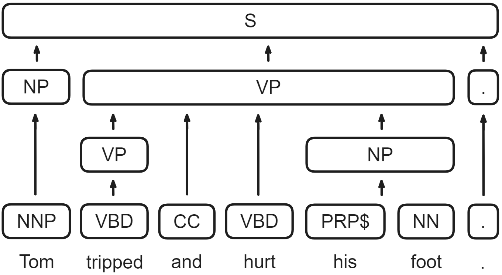
上述的分析方式就叫做成分句法分析 ( Constituency parsing ),它的想法就是將每個單詞視為句子的一個成分,小成分可以不斷組合成更大的成分,最終組成一個完整的句子。
常用的方法比方說上下文無關文法 ( Context-Free Grammar, CFG ),包含了一套規則,當句子輸入之後,它就會按照規則逐步解析,最終生成完整的句法樹。
那麼就來實際體驗一下吧!
我在網路上找到了好用的套件 benepar,它可以顯示出完整的句法樹,於是我按照官方文件提供的範例和更複雜的句子做了一個小練習:
!python -m spacy download en_core_web_md
!pip install benepar
import nltk
import benepar, spacy
benepar.download('benepar_en3')
nlp = spacy.load('en_core_web_md')
nlp.add_pipe('benepar', config = {'model': 'benepar_en3'})
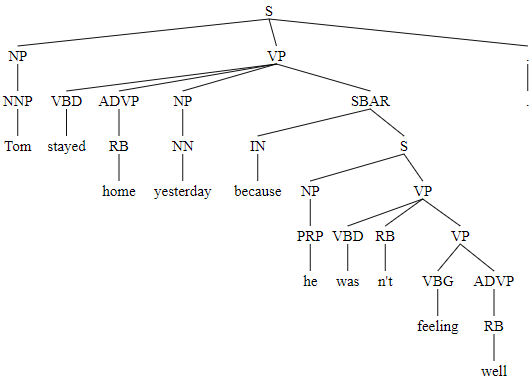
doc = nlp("Tom stayed home yesterday because he wasn't feeling well.")
sent = list(doc.sents)[0]
print(sent._.parse_string)
(S (NP (NNP Tom)) (VP (VBD stayed) (ADVP (RB home)) (NP (NN yesterday)) (SBAR (IN because) (S (NP (PRP he)) (VP (VBD was) (RB n't) (VP (VBG feeling) (ADVP (RB well))))))) (. .))
從輸出結果可以看到,小括號裡面的成分不斷組合起來,直到最外層的 S 就代表完整的句子。
不過因為它是一行顯示,不容易閱讀,所以我又找了另一個套件 constituent-treelib,它顯示的效果就讓我很滿意了。
!pip install constituent-treelib
from constituent_treelib import ConstituentTree, BracketedTree, Language, Structure
language = Language.English
spacy_model_size = ConstituentTree.SpacyModelSize.Medium
nlp = ConstituentTree.create_pipeline(language, spacy_model_size)
sentence_dyn = "Tom stayed home yesterday because he wasn't feeling well."
tree_dyn = ConstituentTree(sentence_dyn, create_pipeline = True)
tree_dyn
剛剛提到的成分句法分析專注在詞性和句法的結構,而依存句法分析 ( Dependency parsing ) 則是專注在單詞之間的聯繫,這種分析方式其實對於我們人類來說更容易理解。
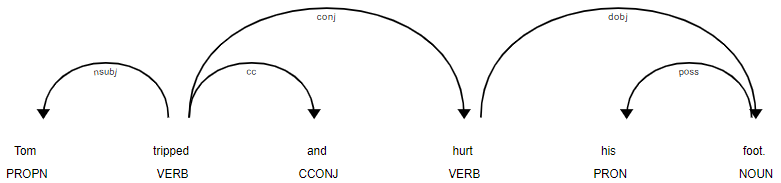
我們對同樣的句子用依存句法分析來畫一棵樹,就會像下面這張圖一樣:
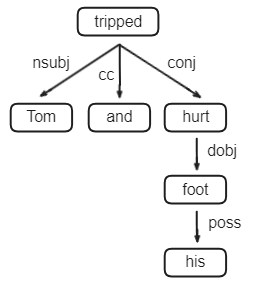
通過依存句法分析,我們能夠更清楚地理解每個單詞在句子中的角色和他們之間的關係,像是 tripped 用連接詞 and 串接了另一個動詞 hurt,以及 his 用來修飾 foot 等等。
此外,由於 tripped 並沒有其他單詞指向它,所以它就會是這棵樹的 root。
接下來就進入實作吧!
Spacy 本身就有提供 Dependency parsing 的工具,而且程式碼和 NER 很像:
from spacy import displacy
sentence = "Tom tripped and hurt his foot."
doc = nlp(sentence)
displacy.render(doc, style = 'dep', jupyter = True)
那麼,對句子的解析就到這裡告一段落,接下來我想要利用這幾天學到的概念 ( 主要是文本前處理 ) 來聊聊關於資訊檢索的知識,然後再進入下一個篇章吧!
推薦文章
詞性標註和句法依存的表示符號
成分句法分析 & 依存句法分析 Parsing 知識圖譜
Constituent Treelib (CTL) Demo
片語、子句、句子是什麼?來一次搞懂!


 iThome鐵人賽
iThome鐵人賽