TL;DR:
這系列都不會直接介紹什麼工具,反而比較多在討論怎假設、驗證、測試,也就是文戲會比較多點 :)
要是期待看完這系列會成為 DevOps 現成的專家的話,那推薦看其他位大大的比較快。
本來也不在意測試與假設驗證,覺得寫測試是很浪費時間的大大,根本上班就沒空做,也能點擊上一頁看其他位大大的比較快。畢竟文字不少,看完這堆文字頗需要時間。
能不能完賽我也不清楚 QQ
今年是連續第六年參賽的我,連續幾年分享了點可觀測性、遙測信號、OpenTelemetry、跟相關的工具與服務們。今年七月也出了第一本著作 OpenTelemetry 入門指南:建立全面可觀測性架構,與翻譯可觀測性工程。
以前分享的都是大家比較知道的 Log、Metric 這類大部分團隊已經有應用於系統之中的信號。以及這幾年在微服務系統架構中,越來越被重視的 Trace。今年想說聊一點有關 Profile 相關的議題,其實 Profile 的歷史比 Trace 還更早出現,與 Metric 差不多時間點出限於軟體系統中。
以下是 Log、Metrics、Trace 和 Profile 在軟體系統中出現的歷史時間點:
1960年代:
Log 是最早出現的遙測信號之一。在大型主機(mainframe)時代,系統會生成簡單的文本記錄來追踪操作流程和錯誤。這些記錄最初主要是用來故障排除和審計。
1970年代:
隨著 Unix 操作系統的誕生,系統日誌(system logs)變得更加普遍和標準化。Unix 系統中的 syslog 成為了記錄系統事件的標準機制,並且被廣泛使用至今。
1980年代及以後:
Log 隨著應用程式日益複雜,開始從系統級別拓展到應用程式級別,記錄應用內部的操作過程。這一時期還出現了專門的日誌管理工具,如 syslog-ng 和 Logrotate,來幫助管理和分析越來越多的日誌數據。
1980年代:
隨著分散式系統和網路的興起,系統性能監控變得越來越重要。最早的 Metric 通常是手動收集的數據點,用於監控如 CPU 使用率、內存消耗等基本的系統資源指標。
1990年代:
隨著網路服務和電子商務的發展,出現了專門的監控工具,如 Nagios(1999年推出),用於自動化收集和報告系統指標,並設置閾值來觸發警報。
2000年代及以後:
隨著雲計算和大規模分佈式系統的普及,Metric 收集和分析變得更加自動化和集中化。工具如 Graphite 和後來的 Prometheus(2012年推出)成為收集、儲存和查詢 Metric 的主流解決方案,支持更加即時和靈活的系統性能監控。
2000年代初期:
隨著分散式系統變得越來越複雜,特別是微服務架構的出現,傳統的日志和指標已無法全面描述跨多個服務的請求流。為了應對這一挑戰,Google 開發了分散式追踪系統 Dapper(2005年左右),這是最早的分散式追踪系統之一。
2010年代:
受 Dapper 的影響,Twitter 開發了 Zipkin(2012年推出),一個開源的分散式追踪系統,旨在幫助開發者和運維人員理解微服務架構中請求的流動路徑。此後,Jaeger(2017年由 Uber 推出)等工具也相繼問世,成為分佈式追踪的主流工具。
OpenTracing 和 OpenTelemetry:
隨著分散式追踪變得越來越普遍,2016年推出了 OpenTracing,這是一個用於標準化分散式追踪的開源 API,後來與 OpenCensus 合併,形成了 OpenTelemetry,成為現在追踪標準的一部分。
1980年代至1990年代:
最早的 Profiling 技術出現在開發人員試圖優化應用程式性能的背景下。工具如 gprof(1982年推出)由 GNU 提供,用於分析程序的 CPU 使用情況。
2000年代:
隨著多核處理器和複雜應用程式的普及,Profile 工具逐漸從開發階段滲透到正式營運環境。Java 開發的 Profiling 工具如 VisualVM 和 JProfiler 開始流行。
2010年代及以後:
隨著持續性能監控需求的增加,無侵入式的 Profiling 技術開始出現,如基於 eBPF 的 Profiling,允許在正式營運環境中進行持續監控而不對系統性能造成顯著影響。Pyroscope 和 Parca 等現代工具就是這類技術的代表。
總結來說,log 是最早出現的遙測信號,隨後是 metric 作為性能監控的核心手段,trace 則是在面對日益複雜的分散式系統下發展起來的,而 Cloud Provider(AWS、GCP、Azure...)profile 雖然很早就出現,但其實有在關注的人不多,但在大家逐步上雲的營運上,除了性能調優需求外,分析 Profile 後做出的處理,也能替公司省下不少成本。這些遙測信號的演變反映了軟體系統的複雜性和對性能及穩定性要求的提高。
在「OpenTelemetry 入門指南」第3章裡與「可觀測性工程」的序當中,都提到系統的狀態空間。
在系統的行為中,我們對於它們的理解/掌握程度又能分類。
已知-未知(Known-Unknowns)是指我們已經知道系統中存在某些問題或異常情況,但需要進一步的調查才能理解這些問題的具體原因或位置。例如,當 Metric 顯示某個系統指標異常時,我們可以確定存在問題,但具體的原因可能仍然不明確,需要進一步的 Log 或 Trace 來定位。
Metric 和 Trace 是識別和解決已知-未知問題的主要工具。Metric 提供了系統健康狀況的數據概覽,幫助我們識別異常,而 Trace 則提供了問題發生位置的詳細視圖,幫助我們深入了解問題的根本原因。
已知-未知(Known-Unknowns)是指我們已經知道系統中存在某些問題或異常情況,但需要進一步的調查才能理解這些問題的具體原因或位置。例如,當 Metric 顯示某個系統指標異常時,我們可以確定存在問題,但具體的原因可能仍然不明確,需要進一步的 Log 或 Trace 來定位。
Metric 和 Trace 是識別和解決已知-未知問題的主要工具。Metric 提供了系統健康狀況的數據概覽,幫助我們識別異常,而 Trace 則提供了問題發生位置的詳細視圖,幫助我們深入了解問題的根本原因。
未知-未知(Unknown-Unknowns)是指那些我們甚至不知道存在的問題,這些問題在影響系統之前可能完全不為人知。這些問題通常隱藏在系統的底層程式碼或資源分配策略中,僅憑 Metric、Log 或 Trace 是難以發現的。
Profile 是針對 Unknown-Unknowns 問題的強大工具。透過分析應用程式的資源使用情況,Profile 能夠挖掘出深層次的性能問題,如資源過度消耗或低效的程式碼實做結構,這些問題往往是其他信號無法察覺的。
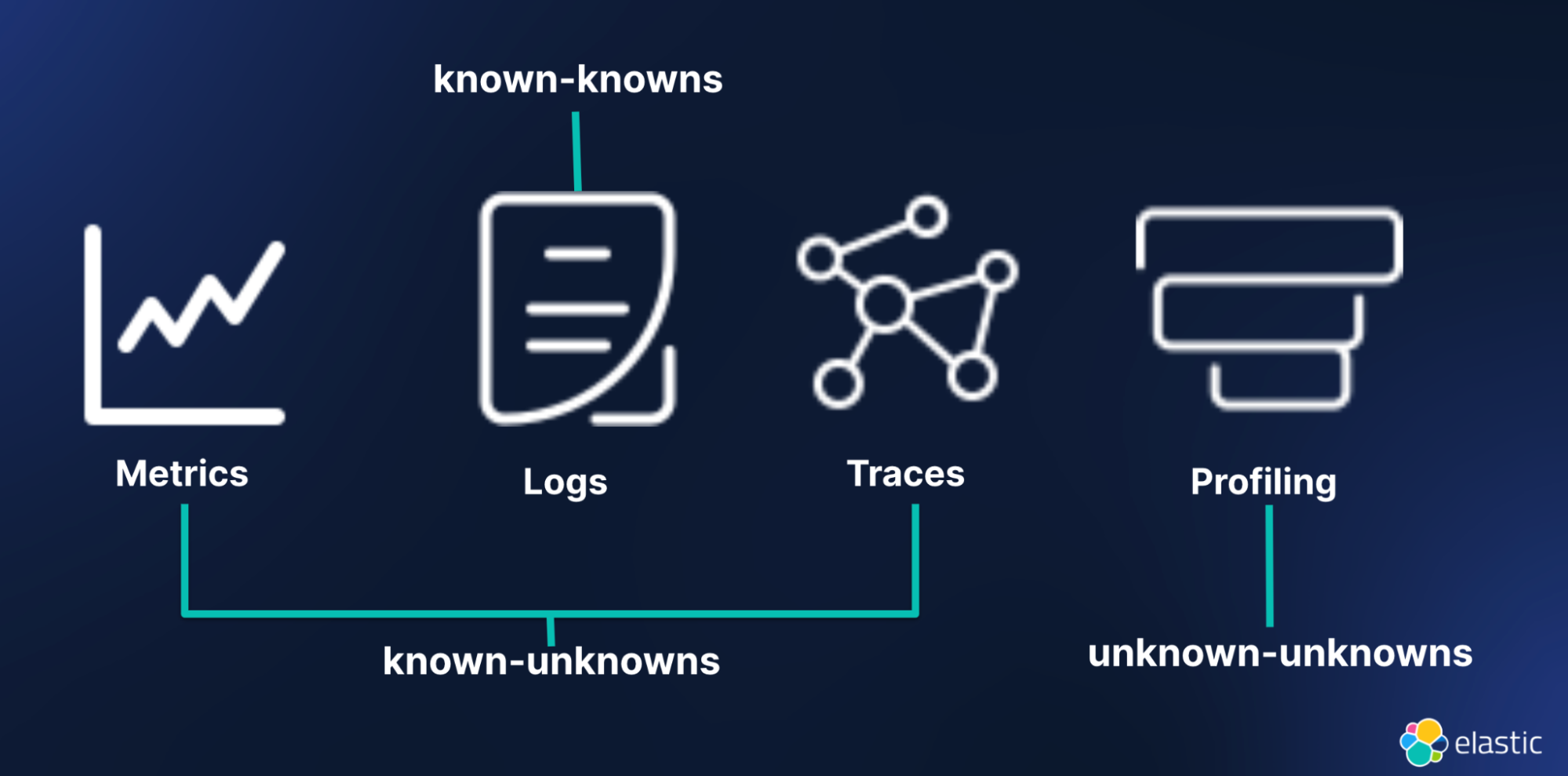
圖片參考自 Elastic Why metrics, logs, and traces aren’t enough
Logs 是遙測信號中最早出現的形式,它們記錄了系統中的具體事件,提供了故障排除和 Audit 的基礎。Log 的主要優勢在於其能夠提供詳細的事件追踪,幫助開發者和運維人員了解系統中發生了什麼。
然而,Logs 的局限性在於它們僅能記錄已知的事件,對於未知問題的探查能力有限。在面對 Known-Unknowns 或 Unknown-Unknowns 問題時,僅依賴 Logs 可能不足以全面理解和解決問題。
Metric 通過定期收集和報告系統性能指標,為我們提供了系統健康狀況的即時概覽。Metric 的優勢在於其結構化的資料形式,使得設置閾值警報和進行趨勢分析變得容易。
在處理 Known-Unknowns 問題時,Metric 是非常有用的工具。當我們觀察到某個指標超出預期範圍時,Metric 可以引導我們進一步調查問題的根本原因。然而,僅憑 Metric,我們無法深入了解問題的具體細節,需要結合其他遙測信號來進行更全面的分析。
Trace 是理解分散式系統中請求流動的關鍵工具。它們記錄了請求從進入系統到處理完成的每一步操作,並提供了每個步驟的執行時間和狀態。
在解決 Known-Unknowns 問題時,Trace 能夠幫助我們定位問題發生的位置。例如,當一個請求的某個步驟出現異常延遲時,Trace 能夠指引我們到具體的服務或元件進行深入調查。這使得 Traces 成為分散式系統中的重要診斷工具。
Profiles 是針對系統資源使用進行深度分析的工具。通過捕捉 CPU 時間、內存使用等資源消耗情況,Profiles 能夠揭示系統中最耗資源的程式碼區段,幫助開發者優化系統性能。
Profiles 的最大價值在於其能夠識別 Unknown-Unknowns 問題。這些問題可能隱藏在程式碼的某個角落,通常難以通過其他信號發現。通過持續 Profiling,開發者可以實時監控系統性能,並及時解決潛在的瓶頸問題。
以前我們應該最常看到的是這張圖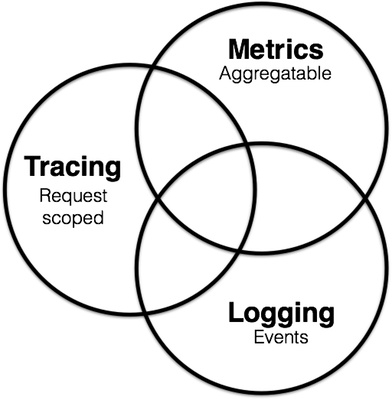
加入 Profile 後變成如下圖所示。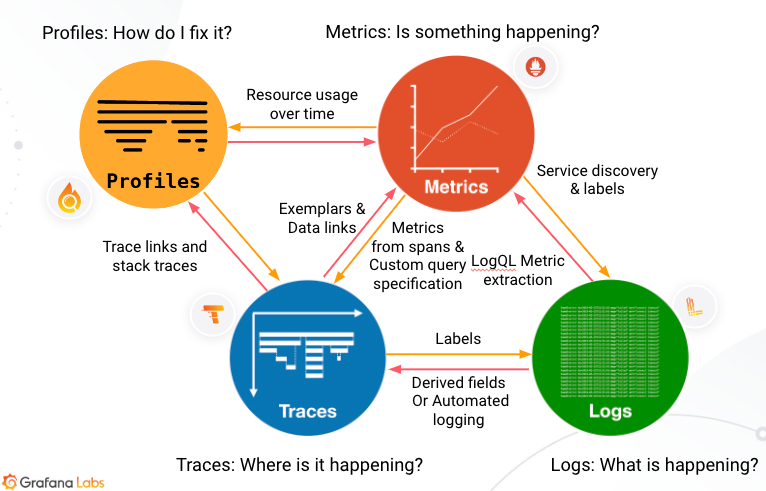
參考自 Grafana Traces and telemetry
metric、log 和 trace 各有其在系統可觀測性中的優勢,但它們主要提供的是已知問題的上下文或定位資訊:
Metrics 讓我們知道系統中發生了某些異常,但它們往往只能提示我們需要進一步調查。
Logs 記錄了具體的系統事件,幫助理解問題的表現形式,但僅限於已知範疇內的問題。
Traces 幫助定位問題的具體位置,特別是跨系統或跨服務的操作,但無法深入程式碼層面。
而 Profile 則彌補了這些信號的不足,特別是在揭示那些深層次、難以察覺的性能瓶頸和資源耗盡問題方面。當 Metric 顯示某個系統資源使用異常時,Profile 可以深入到具體的程式碼對應行,幫助找出資源過度消耗的根本原因。這種微觀層面的分析能力使 Profile 成為解決「為什麼會這樣?」這類問題的關鍵工具。
如果沒辦法將基本的三種遙測信號相互關聯起來做分析。那麼團隊肯定引入了不少工具在蒐集遙測信號,但其實當問題來臨時,幫助有限,因為處理者還是要開啟超過一個以上的工具和瀏覽器視窗在排查問題。甚至很可能有的工具還沒權限。
此時,就更不用說引入 Prfoile了。災難ㄚ!! 天崩地裂一開 掰。
Known-knowns 問題:Log 是解決這類問題的主要工具,因為它們記錄了已知的事件和狀態變化,幫助我們快速確定問題所在。
Known-Unknowns 問題:Metric 和 Trace 能夠幫助識別和定位這類問題,為進一步的調查提供指引。
Unknown-Unknowns 問題:Profile 是解決這類問題的核心工具,通過深入分析系統資源使用,揭示潛在的性能瓶頸和程式碼問題。
在現代雲端環境中,將 metric、log、trace 和 profile 整合到一個統一的平台中是至關重要的,而 OpenTelemetry 這一個開源遙測信號的框架,目的就是在整合從產生遙測信號、注入上下文內容、集中管理遙測信號與配置遙測流水線。只有集中統一後,這樣可以確保在處理系統問題時,能夠從宏觀到微觀層面逐步深入,最終全面理解系統的運行狀況,並有效解決問題。
統一平台的好處在於,它可以減少資料孤島現象,使得觀察性更具效率,同時也降低了系統運維的複雜性和成本。通過統一的觀察性平台,團隊能夠更快地識別問題的根源,優化系統性能,並最終提升整體運維效率。
總結來說,這四種信號形成了一個強大的工具集,為現代雲端原生環境提供了全面的可觀測性。profile 的加入,使得這個工具集能夠進一步深入到系統的內部運作,揭示其他信號難以發現的深層次問題,成為現代可觀測性中不可或缺的一部分。
沒想到吧 XD 其實我們做軟體設計與解決問題的開發者,時常需要回來思考我們為什麼要用這些技術。不然只會引入一個新框架(OpenTelemetry)和一堆工具(Grafana、ELK、DataDog...)。真的有幫助你解決問題了嘛?這裡提到的問題又是什麼?
先說我不是 DDD 高手,只是有稍微研究一點點。
在 DDD 中,Problem Domain 和 Solution Domain 是相互影響的,因為解決方案的設計應該直接反映出問題領域中的需求和挑戰。在這一過程中,遙測信號起到了關鍵的作用,幫助我們在兩個領域之間建立起有效的連接。
Problem Domain 是指我們試圖解決的業務問題或挑戰。這個領域涉及到問題的背景與範圍、約束條件、相關規範以及解決問題所需的專業知識。當我們試圖理解一個問題並定義它的範圍時,遙測信號在提供背景資訊和問題診斷方面發揮著關鍵作用。
Log 在 Problem Domain 中扮演著事件記錄和背景提供者的角色。通過分析 log,開發者可以了解業務流程中的關鍵事件,識別出系統何時以及在哪裡出現了問題。這些資訊有助於深入理解問題領域,並確保在設計解決方案時考慮到所有相關的業務背景。
Metric 提供了系統運行狀態的直觀數據表達,這些數據能幫助我們識別業務層面的性能問題或異常行為。當我們在 Problem Domain 中尋找具體問題時,Metric 能夠指示出哪些部分的性能表現不符合預期,從而引導我們進一步調查。
Trace 則幫助我們理解業務操作在系統中的流動,特別是在分散式系統中。Trace提供了業務操作跨越不同服務或組件的詳細路徑,幫助我們在 Problem Domain 中確定問題發生的具體位置和影響範圍。
Solution Domain 是指我們用來解決問題或需求的技術和方法。這包括架構設計、技術選型、工具使用等。在這一領域中,遙測信號的作用在於幫助我們驗證和優化解決方案,以確保它們能有效解決問題領域中的需求。
Log 在 Solution Domain 中用於跟踪和驗證解決方案的實施情況。例如,當我們實施一個新的功能或修復一個問題時,log 可以提供即時的反饋,告訴我們系統是否按預期運行,是否解決了問題領域中所定義的問題。
Metric 則幫助我們監控解決方案的整體性能,確保它符合技術限制和業務需求。例如,我們可以使用 Metric 來監控新功能的性能指標,確保它在滿足業務需求的同時,沒有引入新的性能瓶頸。
Trace 在解決方案實施後,幫助我們分析系統內部操作的流動。Trace 可以揭示新的架構設計或技術實現是否導致了意外的性能問題或系統瓶頸,從而幫助我們在 Solution Domain 中進行必要的調整。
Profile 則是用於對程式碼和系統資源使用的深入分析。Profile 能夠幫助我們優化解決方案的性能表現,確保系統運行高效,並符合預定的性能目標。
從 Problem Domain 到 Solution Domain 的過渡過程中,我們可以使用遙測信號來驗證問題的定義和解決方案的設計。例如,我們可以使用 Log 來追踪業務事件,並使用 Metric 來確保解決方案能夠提升這些事件的處理效率。
從 Solution Domain 到 Problem Domain 的反饋過程中,我們可以使用遙測信號來監控技術變更的效果,並確保它們不會對業務流程產生負面影響。例如,我們可以使用 Trace 來分析新的技術實現是否影響了業務操作的流動,並使用 Profile 來優化解決方案的性能表現。
在現代軟體系統中,可觀測性已成為確保系統穩定性和性能的關鍵。Log、Metric、Trace 和 Profile 這四種信號代表了系統監控和診斷的不同層面,各自發展於不同的歷史時期,並且在處理不同類型的系統問題時發揮著互補的作用。
理解這些信號的歷史背景以及它們如何協同工作,對於構建全面的可觀測性策略至關重要。通過統一這四種信號,我們可以實現從宏觀到微觀的全面系統監控,從而更有效地識別和解決系統中的 Known-Unknowns 和未知-未知問題。
遙測信號能夠幫助我們在 Problem Domain 中更準確地識別和理解問題,並在 Solution Domain 中設計出高效的解決方案。同時,Known-Unknowns 和 Unknown-Unknowns 的概念也與 DDD 中的這兩個領域緊密相關,幫助我們在設計和實施解決方案時更好地應對系統中的潛在問題。通過有效利用這些工具和概念,我們可以建置更穩定、高效的系統,並在面對複雜的業務需求和技術挑戰時具備更強的應對能力。
第一天跟最後一天總是特別好寫 :) 能寫得很長又完整。
中間的 28 天就...我就會原形畢露了
Known-knowns 的定義與應用 與Known-Unknowns 的定義與應用 這兩段文字串重複了

