我主要是想試著使用ChatGPT,Gemini,Claude 對Kaggle 中的 Customer Personality Analysis資料集 進行分析。
在導入Kaggle 中的 Customer Personality Analysis資料集中的資料集之後,根據gemini 給出了可以根據資料使用其下可能的分析
基於提供的資料,我們可以進行多種資料分析,以下是一些建議:
客戶分群
方法:
使用RFM分析(Recency, Frequency, Monetary)根據客戶的最近購買時間、購買頻率和消費金額對客戶進行分群。
應用聚類算法(如K-means)根據客戶的各種特徵(人口統計、購買行為等)將客戶分為不同的群體。
目的:
識別高價值客戶、忠誠客戶、潛在客戶等不同群體。
根據不同群體的特徵和需求,制定個性化的行銷策略。
客戶終身價值預測
方法:
使用回歸模型(如線性回歸、決策樹)或機器學習模型(如隨機森林、梯度提升樹)來預測客戶的終身價值。
目的:
評估客戶對公司的長期價值。
根據客戶的終身價值,制定客戶關係管理策略,例如提供個性化服務和優惠。
行銷活動成效分析
方法:
使用A/B測試比較參與行銷活動的客戶與未參與客戶的行為差異。
計算轉換率、投資回報率(ROI)等指標來評估行銷活動的有效性。
目的:
衡量不同行銷活動的效果。
根據分析結果,優化行銷策略,提高行銷活動的投資回報率。
客戶流失預測
方法:
使用分類模型(如邏輯回歸、決策樹、支持向量機)或機器學習模型(如隨機森林、梯度提升樹、神經網絡)來預測客戶流失的可能性。
目的:
提前識別可能流失的客戶。
採取針對性措施,例如提供特別優惠或改善客戶服務,以挽留客戶。
產品推薦
方法:
使用協同過濾(Collaborative Filtering)或基於內容的過濾(Content-based Filtering)等推薦算法。
目的:
為客戶推薦他們可能感興趣的產品。
提高客戶滿意度和銷售額。
進一步分析建議
探索資料之間的相關性: 分析不同變量之間的關係,例如年齡與消費金額、教育程度與產品偏好等。
進行客戶細分: 根據客戶的特定屬性或行為,例如地理位置、購買頻率、產品偏好等,對客戶進行更細緻的劃分。
建立預測模型: 構建模型來預測客戶的未來行為,例如購買意願、對特定產品或行銷活動的反應等。
讓我們來試試看吧!!
1.ChatGPT的回應:
我已經收到你上傳的檔案。我會開始分析這個檔案並進行客戶分群。首先,我會檢視資料的結構,確認有哪些欄位可以用來進行分群分析。接下來,我會使用適當的演算法來執行客戶分群。請稍等片刻。
我將開始檢視資料。
import pandas as pd
# 讀取上傳的CSV檔案
file_path = '/mnt/data/marketing_campaign.csv'
data = pd.read_csv(file_path)
# 檢視資料的前幾行以及欄位資訊
data_info = data.info()
data_head = data.head()
data_info, data_head
看起來這個資料檔案的格式存在一些問題,所有的欄位似乎被合併到了一個欄位中,且使用了「\t」(Tab) 作為分隔符號,而非標準的逗號分隔格式。我會嘗試重新讀取這個資料檔案並指定正確的分隔符號。稍等片刻。
# 重新讀取檔案,這次指定使用 Tab (\t) 作為分隔符號
data = pd.read_csv(file_path, sep='\t')
# 檢視資料的前幾行及資料結構
data_info = data.info()
data_head = data.head()
data_info, data_head
資料已成功讀取,包含29個欄位。這些欄位涵蓋了客戶的基本資訊、消費行為、以及對行銷活動的反應等。
接下來,我將基於這些欄位進行客戶分群。通常,客戶分群可以使用如K-Means聚類等演算法來根據客戶特徵進行分群。我會首先進行資料的預處理,接著進行分群分析。
讓我先處理缺失值並標準化數據,以便進行聚類分析。
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
# 處理缺失值:以平均值填補 Income 欄位中的缺失值
imputer = SimpleImputer(strategy='mean')
data['Income'] = imputer.fit_transform(data[['Income']])
# 選擇要用來進行分群的特徵欄位
features = ['Year_Birth', 'Income', 'Kidhome', 'Teenhome', 'Recency',
'MntWines', 'MntFruits', 'MntMeatProducts', 'MntFishProducts',
'MntSweetProducts', 'MntGoldProds', 'NumDealsPurchases',
'NumWebPurchases', 'NumCatalogPurchases', 'NumStorePurchases',
'NumWebVisitsMonth']
# 特徵標準化
scaler = StandardScaler()
scaled_features = scaler.fit_transform(data[features])
# 檢查標準化後的數據
scaled_features[:5]
資料已經標準化處理,接下來我將使用 K-Means 演算法來進行客戶分群分析。我會設定一個初步的群數,並進行分析。稍後我會展示分群的結果並解釋每個群的特徵。請稍等片刻。
from sklearn.cluster import KMeans
import numpy as np
# 設定初步的群數
num_clusters = 5
# 使用 K-Means 演算法進行分群
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
kmeans.fit(scaled_features)
# 取得分群結果
data['Cluster'] = kmeans.labels_
# 檢視每個群的客戶數量
cluster_counts = data['Cluster'].value_counts().sort_index()
cluster_counts
分群結果如下:
群組 0: 567 位客戶
群組 1: 274 位客戶
群組 2: 550 位客戶
群組 3: 328 位客戶
群組 4: 521 位客戶
每個群組中包含的客戶數量相對平均。接下來,我可以分析各群組的特徵,了解這些群組之間的差異。
以下是各群組的主要特徵分析:
群組 0:
出生年份: 平均為1978年,屬於相對年輕的群體。
收入: 平均收入較低,約為29,815美元。
孩子數量: 平均有0.86個孩子,幾乎沒有青少年。
購買行為: 各類產品的消費額較低,尤其是酒類、肉類等主要消費品。
購物方式: 多數選擇店內購物,網路購物和目錄購物的次數較少。
群組 1:
出生年份: 平均為1969年,屬於中年群體。
收入: 平均收入最高,約為73,421美元。
孩子數量: 平均幾乎沒有孩子或青少年。
購買行為: 在所有產品上都有較高的消費,尤其是酒類、肉類和魚類產品。
購物方式: 偏好網路和目錄購物,這群人也是網路訪問最少的群體。
群組 2:
出生年份: 平均為1963年,屬於中年群體。
收入: 平均收入較低,約為42,386美元。
孩子數量: 有一定比例的家庭擁有青少年。
購買行為: 各類產品的消費額較低,尤其是酒類和肉類產品。
購物方式: 多數選擇店內購物,網路和目錄購物的次數較少。
群組 3:
出生年份: 平均為1967年,屬於中年群體。
收入: 平均收入較高,約為78,460美元。
孩子數量: 幾乎沒有孩子或青少年。
購買行為: 在所有產品上都有最高的消費,尤其是酒類和肉類產品。
購物方式: 偏好網路和目錄購物,這群人也是網路訪問最少的群體。
群組 4:
出生年份: 平均為1964年,屬於中年群體。
收入: 平均收入中等,約為59,431美元。
孩子數量: 大部分家庭擁有青少年。
購買行為: 在多類產品上有較高的消費,尤其是酒類和肉類產品。
購物方式: 偏好目錄和店內購物,網路訪問次數適中。
這些群組展示了不同的客戶特徵,從年齡、收入、家庭狀況到購買行為和偏好都有顯著差異。這些資訊可以幫助制定針對性的行銷策略。如果你需要進一步的分析或行銷建議,請隨時告訴我。
import matplotlib.pyplot as plt
import seaborn as sns
# 設定繪圖風格
sns.set(style="whitegrid")
# 繪製每個群組的特徵均值圖
plt.figure(figsize=(15, 10))
sns.heatmap(cluster_means.T, cmap='viridis', annot=True, fmt=".2f", linewidths=.5)
plt.title("Cluster Characteristics Heatmap")
plt.xlabel("Cluster")
plt.ylabel("Features")
plt.show()
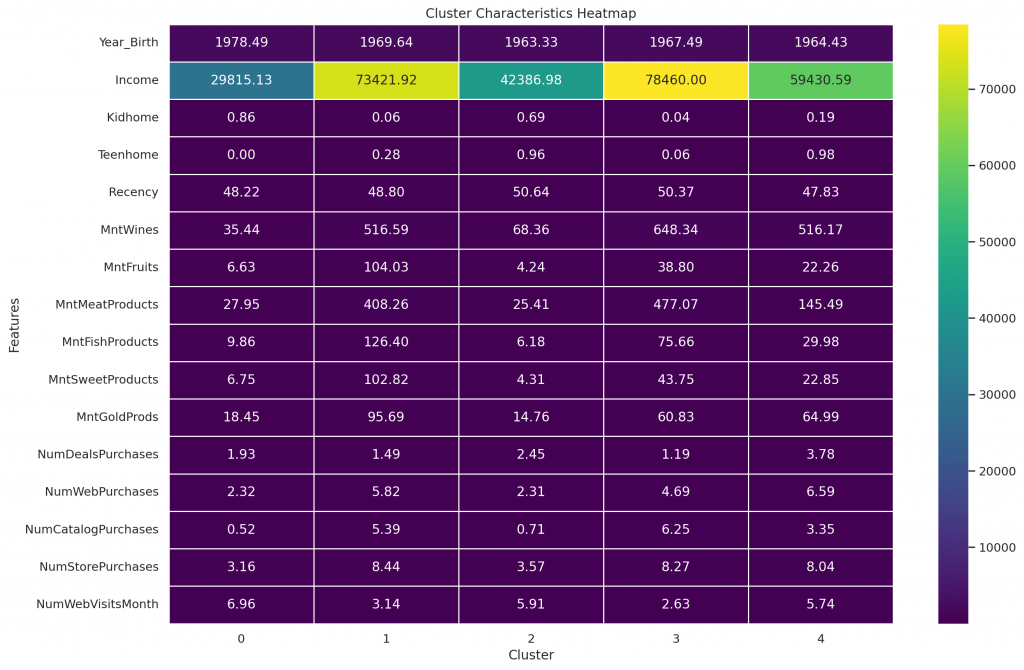
這張熱力圖展示了每個群組的特徵均值。顏色越深代表該群組在該特徵上的均值越高,從中可以直觀地看出不同群組之間的差異。這有助於識別哪些特徵在不同群組中最具代表性,例如哪個群組在收入或消費行為上最為突出。如果你需要進一步的分析或其他類型的可視化,請告訴我。
以下是ChatGPT的回答:
客戶終身價值(Customer Lifetime Value, CLV)是一個重要的指標,用於預測一個客戶在整個生命周期內為企業帶來的總收入。要進行CLV預測,我們可以基於現有數據中的消費行為來估算。具體步驟包括以下幾點:
計算客戶的平均消費:根據消費記錄來計算每位客戶的平均消費額。
預測客戶的購買頻率:根據購買次數來估算未來的購買頻率。
估算客戶的持續時間:根據客戶與企業的關係來估計客戶的平均持續時間。
計算客戶終身價值:根據上述三個指標來計算CLV。
我會基於這些步驟來進行計算。首先,我會估算每個客戶的平均消費額與購買頻率。
# 計算每位客戶的總消費額和購買次數
data['TotalSpend'] = data[['MntWines', 'MntFruits', 'MntMeatProducts', 'MntFishProducts',
'MntSweetProducts', 'MntGoldProds']].sum(axis=1)
# 計算每位客戶的平均消費額和購買頻率
data['AverageSpend'] = data['TotalSpend'] / (data[['NumDealsPurchases', 'NumWebPurchases',
'NumCatalogPurchases', 'NumStorePurchases']].sum(axis=1) + 1)
# 假設客戶的平均持續時間為3年(這是可以根據實際情況調整的參數)
average_lifespan_years = 3
# 預測客戶終身價值 (CLV)
data['CLV'] = data['AverageSpend'] * data[['NumDealsPurchases', 'NumWebPurchases',
'NumCatalogPurchases', 'NumStorePurchases']].sum(axis=1) * average_lifespan_years
# 檢視每個群組的平均 CLV
cluster_clv = data.groupby('Cluster')['CLV'].mean()
cluster_clv
結果
Cluster
0 285.252719
1 3871.451992
2 337.226366
3 3832.934722
4 2299.274943
Name: CLV, dtype: float64
根據分析,每個群組的平均客戶終身價值(CLV)如下:
群組 0: 平均 CLV 約為 285.25 美元
群組 1: 平均 CLV 約為 3,871.45 美元
群組 2: 平均 CLV 約為 337.23 美元
群組 3: 平均 CLV 約為 3,832.93 美元
群組 4: 平均 CLV 約為 2,299.27 美元
這些結果表明,群組 1 和群組 3 的客戶具有更高的終身價值,這些群組中的客戶可能更願意進行高額消費,且與企業的互動更頻繁。這些資訊可以幫助你針對性地制定行銷策略,以最大化客戶終身價值。
如果你需要進一步的分析或視覺化,請告訴我。
# 繪製每個群組的平均 CLV 條形圖
plt.figure(figsize=(10, 6))
sns.barplot(x=cluster_clv.index, y=cluster_clv.values, palette="viridis")
plt.title("Average Customer Lifetime Value (CLV) by Cluster")
plt.xlabel("Cluster")
plt.ylabel("Average CLV (USD)")
plt.show()
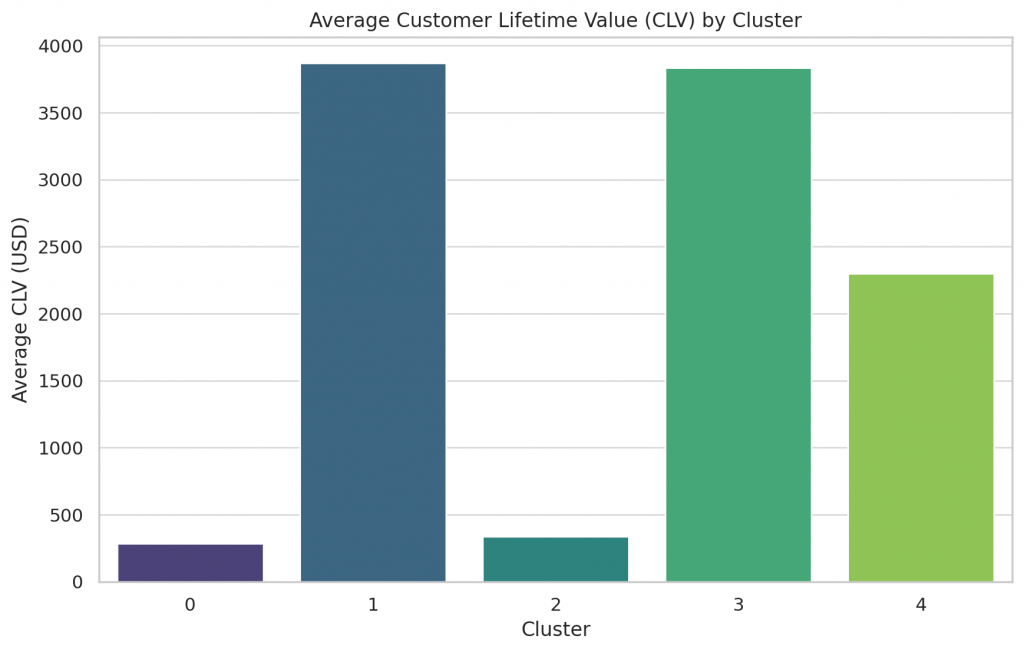
這張條形圖展示了每個群組的平均客戶終身價值(CLV)。你可以清楚地看到群組 1 和群組 3 的客戶終身價值顯著高於其他群組,表明這些群組的客戶可能是企業的核心消費者。這些資訊可以幫助你優化資源分配和行銷策略,以最大化客戶的終身價值。如果有其他需求,隨時告訴我。
我猜大概open ai 跟google把內部用於分析客戶的資料跟方法都拿去給模型訓練以及使用agent測試過了,不過有些地方還是會出很多bug就是了,這個是剛剛好能運作的版本。

