你可以通過多種方式收集資料:
確保你的資料已經標註好。例如,如果你在做圖像分類,每張圖像應該有一個對應的標籤。你可以使用工具如LabelImg來標註圖像。
兩種安裝方式:
pip install labelImg
個人習慣用pip install
可以觀察其他資料集的結構,進行編制
├── /your_dataset
│ ├── 9.2(日期)/
│ ├── 1(類別編號)/
│ ├── 170000180000(時間區間)/
│ ├── [日期] + _ + [影片檔名序號時間段]+ _ + c[相機編號] + _ + [frame] + _ + [version] + .jpg
│ ├── 20220914_170000180000_c002_00083605_0.jpg
│ ├── 20220914_170000180000_c002_00083605_0.json
│ ├── 2(類別編號)/
│ ├── 9(類別編號)/
│ ├── 9.3(日期)/
│ ├── 9.24(日期)/
│ ├── 9.25(日期)/
簡單的階層結構,圖片檔案名稱與標註檔案名稱一致會比較好處理。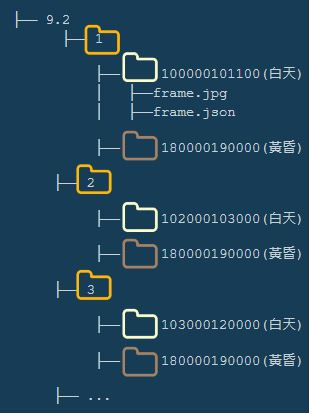
資料夾:[日期] + _ + [影片檔名序號時間段] = 20221016_150000160000
Output frame檔名:[日期] +_ + [影片檔名序號時間段] + _ + c[相機編號] + _ + [frame] + _ + [圖片版本] + .jpg
Json 檔案:20220914_170000180000_c002_00030600_0.json
CreateML json 內容:
[{"image": "20220914_170000180000_c002_00030600_0.jpg", "annotations": [{"label": "becky_1", "coordinates": {"x": 648.0247933884298, "y": 383.52066115702473, "width": 336.0, "height": 380.0}}, {"label": "becky_2", "coordinates": {"x": 1000.0247933884298, "y": 420.52066115702473, "width": 204.0, "height": 236.0}}, {"label": "becky_3", "coordinates": {"x": 1074.0247933884298, "y": 309.02066115702473, "width": 190.0, "height": 273.0}}]}]
資料清洗是確保資料質量的關鍵步驟,常見的清洗操作包括:
labelImg無法開啟資料夾圖片和label
labelImg重開多次仍讀不到Bounding Box(有讀到圖片),有比重開更有效的方式嗎?(我開laelImg指令是labelImg ./6)
https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md
這篇有教如何製作一個 可以訓練ControlNet的資料集
確保文件結構如下:
ControlNet/
├── training/
│ └── fill50k/
│ ├── prompt.json
│ ├── source/
│ │ ├── X.png
│ │ └── ...
│ └── target/
│ ├── X.png
│ └── ...
編寫 tutorial_dataset.py 來加載資料集。
import json
import cv2
import numpy as np
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self):
self.data = []
# './training/fill50k/prompt.json' 要改成你的標記 json 檔
with open('./training/fill50k/prompt.json', 'rt') as f:
for line in f:
self.data.append(json.loads(line))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
source_filename = item['source']
target_filename = item['target']
prompt = item['prompt']
# './training/fill50k/' 要改成你的"資料夾"
source = cv2.imread('./training/fill50k/' + source_filename)
target = cv2.imread('./training/fill50k/' + target_filename)
...
製作自己的資料集對於學習和應用深度學習技術至關重要。本文提供了關於資料集製作的系統性指導通過實踐,將能夠掌握資料集的製作和深度學習模型的訓練,為未來的研究和職業生涯奠定基礎。

