Beautiful Soup 函式庫 ( 模組 ) 是一個 Python 外部函式庫,可以從 HTML 或 XML 檔案中分析資料,並將分析的結果轉換成「網頁標籤樹」( tag ) 的型態,tag 是指 html 中 < > 包覆的程式碼,讓資料讀取方式更接近網頁的操作語法,處理起來也更為便利。
$pip install beautifulsoup4
from bs4 import BeautifulSoup
將 HTML 的原始碼提供給 Beautiful Soup,就能轉換成可讀取的標籤樹 ( tag )
Beautiful Soup 分析資料前需要有解析器來做預處理,雖然 Python 本身內建有一個 html.parser ,但使用 html5lib 解析器容錯率較強、速度較慢。
$pip install html5lib
接下來搭配之前所學的 request 使用 get 方法 ,獲取輔大首頁內容,並使用 html5lib 去分析找出 title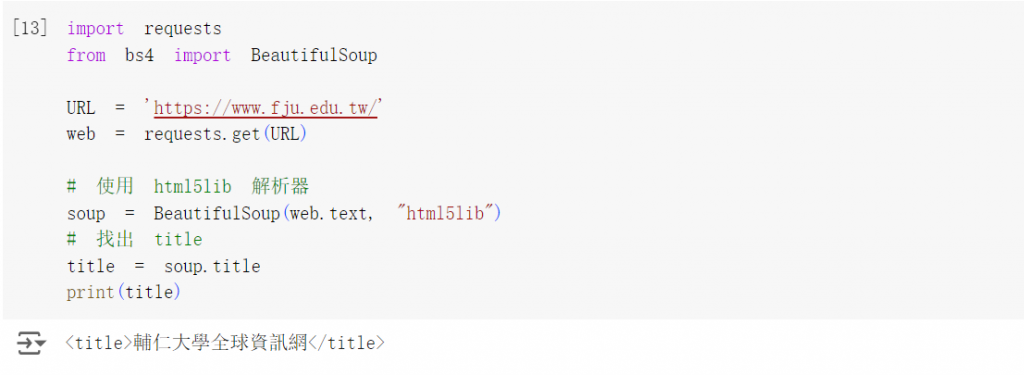
下列為 Beautiful Soup 尋找網頁內容最常用的方法 :
可以透過標籤、 id 或 class 來定位元素
下方的程式碼,使用 Beautiful Soup 取得範例網頁中指定 tag 的內容
import requests
from bs4 import BeautifulSoup
URL = 'https://www.iana.org/domains'
web = requests.get(URL)
# 使用 html5lib 解析器
soup = BeautifulSoup(web.text, "html5lib")
# 搜尋 id 是 logo 的 tag 內容
print(soup.select('#logo'))
print('\n----------\n')
# 搜尋所有 id 為 logo 的 div
print(soup.find_all('div',id="logo"))
print('\n----------\n')
# 搜尋所有的 div
divs = soup.find_all('div')
print(divs[1])
print('\n----------\n')
使用 Beautiful Soup 方法時,可以加入一些參數,幫助篩選結果
下列是一些常用方法 :
抓取到內容後,可以使用下列兩種常用的方法,將內容或屬性輸出為字串
下方的程式碼,使用 Beautiful Soup 取得範例網頁中帶有 class="navigation" 的 div 標籤 , 下的所有 li 標籤的內容
import requests
from bs4 import BeautifulSoup
URL = 'https://www.iana.org/domains'
web = requests.get(URL)
# 使用 html5lib 解析器
soup = BeautifulSoup(web.text, "html5lib")
# 先找到帶有 class="navigation" 的 div 標籤
navigation_div = soup.find("div", class_="navigation")
# 在該 div 下找到所有的 li 標籤
li_elements = navigation_div.find_all("li")
# 打印每個 li 中的 a 標籤的文本和 href 屬性
for li in li_elements:
a_tag = li.find('a')
if a_tag:
href = a_tag['href']
text = a_tag.text.strip() # 去除文本前後文的空白鍵
print(f'Text: {text}, Href: {href}')

參考資料 :
https://steam.oxxostudio.tw/category/python/spider/beautiful-soup.html
https://www.learncodewithmike.com/2020/02/python-beautifulsoup-web-scraper.html


 iThome鐵人賽
iThome鐵人賽