"I implore you, usurp the Vessel. Its supposed strength was ill-judged. It was tarnished by an idea instilled. But you. You are free of such blemishes. You could contain that thing inside."
-- in game Hollow Knight, by The White Lady
我們機械性地重複這些字句,試圖藉著死硬的句子透露一些生活的艱難。
-- <瘟疫>,卡繆著,嚴慧瑩譯
在我們繼續之前不得不再提,這個專案的經歷是非常令人謙卑的過程。在職涯轉換到基層管理者的時期我還不覺得,但現在看起來的確,寫程式的這個技能已經越來越陌生,但相反地強化的是對於自己往日身手的盲目自信。思考的速度、構築解法的技巧性,都顯得鈍化或生鏽;儘管有突如其來補上了的大型語言模型的程式碼生成工具,確實不無小補,但又強化外部依賴而自身未必有什麼提昇。這是他話。
這數年作為基層管理者,已經太習慣直接指示,某些事情應該怎樣進行、完成的樣貌應該如何。雖然也不忘提醒自己 DK 效應的恐怖,以及避免微觀管理的重要性,然而實際上的工作日常,仍然必須展示出自信,才有辦法驅動夥伴。若不是像這樣的私人專案,根本就沒有機會讓自己與自己合作、讓自己管理自己、讓自己監督批評自己。當我在這個專案中一心多用、多工並行,除卻技術上累積的一小步一小步,其餘就是所有的無奈。
好多事情都應該那樣做,但到頭來都(主要由於知識或是技術的不足、次要才是時間與資源)只能呈現出現在的東西。
在 SGF 這件事情,就有些應該做但沒做(或反過來)的方向,列舉如下:
無論如何,仍然紀錄一下它在目前專案之中的樣貌。
其實這也是修修改改一兩次之後的結果了,濃縮成比較好處理的樣貌。
回顧昨日,我給出了目前在 github 上的定義。之所以收斂到這個定義,是根據規則書中玩家回合一節的羅盤階段、角色階段以及標記階段來進行。總得先在羅盤上確定了相對位移(如:兩左一上的總位移量),才能夠據此選定可移動的角色並執行真正的移動(如:上左左),然後才能夠在走過的棋盤格中增加或移除標記。
然而,上述玩家回合的內容,並不包含遊戲設置。因此,除了詳閱規則書,還必須要詳閱 SGF 格式所提供的描述是否能夠兼用。以結果來說,我挪用了一般詰棋題常用的 AW、AB 初始屬性,作為世界版塊的人間、冥界配置,所以有,
;C[Setup0]
AW[aa][ab][ad][ae][bb][bc][bf][ca][cd][ce][dc][dd][df][ea][ec][ee][fa][fb][fe][ff]
AB[ac][af][ba][bd][be][cb][cc][cf][da][db][de][eb][ed][ef][fc][fd]
C 屬性也是通用屬性,是一般的評論使用,比方說可以點評某個著手是否為敗著,或是出乎意料的妙手之類。但由於疫途的遊戲設置有不同的階段,就直接用以描述。
其餘設置階段,姑且略過,可參照上述連結頂端的範例內容。
至於其中的 aa、bc 等等,是 sgf 慣常使用的座標表示法,圍棋用起來很單純,但疫途就需要定義兩塊空間了。
一般的對局著手則會紀錄為
;B[jj][ad][cd][ad][ad][ad][ad]
;W[ii][hh][aa][ab][bb][ab][aa][aa][aa][aa]
以 B 為疫病方,W 為醫療方,是很直覺的對應。這裡,疫病方首步在羅盤上走 jj,定義出了相對位移會是 ij -> jj 的向右橫移一格,所以下一格 ad 標定了疫病方位在人間界的棋子,走向 cd 作為終點。而由規則,可以操作標記物的棋盤格不含終點,所以四個標記物都灑在 ad 上面。
醫療方的羅盤階段著手除了 ii,還有第二個著手 hh 用來標定封城之後將疫病的羅盤指示物從它原本的 jj 轉移到 hh,也因此醫療方的行動實際上是向右向下的。這裡對應到 aa -> ab -> bb(當然也可以選擇 aa -> ca -> cd,但那就是另一盤棋了),以及之後的五個標記物。
有鑑於這是系列文中第一次分享程式碼,我們也建立一下默契。我不會教讀者如何寫 Rust,因為我自己也沒有紮實的根柢和線性的教學材料;這個專案是透過與 ChatGPT 對話、其中包含大量的「我是 C 語言使用者,正在學習 Rust,請問相當於 C 的 xxx 該如何在 Rust 完成」起頭的問題給它。然而,我會貼出可以使用的小型程式碼區塊,但主要以我自己日後參照方便為目的。事實上我相信,只要使用正確或相近的詢問就可以從任何 LLM 得到類似的結果,因為它們似乎是更強大的程式碼片段的教育者(也許可以把它當作伊魯卡老師:如果目標是成為火影,它仍會幫助你,但很笨拙;如果目標是分身術或是吃一碗拉麵,那它是最佳人選)。
是的,這是系列文第一次登場真正由 ChatGPT 生成的程式碼。可惜 ChatGPT 沒有內建的搜尋功能,非常難尋找以前的問答,所以我這裡就直接從 git 歷史紀錄裡面撈取。同首日的目前狀況一節所述,github 上的 PathogenEngine repo 是去年八月之後有一波重構之後的結果,相關的分享或許不在該 repo 當中。
雖然程式碼生成的功能幫助很大,但是也相對應的讓我始終沒有「OK,我會寫 Rust 了!」的感覺。語法外部化了,但 cargo fmt 好用,尚非問題;語意外部化,常常發生 cargo build 之後,關鍵語言符號的 &、mut、* 仍需加加減減的狀況,心裡實在說不上踏實。無可奈何,且戰且走。
首先是讀檔寫檔,可以參考這裡
所以,我也不會強調這些程式碼是最佳解或是實務上就該這麼寫,因為前者不是事實,而後者我沒有答案。
let e = "".to_string();
let mut iter = e.trim().chars().peekable();
let mut t = TreeNode::new(&mut iter, None);
match args.load {
Some(filename) => {
let mut file = File::open(filename.as_str()).expect("Failed to open file");
let mut contents = String::new();
file.read_to_string(&mut contents)
.expect("Failed to read file");
let mut iter = contents.trim().chars().peekable();
t = TreeNode::new(&mut iter, None);
}
None => {}
}
其實是中間的 File::open 和 read_to_string 處理這種小檔案就綽綽有餘,但是 TreeNode 這個自製類別,把樹的資料結構和 SGF 的解析法則綁在一起在 TreeNode::new 方法裡面處理,所以讀檔之後的目的還是直接餵給 TreeNode 類別以生成 t 物件。以往使用 C 語言較多,很少看到方法的串聯,也是這個專案慢慢寫才慢慢有感覺應該期待什麼可以用。
之所以需要都轉成 peekable,是因為我主要需要檢視 SGF 檔案之中的每個字元,同時維護一個狀態機。簡單來說,我主要需要 peek() 方法,僅確認下一個字元而不將之消化;以及 next() 方法,消化當前字元以調整字串游標指向下一個字元。
前述的過度工程,就發生在這個 TreeNode 類別裡面。但還是值得思考我原本的需求:我需要樹的資料結構,而且是子節點可以任意指到樹裡面的某些節點的一種作法。尤其,我懷念 C 語言裡面簡單可用的 NULL,所以在 Rust 裡面需要採用 Option 來替代。簡單總結,需要樹不是重點,重點是怎麼樣在層層疊疊的 Rust ownership 裡面串出可以亂指的資料結構。所謂可以亂指,意指,除了樹狀結構圖展示的那種關聯性方向由根節點指向它子節點再一路指到所有端點之外,我仍然會需要子節點向前回溯到親節點的指標。
從工程面回顧這個專案遭遇的挑戰,各有有趣的地方,到頭來還是吉藏凶、凶藏吉。比方說,我在程式碼註解當中,以及文中認為
TreeNode相關部份是過度工程,這儘管大可是事實,但這並不包含前述的回溯親節點指標的功能。當初的著眼點,在於認真符合 SGF 的規格乃至於能夠實作出樹狀結構,正如一開始提及的多重宇宙一樣。事實是,我無能在時限前將這一點化為現實,但這一點在後續蒙地卡羅模擬的實作時,派上了用場。
最終,我沒有認真認識 Box 或其他的 smart pointer 怎麼使用,而是用了一個看起來很通用的東西。範例如下:
use std::rc::Rc;
use std::cell::RefCell;
#[derive(Debug,PartialEq)]
struct Node {
s: String,
l: Option<Rc<RefCell<Node>>>,
}
impl Node {
fn new(s: String) -> Node {
return Node {
s: s,
l: None,
};
}
}
fn main() {
let n0 = Rc::new(RefCell::new(Node::new("1234".to_string())));
let n1 = Rc::new(RefCell::new(Node::new("5678".to_string())));
n0.borrow_mut().l = Some(n1.clone());
n1.borrow_mut().l = Some(n0.clone());
println!("{:?}",n0.borrow().s);
println!("{:?}",n0.borrow().l.as_ref().unwrap().borrow().l.as_ref().unwrap().borrow().s);
}
可以直接上 Rust Playground 去試運行,就會看到 1234 節點兜了 5678,5678 又兜到 1234,所以最後兩行都會印出 1234。但也可以看到
l: Option<Rc<RefCell<Node>>>的囉唆性。雖然有三個後續呼叫(as_ref、unwrap、borrow),但很不直覺的,他們並非對應到Node之外的三層包裝。理由很迂迴(我所理解的部份,但仍可能不夠精確。仰賴大量實驗):
as_ref() 的意義:將 Option<Rc<RefCell<Node>>> 作成 Option<&Rc<RefCell<Node>>>。直接進行後面的 unwrap() 方法的話,會觸發 Rust 的 E0507,因為這個拆包(unwrap)的舉動沒有尊重 l 以及裡面的東西都屬於 n0。使用了 as_ref() 之後,可以將之作為不可改變的參照,也就不會違背借用(borrow)的規則。另外,由於 Rc<RefCell<_>> 的特性,也可以使用 clone() 方法直接複製。unwrap() 的意義:這比較容易理解,就是將 Option 物件拆去表層,然而這其實是危險的作法,因為有可能它是空指標(None,我完全以 C 的 Null 在理解它)。所以理論上,expect("error while unwrapping") 比較合適。無論如何,這個結束之後,相當於是成為 &Rc<RefCell<Node>> 型別的物件繼續傳遞。borrow():就像更前面行數的 n0 等物件的宣告一般,它們在被使用的時候需要被借用,意義上相當於拆包兩層(Rc<RefCell<_>>)、終於能夠使用 Node 類別的成員的功能。另外也有 borrow_mut() 這個代表借了之後可以修改內容的變種。以這些認知為基礎,再加上 SGF 的認知,就兜出了 tree.rs 裡面那些我不敢動的內容。事實上,曾經使用過類似 valgrind 之類的工具去觀察,這裡 memory leakage 好像也蠻多的,但還沒有力氣去檢查。
我在去年 2 月底,啟動專案之後不久,就寄信給 SGF 格式的維護者。他回信說可以幫疫途保留 GM[41],也就是官方列案在冊的第 41 號遊戲,但後來就沒有下文了,至今聯絡不上。
持續收集對局資料當中。雖然已經累積了幾個世代的訓練量,但仍然沒有看到它學會了什麼有效的策略提昇勝率,雖然它仍然是對規則有一點點感覺了。
我真摯的友人,同時也是自予焦啦系列以來忠實的讀者與校驗者阿傑,昨日私訊我說他看不懂我的圖表,我回之以,「沒關係,我也不懂」。我不確定我們不懂的理由各自為何,但在這裡,不懂可以有不同的層次。
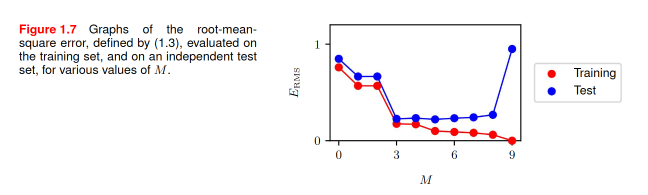
最初階的話,就是不同 dataset 之間的用途差別(可見 wiki)。最基本的分法是訓練用的資料集和驗證用的資料集。通常,我們總是可以預期訓練曲線隨著深度學習演算法一次次地更新模型權重,而觀察到針對訓練資料集(training set)的損失值的平緩下降;但這時候比對用的驗證資料集(validation set),就可以當作對照,檢驗一個模型在逐漸了解訓練集合的內容的時候,是不是開始背答案了。一個尋常的模式是微笑曲線的弧頂,即是普及性(在訓練集中學會的知識有助於同時降低計算驗證集的時候的損失值)以及過度擬合(overfitting)的狀況,如下圖,截自 Chris Bishop 的 Deep Learning: Foundations and Concepts,
然而對照昨天的三張圖,這一張怎麼會有那種「頓悟」的瞬間?但是看得我好興奮又好困惑啊!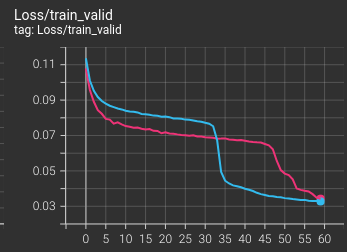
驗證用的集合根本就是穩步上升,絲毫不見損失下降。這是不是表示根本沒有學會東西?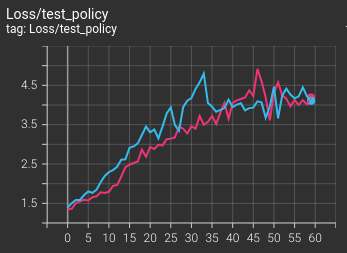
只有這張比較符合教科書上的訓練集模式: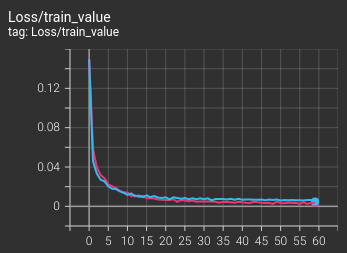
到底有沒有在學啊?各位讀者當然是很好奇的,殊不知我與各位的差別也只是,我在搖滾區切身地煩惱著,還是應該說祈禱比較恰當?希望在這混沌的深海中搜索,終究能夠找到某只蚌殼內的珍珠......
回到今天的進度。我必須很誠實的告訴各位,今天我全部都在蒐集資料。工作天果然還是很沒辦法處理什麼,一天大概偶爾檢查一下是不是 idle 了,是的話就讓它繼續自我對局收集對局資料。


 iThome鐵人賽
iThome鐵人賽