scikit-learn 是 Python 中一個提供了許多機器學習算法和工具,內建的資料庫又稱為玩具資料。
pip install scikit-learn
from sklearn import datasets
df_dia = datasets.load_diabetes()
import pandas as pd
# 檢視數據集
print(df_dia.keys())
# 輸出:dict_keys(['data', 'target', 'frame', 'DESCR', 'feature_names', 'data_filename', 'target_filename', 'data_module'])
df_dia.target

6. 查看樣本特徵矩陣
df_dia.data
https://ithelp.ithome.com.tw/upload/images/20240901/201688111YNpahlClp.png
# 獲取特徵矩陣和目標變量
X = df_dia.data
y = df_dia.target
# 創建 DataFrame
df = pd.DataFrame(data=X, columns=df_dia.feature_names)
df['target'] = y
# 顯示前幾行數據
df.head()

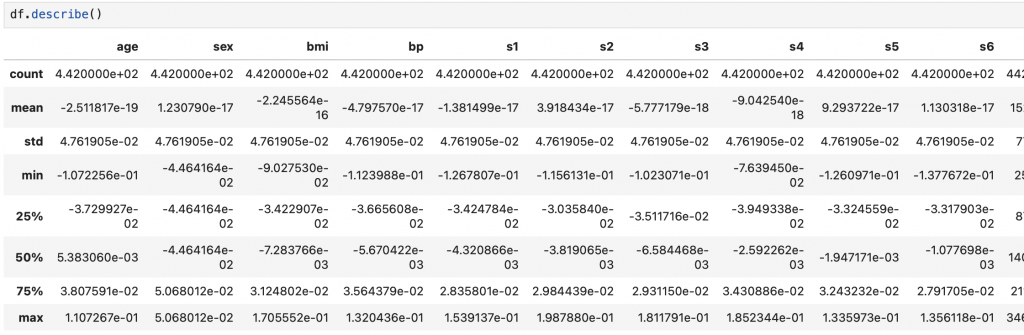
df.describe()
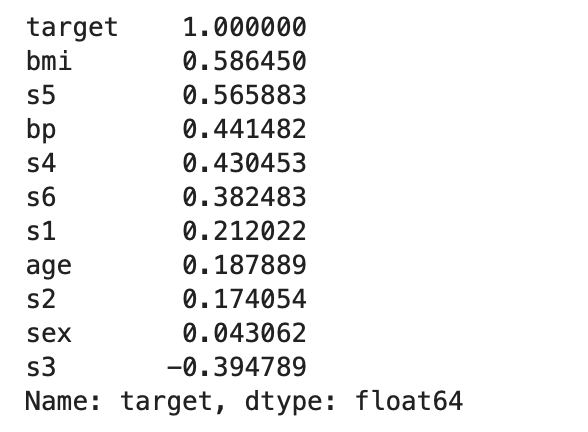
# 計算特徵和目標變量之間的相關性
correlation_matrix = df.corr()
# 顯示與目標變量相關的特徵
print(correlation_matrix['target'].sort_values(ascending=False))


{kind=link}