除了升級 cluster 之外,為了避免意外情況而造成資料遺失,「備份」也是一個相當重要的工作。養成定期備份的習慣,可以在資料遺失快速的透過「還原」來恢拯救系統。
在 cluster 中,需要重點備份的資料有:
在過去的操作中,不外乎就是透過以下兩種方式來建立資源:
在 Day 04 中曾經提到過,使用 yaml 雖然速度不像「直接使用指令」那麼迅速,但是在做「版本控制」時會輕鬆許多,畢竟我們很難掌握到底是誰、什麼時候、用什麼指令建立的資源。透過版控系統,例如 git,可以讓我們清楚的知道每一次的變更,也能在資遺失時快速的復原。
但是有時我們仍會使用指令來建立資源,所以在備份時,我們可以透過以下方式將資源設定檔備份下來:
kubectl get all --all-namespaces -o yaml > all-resources.yaml
需要注意的是,這樣的備份方式較為簡略,並不能做到「全面」的備份。
要做到較為全面的備份,就必須備份 etcd。
etcd 是 k8s 的資料庫,使用 key-value 的方式來儲存 k8s 的重要資料和關鍵訊息,例如: 現有資源、 cluster 狀態等等。
備份 etcd 的方式有很多種,這裡介紹一種簡單且迅速的方式:snapshot。
透過 etcd 的「command line client」--- etcdctl,我們可以用 snapshot(快照) 將 etcd 的資料備份下來,快照檔通常用「.db」結尾,在日後就可以用這個快照檔還原 etcd。
備份與還原的基本流程圖如下: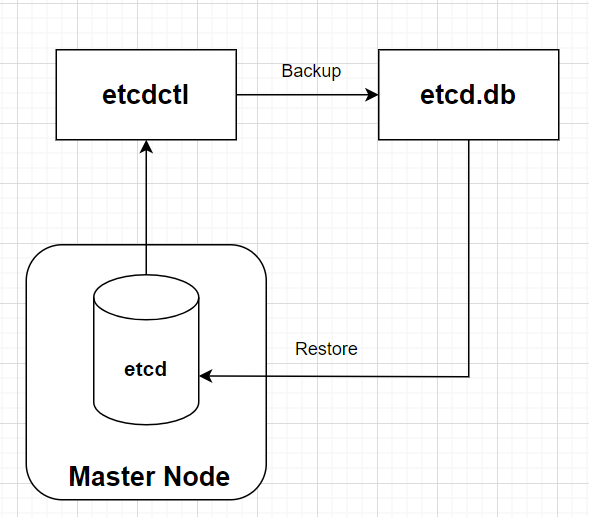
為了實測備份後還原的效果,這裡先建立一個 Deployment:
kubectl create deployment nginx --image nginx --replicas 3
要使用「etcdctl」,需要先將環境變數設定好:
export ETCDCTL_API=3
現在就可以來準備備份 etcd 了。而建立 snapshot 的指令格式如下:
etcdctl --endpoints=<listen-client-urls> \
--cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> \
snapshot save <backup-file-location>
因此,我們需要找出 etcdctl snaptshot 所需的資料:
cat /etc/kubernetes/manifests/etcd.yaml | grep listen-client
- --listen-client-urls=https://127.0.0.1:2379,https://172.30.1.2:2379
cat /etc/kubernetes/manifests/etcd.yaml | grep file
- --cert-file=/etc/kubernetes/pki/etcd/server.crt # 需要這行
- --key-file=/etc/kubernetes/pki/etcd/server.key # 需要這行
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt # 需要這行
我們所需的資料有:
/opt/etcd-backup.db:etcdctl --endpoints=127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot save /opt/etcd-backup.db
etcdctl snapshot status /opt/etcd-backup.db
c08eb2c6, 2129, 2145, 5.6 MB
備份完成後,我們來看看如何透過 snapshot 還原 etcd。
kubectl delete deploy nginx
etcdctl snapshot restore --data-dir /var/lib/etcd-restore /opt/etcd-backup.db
mv /etc/kubernetes/manifests/* /root
由於我們將 etcd 資料還原在一個新目錄「/var/lib/etcd-restore」,所以我們需要修改 etcd 的 manifest,把 etcd 的資料讀取路徑改到新的目錄,這樣還原才會生效:
vim /root/etcd.yaml
# 通常在 etcd.yaml 中的最下面
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /var/lib/etcd-restore # 改這裡(原本這裡是/var/lib/etcd)
type: DirectoryOrCreate
name: etcd-data
status: {}
mv /root/kube* /etc/kubernetes/manifests
mv /root/etcd.yaml /etc/kubernetes/manifests
kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-75bdb5b75d-zhhrq 1/1 Running 5 (92s ago) 2d17h
canal-fzfpm 2/2 Running 2 (18m ago) 2d17h
canal-szcfj 2/2 Running 2 (18m ago) 2d17h
coredns-5c69dbb7bd-298pn 1/1 Running 1 (18m ago) 2d17h
coredns-5c69dbb7bd-f6vzw 1/1 Running 1 (18m ago) 2d17h
etcd-controlplane 0/1 Pending 0 62s
kube-apiserver-controlplane 1/1 Running 0 2d17h
kube-controller-manager-controlplane 1/1 Running 0 2d17h
kube-proxy-ffdml 1/1 Running 1 (18m ago) 2d17h
kube-proxy-mvqrk 1/1 Running 2 (18m ago) 2d17h
kube-scheduler-controlplane 1/1 Running 0 2d17h
OK,已經都成功啟動了,現在來檢查一下剛剛刪掉的 nginx deployment 是否有被還原回來:
kubectl get deploy nginx
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 3/3 3 3 7m15s
還原成功!
Tips
在等待 etcd 重啟的過程中,我們可以透過以下指令來確認 etcd 的狀態:
crictl ps -a
or
docker ps -a
etcd 成功回來的畫面如下:
crictl ps -a | grep etcd
f01e04b99dbc1 a0eed15eed449 45 seconds ago Running etcd 0 c500b94347239 etcd-controlplane a26
如果 etcd 不斷地重啟失敗,可能是上面有某部分的操作失敗了,建議用「crictl ps -a」與「 crictl logs 」來除錯。
今天示範了如何備份 etcd 與還原,熟悉操作與「官方說明文件」(Operating etcd clusters for Kubernetes後其實也不用特別記指令,直接查就OK了。
參考資料
Operating etcd clusters for Kubernetes

