延續昨天的主題,今天要處理的文件內容比昨天複雜,分別是
PDF:PagePdfDocumentReader、ParagraphPdfDocumentReader
DOCX, PPTX, HTML…:TikaDocumentReader
以上都是 Spring 封裝 Apache 專案的工具類別,PDF 是 pdfbox專案,而 TikaDocumentReader就像它的名稱是 Tike 的專案,Tike 支援的檔案類型可參考官方文件
PagePdfDocumentReader 與 ParagraphPdfDocumentReader 只差在一個是以 Page 為單位,一個是以目錄的章節為單位,顯然以章節為單位拆分內容就不會被截斷,不過不是所有的 pdf 文件都有目錄,我們在程式中可先使用ParagraphPdfDocumentReader 失敗時在改用PagePdfDocumentReader,這樣會最大程度優化文件向量化的結果,另外企業將資料向量化時不可能一份一份操作,凱文大叔特地將鐵人賽前幾天的文章轉成 pdf 檔,並存在 resources/pdf 目錄下,來看看程式如何批次處理這麼多份文件
首先需要先引入依賴才能使用,編輯 pom.xml 加入下面內容
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
EtlService.java : 在 Service 中加入以下函式
public List<Document> loadPdfAsDocuments() throws IOException {
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
Resource[] resources = new Resource[0];
resources = resolver.getResources("./pdf/*.pdf");
//透過上面方式可將指定目錄下所有的pdf檔案載入,後面在針對每份檔案轉換為 Document
List<Document> docs = new ArrayList<>();
for (Resource pdfResource : resources) {
try {
//先使用目錄分段讀取方式
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader(pdfResource);
docs.addAll(pdfReader.read());
} catch (IllegalArgumentException e) {
//沒有目錄會產生Exception,在改用分頁方式拆分
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(pdfResource);
docs.addAll(pdfReader.read());
}
}
return docs;
}
public void importPdf() throws IOException {
//與Text一樣需在使用TokenTextSplitter切塊
TokenTextSplitter splitter = new TokenTextSplitter();
vectorStore.write(splitter.split(loadPdfAsDocuments()));
}
EtlController.java:Controller 加入對應的 API
@GetMapping("readpdf")
public List<Document> readPdfFile() throws IOException{
return etlService.loadPdfAsDocuments();
}
@GetMapping("importpdf")
public void importPdf() throws IOException{
etlService.importPdf();
}
PathMatchingResourcePatternResolver,透過getResources("*.pdf”),就能讀取所有的 pdf 檔TokenTextSplitter 分割成更小塊直接看最後寫入向量資料庫的成果,可以看到 metadata 預設會保存檔名跟第幾頁,如果使用段落拆分則會顯示哪個段落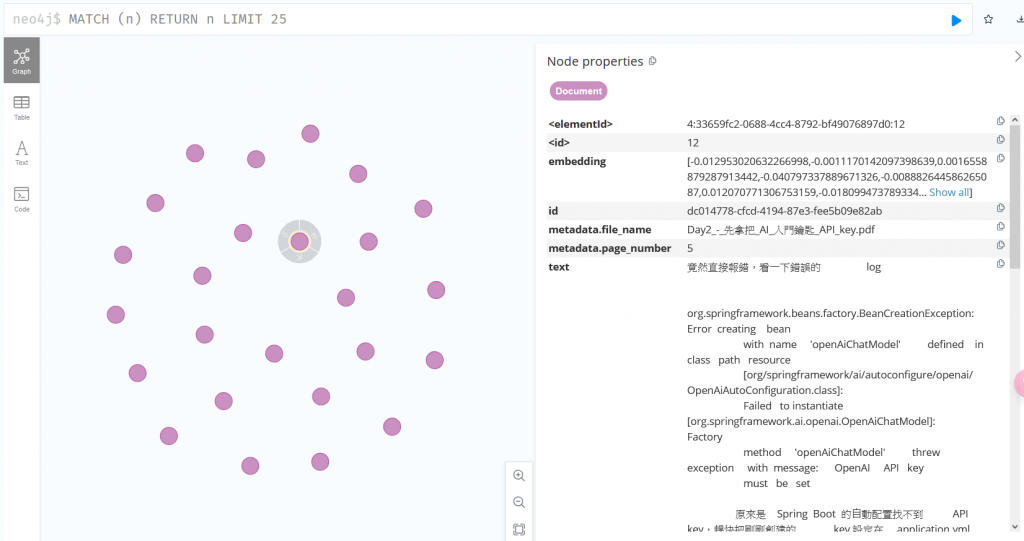
Tike 支援的檔案類型非常豐富,有興趣可自行到官網查看,另外 Tike 也有支援 pdf 檔案,不過核心也是使用 pdfbox,使用上個範例能控制更多細節
下面凱文大叔就實作如何讀入 pptx 資料
一樣先把 pptx 集中在一個目錄,這裡我就先放一個檔案
pom.xml 一樣需要引入依賴,內容如下
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
EtlService.java : 在 Service 中加入以下函式
public List<Document> loadPptxAsDocuments() throws IOException {
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
Resource[] resources = new Resource[0];
resources = resolver.getResources("./pptx/*.pptx");
List<Document> docs = new ArrayList<>();
for (Resource pptxResource : resources) {
TikaDocumentReader pptxReader = new TikaDocumentReader(pptxResource);
docs.addAll(pptxReader.read());
}
return docs;
}
public void importPptx() throws IOException {
TokenTextSplitter splitter = new TokenTextSplitter();
vectorStore.write(splitter.split(loadPptxAsDocuments()));
}
EtlController.java:同樣的 Controller 也加入對應的 API
@GetMapping("readpptx")
public List<Document> readPptxFile() throws IOException{
return etlService.loadPptxAsDocuments();
}
@GetMapping("importpptx")
public void importPptx() throws IOException{
etlService.importPptx();
}
可以看到 metadata 預設一樣會有檔名,若要再添加一些資訊記得在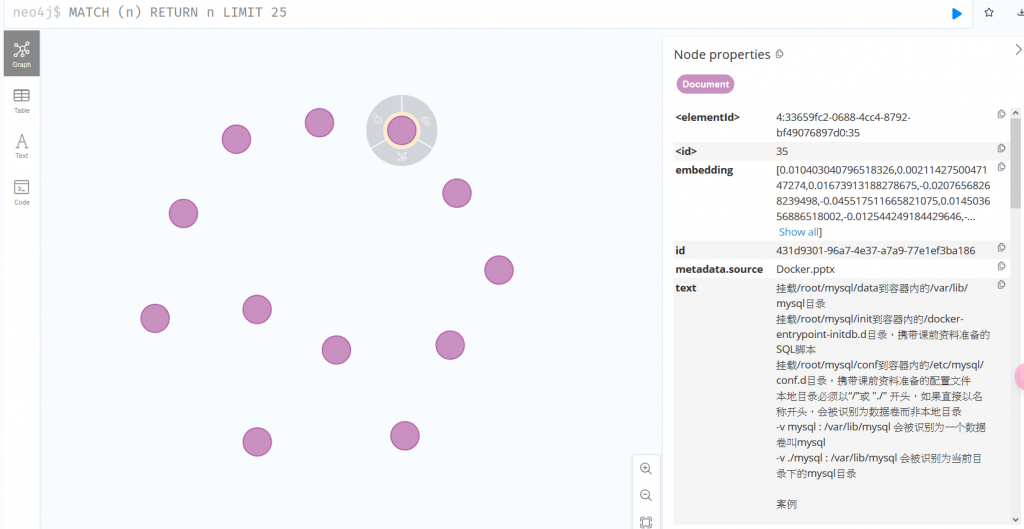
大家應該能發現 Spring 封裝後的工具操作起來都差不多,程式碼的差別就只是 Reader 的類別不一樣,大家可以將 Tike 支援的類別都測試看看
Transformers除了將大文件拆成小文件外,還有許多特別的功能,明天凱文大叔在做更詳細的說明
程式碼下載: https://github.com/kevintsai1202/SpringBoot-AI-Day26.git
今天學到了甚麼?
ParagraphPdfDocumentReader 與 PagePdfDocumentReader 讀取 pdf 內容並匯入向量資料庫TikaDocumentReader 讀取 Office、HTML 等相關文件內容並匯入資料庫凱文大叔使用 Java 開發程式超過 20 年,對於 Java 生態非常熟悉,曾使用反射機制開發 ETL 框架,對 Spring 背後的原理非常清楚,目前以 Spring Boot 作為後端開發框架,前端使用 React 搭配 Ant Design
下班之餘在 Amazing Talker 擔任程式語言講師,並獲得學員的一致好評
最近剛成立一個粉絲專頁-凱文大叔教你寫程式 歡迎大家多追蹤,我會不定期分享實用的知識以及程式開發技巧
想討論 Spring 的 Java 開發人員可以加入 FB 討論區 Spring Boot Developer Taiwan
我是凱文大叔,歡迎一起加入學習程式的行列


 iThome鐵人賽
iThome鐵人賽