
Paper link | EMNLP 2023
本研究使用強化學習 (RL) 並識別相關和不相關的標籤,以改進檢索常見問題 (FAQ) 的過程。
線上客戶服務中,高效檢索常見問題 (FAQ) 是至關重要的。
現有的方法通過動態對話上下文來增強用戶查詢與 FAQ 問題之間的語義關聯。
本研究引入了使用標籤來幫助消除不相關信息的 FAQ 問題。
對話式 FAQ 檢索的目的是在用戶與系統互動過程中找到與用戶意圖相符的 FAQ 問題。
當前的方法優先建模對話上下文中的語義信息。
然而,由於對領域的不熟悉或意外點擊,用戶可能會點擊與其意圖無關的問題。
這些不相關的信息,稱為“標籤”,會在對話上下文中引入噪聲,從而干擾檢索效率。

紅色和紫色文本分別描述了上下文中的相關和不相關標籤。
他們提出了一種標籤感知的強化學習策略,該策略建模標籤在不相關性中的動態變化,以在最小的互動回合中實現成功的 FAQ 檢索。
在本研究中,作者將問題-答案對定義為 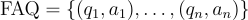 。每個問題
。每個問題 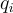 被歸類到一組標籤
被歸類到一組標籤 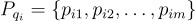 中。
中。
回合 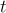 的對話上下文包括:
的對話上下文包括:
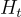 : 記錄用戶
: 記錄用戶 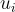 的查詢。
的查詢。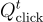 : 記錄用戶點擊的問題。
: 記錄用戶點擊的問題。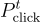 : 與用戶點擊的問題對應的標籤。
: 與用戶點擊的問題對應的標籤。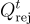 : 記錄用戶忽略的問題。
: 記錄用戶忽略的問題。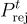 : 與用戶忽略的問題對應的標籤。
: 與用戶忽略的問題對應的標籤。
本研究將TRAVEL(Tag-aware Reinforcement Learning)公式化為一個多回合的標籤感知強化學習框架。
其目標是學習一個最優策略 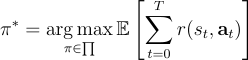 ,其中狀態
,其中狀態 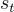 捕捉回合
捕捉回合 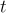 的對話上下文,
的對話上下文,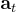 表示從候選中檢索的 FAQ 問題。
表示從候選中檢索的 FAQ 問題。
以下是研究中設計的五種不同的獎勳:
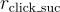 : 當用戶點擊問題時給予正獎勳。如果點擊的問題包含不相關的標籤,則此獎勳的值會降低。
: 當用戶點擊問題時給予正獎勳。如果點擊的問題包含不相關的標籤,則此獎勳的值會降低。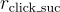 : 當用戶未點擊任何問題時給予負獎勳。
: 當用戶未點擊任何問題時給予負獎勳。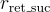 : 當用戶成功檢索到目標問題時給予強正獎勳。
: 當用戶成功檢索到目標問題時給予強正獎勳。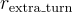 : 當回合數增加時給予負獎勳。
: 當回合數增加時給予負獎勳。標籤級狀態表示組件專注於估計對話上下文中的不相關標籤,並將此上下文轉換為狀態表示。
對話檢索策略優化組件利用狀態來確定 FAQ 檢索策略,使用 Q-Learning 來實現準確檢索,並目標是在最少的回合中完成。
他們使用自己的資料集,其中包含 72,013 個對話會話。
每個會話被表述為 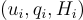 。
。
資料集中有 1,449 個 FAQ 問題和 1,201 個標籤。
他們將 TRAVEL 與兩類基準方法進行比較:


 iThome鐵人賽
iThome鐵人賽