有了模型之後再來就是使用介面了。現在有很多快速提供介面的服務像 ChatOllama、OpenGPTs 和 HuggingChat 等等,不過為了快速體驗整個 GenAI 產品功能,並專注在功能面的發想和參數的設定,在這裡都選擇最簡易的方式,首先從地端 Chatbot 操作開始,我們選擇 LM Studio。
由於模型是在自己的電腦上跑,所以對於硬體設備有一定的要求,在官網上提到的分別是以下:
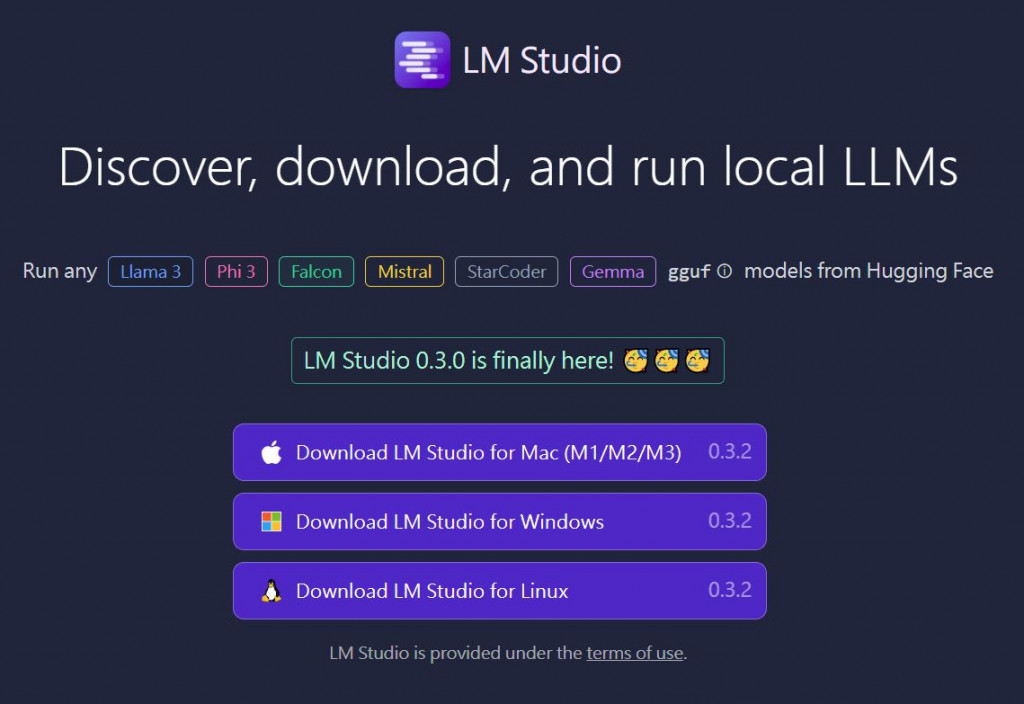
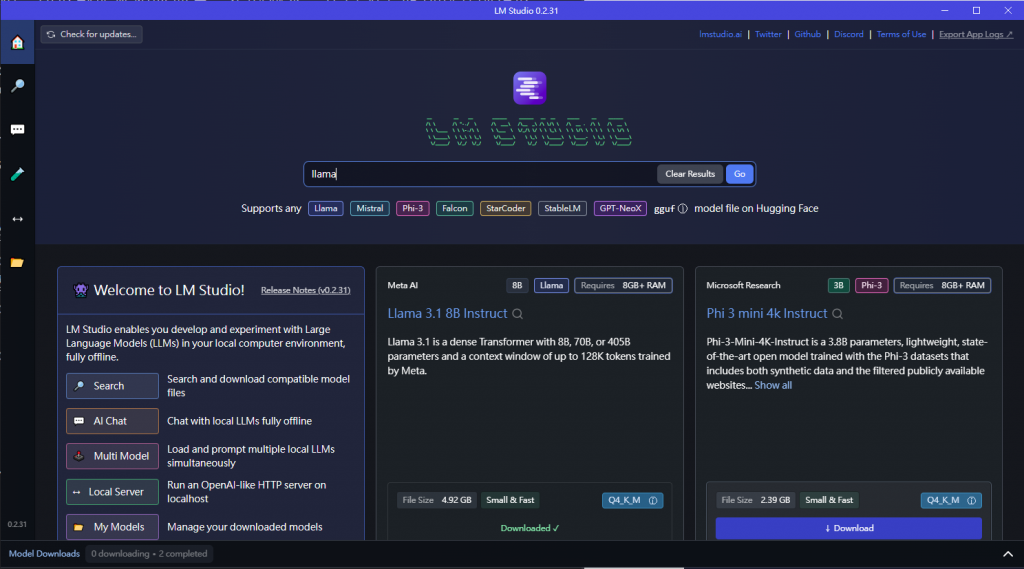
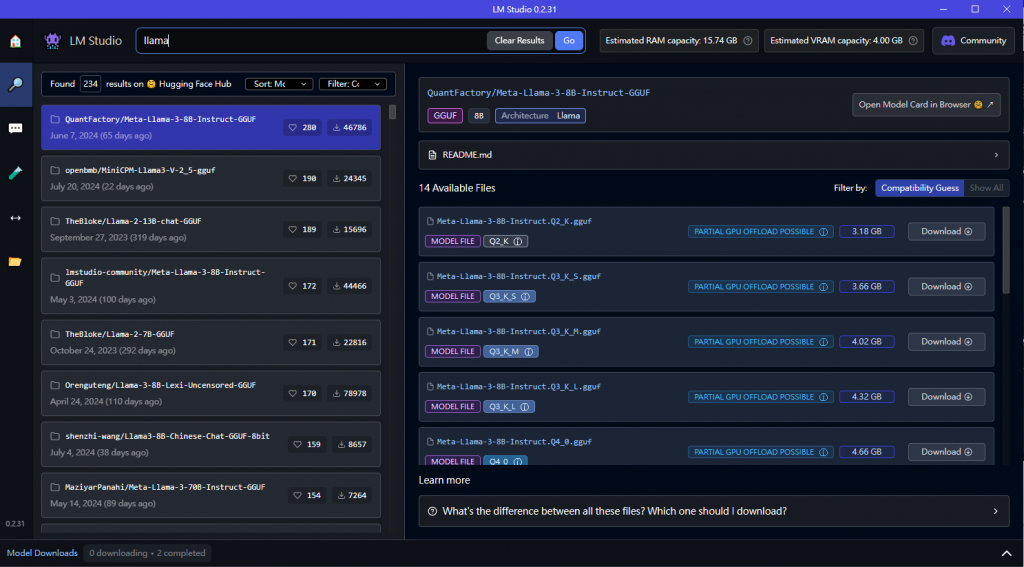
接著來了解 Chatbot 的參數意義,之後在開發上都可以獨立設定或調整:
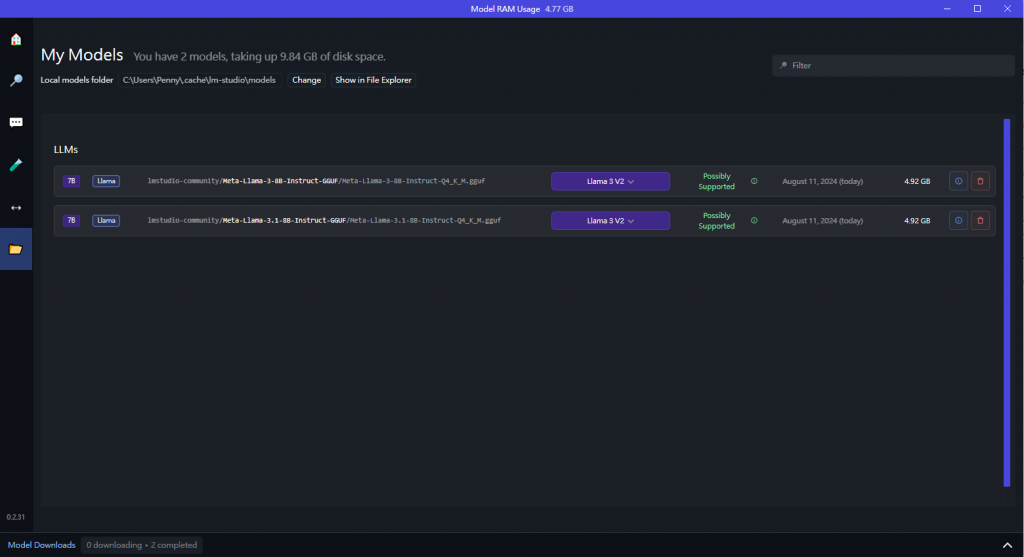
都設定完之後就可以開始問答了,方框左側會顯示目前的資源用量,試了幾次之後會發現模型的回應效果沒有想像中的好,因為能下載的模型參數量小,如果要使用更精確的模型還是得透過 API 串接效能更好的 LLM 模型。


 iThome鐵人賽
iThome鐵人賽