昨天提到了可以通過 Precision 和 Recall 的計算方式來判斷我們檢索出來的結果好不好,然而這是在不考量文檔排名的情況下所做出的評估,如果使用 BM25 或其他 Ranking Retrieval 方法的話,作法又會稍有不同。
Ranking Retrieval 需要滿足我昨天所提到的第二個要求:使用者希望傳回的檢索結果中,越相關的資料,排名越前面。
接著就來聊聊如何評估帶有排名的檢索結果吧!
首先,我們可以根據 Precision 和 Recall 的反比關係,將他們畫成一張 Rrecision-Recall Curve:
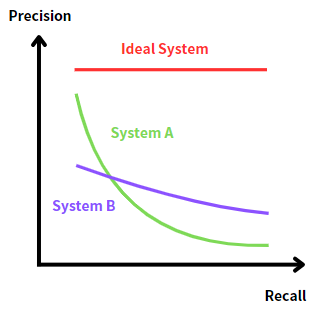
如果要判斷哪一條曲線的檢索表現更好的話,就可以使用 AUC ( Area Under Curve ) 來計算,也就是在曲線之下的面積大小。最理想的情況下面積是 1,而面積越小,代表檢索表現越差。
在這張圖中,我們最終的目標是越接近 Ideal System 的曲線越好,因為它的 Precision 無論 Recall 是多少都能維持很高的數值,這就代表所有相關的文檔全部都排在前幾名了。
然而 System A 和 System B 的曲線面積並不是這麼容易計算的,我們可以舉一個例子來說明。
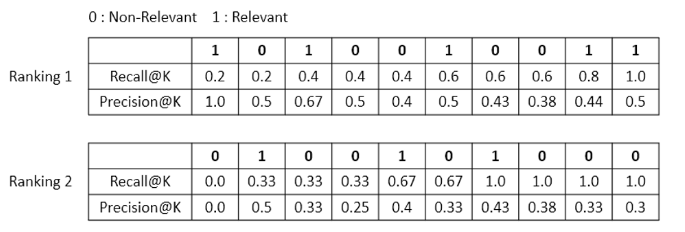
假設這裡有兩筆分別由 query 1 和 query 2 獲得的檢索結果,我們想要判斷他們的表現如何,於是把他們各自的檢索結果按照排名由左至右列出來:
這裡要介紹兩個名詞:
Recall@K
代表當數到第 K 個文檔的時候,它所對應的 Recall 值。以 Ranking 1 為例,k = 1 則 Recall = 1 / 5 = 0.2;k = 2 則 Recall = 1 / 5 = 0.2
Precision@K
代表當數到第 K 個文檔的時候,它所對應的 Precision 值。以 Ranking 1 為例,k = 1 則 Precision = 1 / 1 = 1;k = 2 則 Precision = 1 / 2 = 0.5
依此類推,如果忘記公式的話可以參考昨天那一篇。
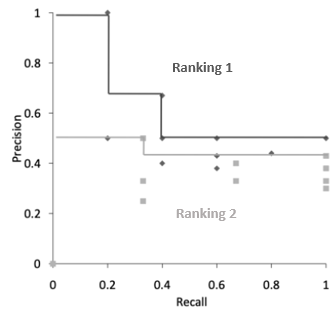
接下來,我們把這些數據用圖表示出來:
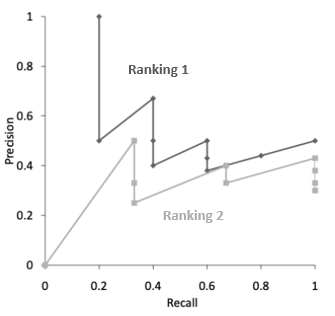
雖然大致看的出來 Ranking 1 的曲線在 Ranking 2 之上,不過如果要計算 AUC 的話就會比較麻煩,因為它是呈現鋸齒狀的,因此,我們可以通過插值 ( Interpolation ) 的方式做一下修改。
插值的作法是對每一個 Recall 值 ( 從 0.0 到 1.0 ),找到它最好的 Precision 表現,公式如下:
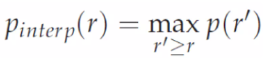
也就是說,對於任何第 r 位的 Recall 值,我們只要往後找到最佳的 Precision 當作自己的 Precision 就好。以 Ranking 1 為例,Recall = 0.8 的時候能夠找到最好的 Precision 就是 0.5,因此更新它自己的 Precision 值,依此類推。
最後,我們獲得了較為簡潔而且方便計算的曲線:
接下來,我們要介紹的評估方式叫做 Mean Average Precision ( MAP ),不過在這之前要先了解另外兩個名詞。
R-Precision
這裡的 R 指的是相關的文檔數量,因此 R-Precision 要計算的就是在對應的相關文檔數量下所獲得的 Precision 分數。和 Precision@K 不一樣的是,R-Precision 只會計算相關的文檔而已。以 Ranking 1 為例,Precision 在 R = 1 的時候是 1,在 R = 2 的時候是 0.67。
Average Precision ( AP )
它的計算方式是把所有的 R-Precision 加總平均,比方說 Ranking 1 的 AP = ( 1+0.67+0.5+0.44+0.5 ) / 5 = 0.622,Ranking 2 的 AP = ( 0.5+0.4+0.43 ) / 3 = 0.443。
了解這兩個名詞的意思之後,我們就可以來認識 MAP 了。
一開始看的時候還有點迷惑為什麼平均後還要再做一次平均,後來才搞懂原來 AP 的平均是對一條 query 裡面的 R-Precision 平均,而 MAP 的平均是把所有 query 的 AP 做平均,因為我們在評估這個檢索系統的時候一定會拿很多條 query 來做測試。
我們以同樣的例子來說,假設這個檢索系統用了兩個 query 做測試,其中 Ranking 1 獲得的 AP 是 0.622,Ranking 2 獲得的 AP 是 0.443,因此綜合起來的 MAP 就是 ( 0.622+0.443 ) / 2 = 0.533。
不過,對於 Ranking Retrieval 的評估方式到了這邊還沒有結束,因為 MAP 有一個小小的問題在於,它對於每一個名次所賦予的權重都是相同的,這對於排名靠前的文檔來說是不公平的。
因此,後來又提出了 DCG ( Discounted Cumulative Gain ) 的評估方式,從是否相關 ( Relevant / Non-Relevant ) 變成了相關程度,也就是為每一個文檔都先按照相關程度打了分,比方說 0 到 3 分,分數越高就越相關。
接下來,為了讓排名前面的文檔對最終評估結果的影響力更大,按照每一個文檔所在的名次進行打折 ( Discount ),名次越靠後的打折越多,即便它本來相關程度很高也會受到懲罰。
最後,按照累積增益的方式一個一個往上加,就可以獲得每一個文檔最終的 DCG 分數。
這個是它的公式,其中 rel 代表的就是該文檔的相關程度:
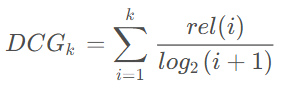
舉一個例子來算算看好了:
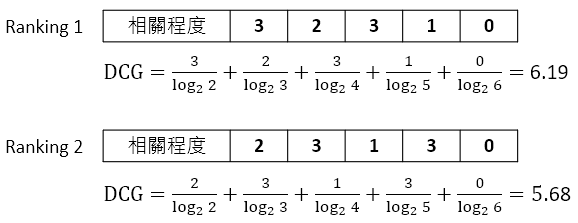
在不打折的情況下,兩者的累積增益 ( Cumulative Gain ) 都是 9 分,然而在打折之後,Ranking 1 的優勢就顯現出來了。
至於它的修正版 NDCG 就先不提了吧,本質上是為了正規化而做的,大家有興趣可以去查查看。
資訊檢索 ( IR ) 的部分到這裡暫時告一個段落,接下來要再進入新的篇章啦!
推薦文章 & 影片
PS : 沒想到資訊檢索有這麼多內容可以寫,這幾天也算是更了解 IR 一些了,之後有聊到 RAG 的話會再提到它吧。


 iThome鐵人賽
iThome鐵人賽