前面已詳述過 RAG 最主要的目的,就是提供 LLM 未知的資訊,而這些資料會使用 ETL 技術或是由企業資料庫中取得,經過 embedding 計算後存於向量資料庫,而詢問內容同樣也經過 embedding 後在去向量資料庫中比對,所得近似資料連同問題再一起提供給 LLM,利用 In-Context 的特性將資訊整理後將最終結果呈現出來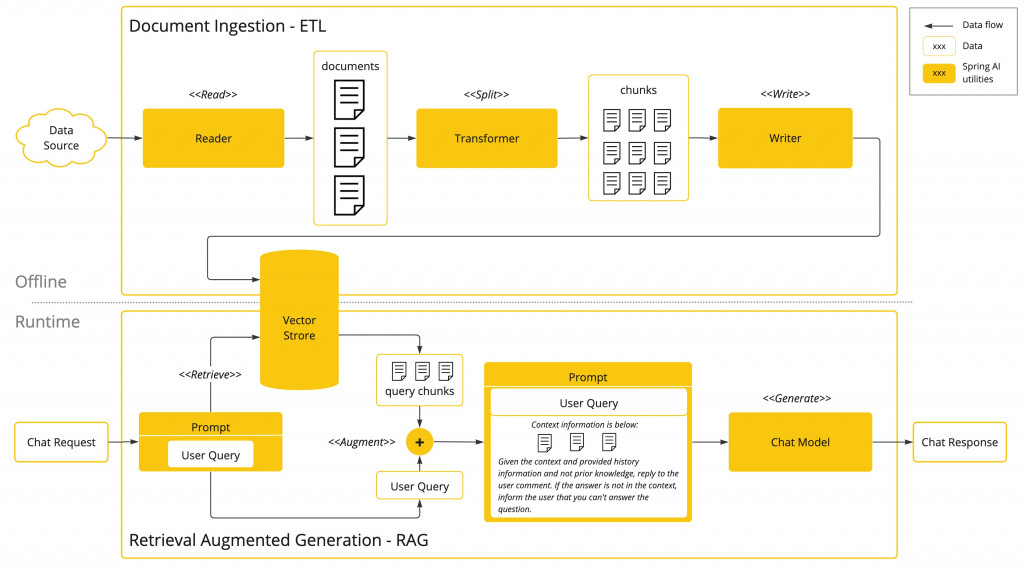
所以 RAG 最後的動作其實包含了查詢與內容生成,生成的部分與前面說的提示詞應用都大同小異,就是將內容附加在提示詞中,再由 LLM 分析產生最佳的內容,RAG 最關鍵的部分就是如何讓查詢更為精準
昨天講的 Transformer 使用了關鍵字跟摘要讓內容更為精準,而查詢時也有許多手法能加強搜尋結果,這些方法還不斷在增加中,凱文大叔就自己所知列出於下,若有遺漏或有甚麼新的手法也請各位前輩分享
正所謂垃圾進垃圾出,若提供的分塊內容偏離主題太多,LLM 的回答就會有所偏離,此時可設定一個分數基準,低於分數的內容就屏棄不用,避免干擾 LLM 生成資料
昨天的關鍵字除了能強化 embedding 分數外,在近似查詢前後也能使用關鍵字過濾內容讓得到的結果更進一步的精煉
避免 LLM 胡謅一通可以在生成資料後請 LLM 再驗證一次,可以使用不同的 LLM 來進行複驗讓資料更有公信力
同一份資料拆解前都有一定的相關性,分塊後將原始文件的資訊紀錄在 metadata 中,進行 embedding 時可以加強各維度的分數
使用 Embedding 做近似查詢雖然很快,但還是有命中率不太高的問題,於是就有 ReRank 進行二次篩選的模型
ReRank 雖然處理速度較慢,但是比 Embedding 模型更為精準,我們就能使用 Embedding 先搜尋 50~100 筆近似資料,之後再透過 ReRank 從中找出 5~10 筆更為精準的資料,這樣不但兼顧速度又能有更準確的內容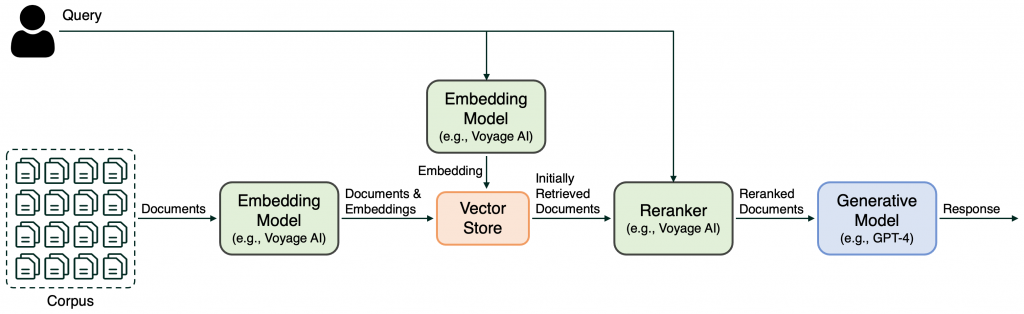
這是最近幾個月才由微軟提出的論文,將 ETL 後的資料以及詢問的內容都先經過資料梳理成多個 Entities,並將 Entity 之間建立 Relation,再對這些 Entities 進行 embedding,查詢時使用近似搜尋找出符合的 Entity,
再透過 Graph 的特性找到相關的 Entity,最後 Entity 與相關內容整理後再交由 LLM 生成結果,如此可以將有關係的內容也一併找出,不像一般的 RAG 只能關注在分塊後的資料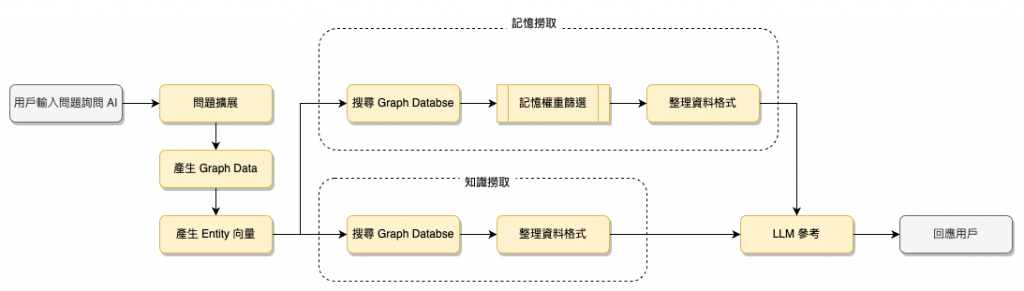
如同上面所說,使用 RAG 查詢前需要先將資料匯入向量資料庫(使用ETL或是從其他資料庫匯入),資料就拿前幾天匯入向量資料庫的文章(這次鐵人賽的內容)作為範例
為了區隔 ETL 以及 查詢,將 查尋 的部分獨立出來,分別寫一隻 Service 類別以及 Controller 類別,其他的 Config 類別以及 application.yml 設定都沿用前幾天的程式
SearchService.java
@Data
@Service
public class SearchService {
private final VectorStore vectorStore; //Spring AI自動配置
private final ChatClient chatClient; //使用Config類別建立好Bean,這裡可以直接綁定
public String search(String query) throws IOException {
Path pathResult = Paths.get("./result.md");
String result = chatClient.prompt().advisors(
new QuestionAnswerAdvisor(vectorStore) //RAG增強器
).user(query).call().content();
Files.writeString(pathResult, result);
Resource resource = new UrlResource(pathResult.toUri());
return resource;
}
}
為了呈現程式碼的效果,特別轉成md檔案匯出
API 也分離出來
SearchController.java
@RestController
@RequestMapping("/ai/search")
@RequiredArgsConstructor
public class SearchController {
private final SearchService searchService;
@GetMapping("/rag")
public ResponseEntity<Resource> search(String query) {
Resource resource;
try {
resource = searchService.search(query);
} catch (IOException e) {
e.printStackTrace();
return ResponseEntity.internalServerError().build();
}
return ResponseEntity.ok()
.header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=\"result.md\"")
.body(resource);
}
}
與前面讓 AI 有記憶的程式只差在 QuestionAnswerAdvisor,我們來看看原廠程式碼有甚麼特別的地方吧
private static final String DEFAULT_USER_TEXT_ADVISE = """
Context information is below.
---------------------
{question_answer_context}
---------------------
Given the context and provided history information and not prior knowledge,
reply to the user comment. If the answer is not in the context, inform
the user that you can't answer the question.
""";
RAG增強器的目的就是透過向量資料庫取得資料,再將 {question_answer_context} 替換成搜索的內容
public QuestionAnswerAdvisor(VectorStore vectorStore, SearchRequest searchRequest, String userTextAdvise) {
}
其實有三個建構子,不過最後都會呼叫這個,下面是參數的敘述
vectorStore:向量資料庫變數
searchRequest : 篩選資料的參數設定
userTextAdvise : 自訂義提示詞,記得要加上 {question_answer_context},近似搜尋的結果才會被附加上去
@Override
public AdvisedRequest adviseRequest(AdvisedRequest request, Map<String, Object> context) {
// 1. Advise the system text.
String advisedUserText = request.userText() + System.lineSeparator() + this.userTextAdvise;
var searchRequestToUse = SearchRequest.from(this.searchRequest)
.withQuery(request.userText())
.withFilterExpression(doGetFilterExpression(context));
// 2. Search for similar documents in the vector store.
List<Document> documents = this.vectorStore.similaritySearch(searchRequestToUse);
context.put(RETRIEVED_DOCUMENTS, documents);
// 3. Create the context from the documents.
String documentContext = documents.stream()
.map(Content::getContent)
.collect(Collectors.joining(System.lineSeparator()));
// 4. Advise the user parameters.
Map<String, Object> advisedUserParams = new HashMap<>(request.userParams());
advisedUserParams.put("question_answer_context", documentContext);
AdvisedRequest advisedRequest = AdvisedRequest.from(request)
.withUserText(advisedUserText)
.withUserParams(advisedUserParams)
.build();
return advisedRequest;
}
這裡是RAG查詢生成資料的精華,備註已經說明有四個動作,如果想寫自己的增強器也可以按照這四個步驟來撰寫程式
.withFilterExpression()加上篩選條件請求的URL: http://localhost:8080/ai/search/rag?query=
使用Spring AI寫一個RAG應用,包含ETL與搜尋跟生成資料都需要有程式範例,ETL需要從一個目錄下取得所有的pdf檔案進行處理,程式範例請使用上下文提供的資料,不要隨意改寫
總結一下今天學到了甚麼?
https://github.com/kevintsai1202/SpringBoot-AI-Day29.git
凱文大叔使用 Java 開發程式超過 20 年,對於 Java 生態非常熟悉,曾使用反射機制開發 ETL 框架,對 Spring 背後的原理非常清楚,目前以 Spring Boot 作為後端開發框架,前端使用 React 搭配 Ant Design
下班之餘在 Amazing Talker 擔任程式語言講師,並獲得學員的一致好評
最近剛成立一個粉絲專頁-凱文大叔教你寫程式 歡迎大家多追蹤,我會不定期分享實用的知識以及程式開發技巧
想討論 Spring 的 Java 開發人員可以加入 FB 討論區 Spring Boot Developer Taiwan
我是凱文大叔,歡迎一起加入學習程式的行列

