分群是一種將相似的數據點分組或分配到同一類別的機器學習技術。本文將介紹分群的類型、K-Means演算法的原理與步驟,並通過簡單的範例來說明其應用。
在機器學習中,常見的分群方法有以下幾種類型:
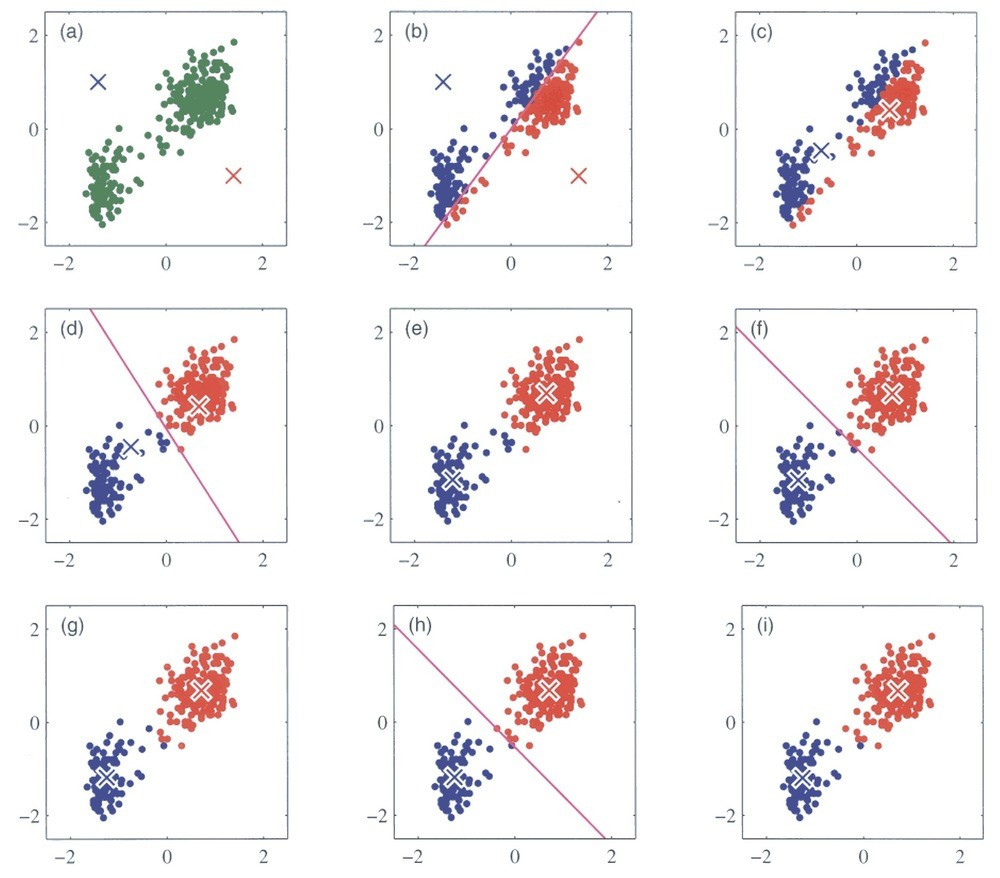
K-Means是一種常用的基於原型的分群方法,其目標是將數據點劃分到K個集群中,使得集群內的數據點彼此相似,而不同集群之間的數據點差異較大。下面是K-Means演算法的基本步驟:
假設有一個包含10個二維數據點的數據集:
數據點:[(2, 3), (5, 4), (9, 6), (4, 7), (8, 1), (7, 2), (6, 3), (3, 6), (1, 7), (4, 5)]
我們希望將這些數據點分成2個集群。首先,隨機選擇2個初始中心點,例如:
接下來,根據這兩個中心點,計算每個數據點到這兩個中心點的距離,並將每個數據點分配到最近的中心點所屬的集群中。
集群1:[(2, 3), (5, 4), (4, 7), (7, 2), (6, 3), (3, 6), (1, 7), (4, 5)]
集群2:[(9, 6), (8, 1)]
然後,重新計算每個集群的中心點:
再次進行分配和更新步驟,直到集群的中心點不再變化或達到最大迭代次數。最終,我們可以得到兩個集群,並且每個集群的中心點表示了該集群的特徵。
透過K-Means演算法,我們成功將數據集分成了兩個相似的集群,並且可以對新的數據點進行分類,從而應用在各種應用場景中,如市場分析、圖像分割等。
總結來說,K-Means演算法是一種強大且靈活的分群方法,通過迭代計算集群中心點,可以有效地將數據點分組,為數據分析和應用提供了有力支持。


 iThome鐵人賽
iThome鐵人賽