昨天我們實作自定義的函數透過 LCEL 成功開啟一個 AI 根據我們需求所寫出的網頁,也實作了幾個 LangChain 的 Runnable 元素。那還有一個也很常用的 Runnable 元素是 Retriver,那要使用 Retriver 之前,要先來了解 Embedding Model,再來實作怎麼做 Retriver!
同樣都是把文字轉換成 AI 可以處理的樣子,那這兩個差在哪呢?就我的認知:
Tokenizer 是將詞轉成 Token,不會去考慮詞與詞之間的關聯Embeddings 會考慮詞與詞之間的關聯,這個關聯就是使用距離的概念,關聯越接近的代表距離越近,最後將句子轉成一組向量,這組向量會考慮句子的前後文我這邊的實戰會專注在 LangChain 架構上。
from langchain_openai import OpenAIEmbeddings
from dotenv import load_dotenv
load_dotenv()
# 選擇 Embeddings Model
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 設定要轉向量的內容
text = "This is a test embedding"
text_list = ['test1', 'test2']
# 查看轉向量結果
print(embeddings.embed_query(text))
print(embeddings.embed_documents(text_list))
程式碼結果探討 🧐:
text-embedding-3-small、text-embedding-3-large、text-embedding-ada-002,這邊選擇 text-embedding-3-small 實作,可以參考 OpenAI 官網選擇模型。embed_query,多筆使用 embed_documents。text-embedding-3-small 的長度是 1536,text-embedding-3-large 是 3072,他的向量長度在後續存進向量資料庫之後可以看到,也會是個必要的訊息。from langchain_google_genai import GoogleGenerativeAIEmbeddings
from dotenv import load_dotenv
load_dotenv()
# 選擇 Embeddings Model
embeddings = GoogleGenerativeAIEmbeddings(model="models/text-embedding-004")
# 設定要轉向量的內容
text = "This is a test embedding"
text_list = ['test1', 'test2']
# 查看轉向量結果
print(embeddings.embed_query(text))
print(embeddings.embed_documents(text_list))
程式碼結果探討 🧐:
import json
import requests
from typing import List
from pydantic import BaseModel
from langchain_core.embeddings import Embeddings
class FFMEmbedding(BaseModel, Embeddings):
base_url: str = "https://api-ams.twcc.ai/api"
model: str = "ffm-embedding"
try:
api_key: str = os.environ['FFM_API_KEY']
except:
api_key: str = ""
def get_embeddings(self, payload):
endpoint_url = f"{self.base_url}/models/embeddings"
headers = {
"Content-type": "application/json",
"accept": "application/json",
"X-API-KEY": self.api_key,
"X-API-HOST": "afs-inference"
}
response = requests.post(endpoint_url, headers=headers, data=payload)
body = response.json()
datas = body["data"]
embeddings = [data["embedding"] for data in datas]
return embeddings
def embed_documents(self, texts: List[str]) -> List[List[float]]:
payload = json.dumps({
"model": self.model,
"inputs": texts
})
return self.get_embeddings(payload)
def embed_query(self, text: str) -> List[List[float]]:
payload = json.dumps({
"model": self.model,
"inputs": [text]
})
emb = self.get_embeddings(payload)
return emb[0]
from langchain_ffm import FFMEmbedding
# 選擇 Embeddings Model
embeddings = FFMEmbedding(model='ffm-embedding')
# 設定要轉向量的內容
text = "This is a test embedding"
text_list = ['test1', 'test2']
# 查看轉向量結果
print(embeddings.embed_query(text))
print(embeddings.embed_documents(text_list))
他是一個衡量語意相似度的指標,那語意越接近分數就越高,反之。在 Retriver 任務最常被使用到的就是 Cosine Similarity。
MMR 與 Cosine Similarity 相似,都會考慮語意相似度,而 MMR 還會考慮結果之間的相異性,避免結果過於相似,旨在平衡結果的相關性和多樣性。
# 匯入需要的套件
from langchain_astradb.utils.mmr import cosine_similarity, maximal_marginal_relevance
from langchain_ffm import FFMEmbedding
import numpy as np
embeddings = FFMEmbedding()
# 這是我們要相似度比對的內容
documents = [
"Python is a versatile programming language.",
"JavaScript is essential for front-end web development.",
"C# can be used for backend WebApi.",
"Java is a powerful language used in many enterprise applications.",
"Python is widely used in data science and machine learning."
]
# 主要輸入的內容
query = "I want to learn Python"
# 將以上內容都轉換為向量
documents_embeddings = embeddings.embed_documents(documents)
query_embedding = embeddings.embed_query(query)
# 計算 Cosine Similarity
similarity_scores = cosine_similarity([query_embedding], documents_embeddings)[0]
# 每筆資料會依序算出,再將分數降冪排列
sorted_indices = np.argsort(similarity_scores)[::-1]
sorted_scores = similarity_scores[sorted_indices]
print("Cosine Similarity Scores:")
for i, score in enumerate(sorted_scores):
print(f"Document {sorted_indices[i] + 1}: {score:.4f} ↓", documents[sorted_indices[i]])
# 計算 MMR
selected_indices = maximal_marginal_relevance(np.array(query_embedding), documents_embeddings, lambda_mult=0.5, k=5)
# 查看 MMR 的結果
print("\nSelected document indices using MMR:")
for idx in selected_indices:
print(f"Document {idx+1}: {similarity_scores[idx]:.4f}", documents[idx])
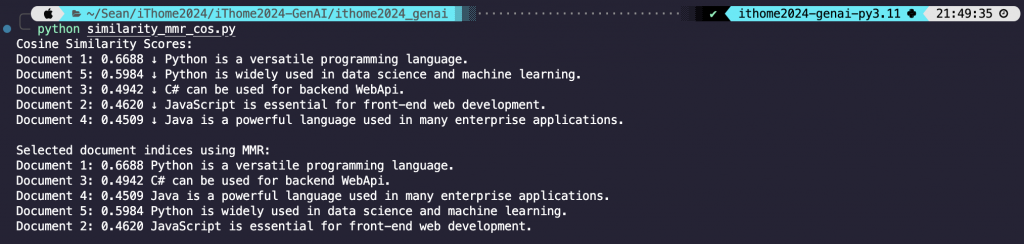
程式碼結果探討 🧐:
結果中可以看到,MMR 不是分數高的就會被排序在前面,還會考慮其結果的多樣性。
top_k。那可以看到 input 是 I want to learn Python,所以內容中有 Python 的分數就比較高,以這個範例來說他算是一個關鍵字的感覺。k 就是 top_k,而 lambda unit 是用來控制相似性與多樣性之間的平衡。那這其實跟 MMR 的公式有關,那這麼數學的東西我覺得不需要知道,只要知道 lambda_unit 怎麼下就好。那其實就是 lambda_unit 設的越大,就越考慮相似度 (下面附公式,看得懂的就知道為何),等於 1 的話就與 Cosine Similarity 相同;反之 lambda_unit 設的越小,就更考慮多樣性,從上面結果就可以看到,不是分數高就會被排在前面。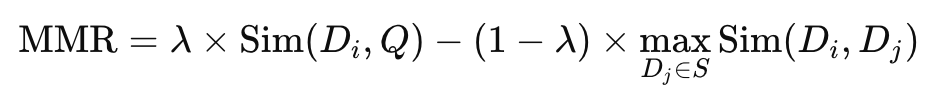
今天實作了如何使用 Embedding Model 將句子轉為向量,也實作了向量之間的比對。關於 MMR 的部分,有興趣的可以將 lambda_unit 調小,可以更好明白 MMR 的概念。Embeddings 其實就是實作 Retriver 前的準備,所以接下來將循序漸進實作 Retriver 的一些常見應用,像是 RAG 之類的。
寫程式不知道大家都用哪些 IDE,我自己原本是 Jupyter Notebook,後來實習之後開始感受到 VS code 的強大,因為他的擴充套件超多超好用,生產力拉滿的那種。那應該很多人都會購買 GitHub Copilot 來協助寫程式吧,但對我這種剛出社會的新鮮人,發現一個免費但不輸 Copilot 的好幫手,那就是 Amazon 開發的 Amazon Q 和 AWS Toolkit,這兩個都是完全免費的,真的是超級好用,推薦!


 iThome鐵人賽
iThome鐵人賽