之前的章節幾乎涵蓋了 Spring AI 的基本功能,是時候向下一個里程邁進了,接下來就是企業應用的重頭戲-RAG
先來看看 Spring AI 對 RAG 的說明:
一種被稱為"檢索增強生成"(RAG)的技術應運而生,RAG 用來將相關數據加入提示詞,以獲得準確的回覆內容。
簡單的說就是減少 AI 的幻覺,下面是 RAG 的流程圖,主要可區分兩個階段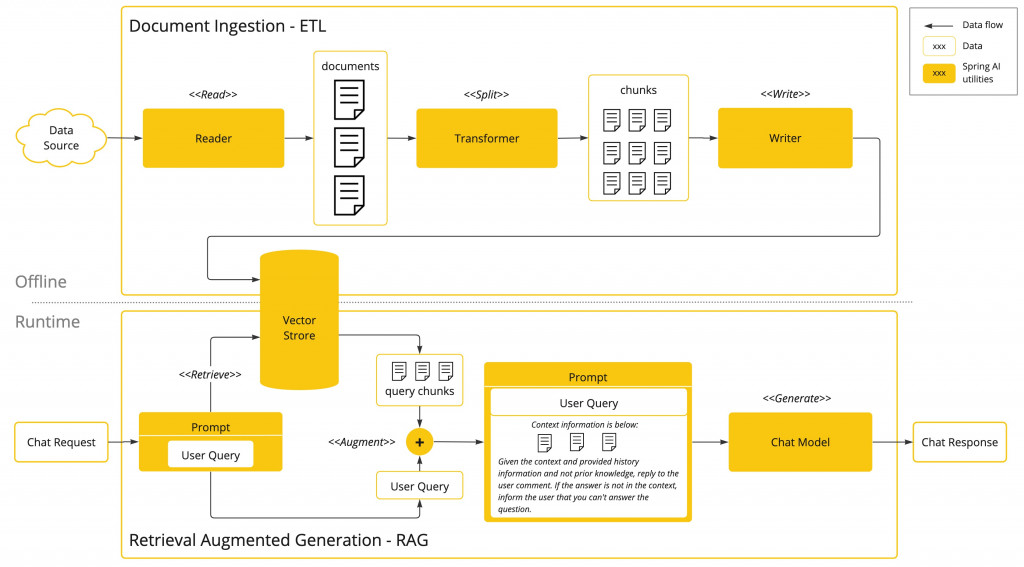
這個階段採用批次運作的方式,從檔案中讀取非結構化數據,對其進行 Embedding,然後將內容與 Embeddings 一起寫入向量資料庫。
整體來看,這是一個ETL(提取、轉換和載入)流程。向量資料庫儲存的資料會被用於 RAG 的檢索部分。
將非結構化資料載入向量資料庫的過程中,最重要的轉換之一就是將原始文件分割成小塊。
分割的過程有兩個重點:
RAG 的執行階段是處理使用者輸入。當 AI 模型要回答使用者的問題時,問題和所有"相似"的 Chunks 都會被放入提示詞中。
這就是使用向量資料庫的原因。它能很快速的找到相似內容。
前面幾天介紹的內容基本上都是 Runtime 的範圍,Offline 的部分就是將檔案資料向量化,向量資料庫則是串起這兩功能的核心
下面來看一下 Spring AI 在 ETL 提供了哪些類別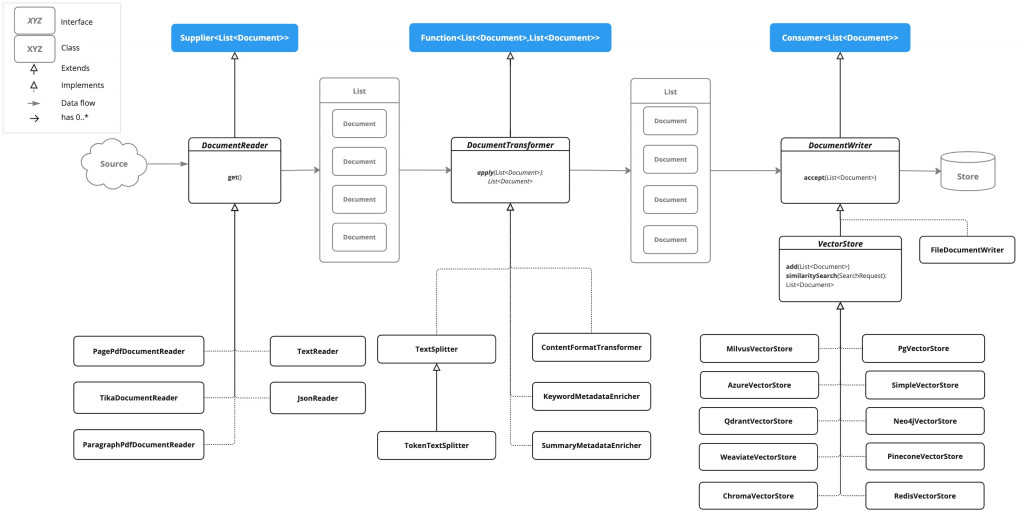
三個介面分別對應到 Offline 三個動作
DocumentReader: 這介面在做讀取資料的處理,同時繼承了多種介面,主要用來讀取不同類型的檔案,並將內容轉為 List<Document>,Document 在儲存對話時已經看過有資料內容外,還會記錄相關的 metadata,另外還有一個很重要的內容 Media,這表示 ETL 除了能讀取一般文件外,還能讀取多媒體檔案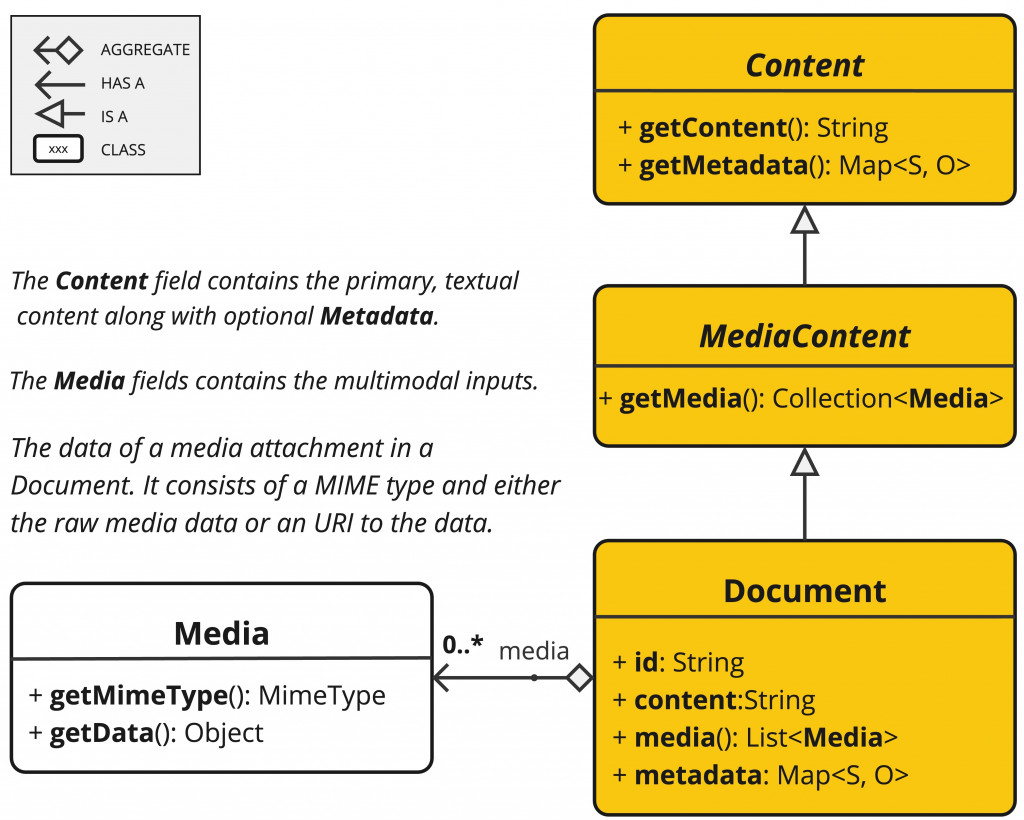
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}
DocumentTransformer: 這個介面動作很簡單,就是將大的 Document 拆成更小的 Chunks,而轉換後的類別依然是 Document,切塊的大小取決於 AI 同時能吞吐的 Tokens 數量
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return apply(transform);
}
}
DocumentWriter: 這個介面我們之前有操作過,就是將對話內容寫入向量資料庫的操作
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
accept(documents);
}
}
今天主要介紹 RAG 需要準備哪些工作,沒實作程式碼,接下來幾天凱文大叔就會介紹 Spring AI 針對 ETL 提供的工具如何使用
今天學到了甚麼?
凱文大叔使用 Java 開發程式超過 20 年,對於 Java 生態非常熟悉,曾使用反射機制開發 ETL 框架,對 Spring 背後的原理非常清楚,目前以 Spring Boot 作為後端開發框架,前端使用 React 搭配 Ant Design
下班之餘在 Amazing Talker 擔任程式語言講師,並獲得學員的一致好評
最近剛成立一個粉絲專頁-凱文大叔教你寫程式 歡迎大家多追蹤,我會不定期分享實用的知識以及程式開發技巧
想討論 Spring 的 Java 開發人員可以加入 FB 討論區 Spring Boot Developer Taiwan
我是凱文大叔,歡迎一起加入學習程式的行列


 iThome鐵人賽
iThome鐵人賽