本系列文章部分內容由AI產生,最後皆有通過人工確認內容及潤稿。
在昨天我們了解了人工智能(AI)和機器學習(ML)的基本概念。今天,我們將深入探討深度學習(Deep Learning),這是推動AI發展的核心技術之一。深度學習已在圖像識別、語音識別和自然語言處理等領域取得了突破性成果。
今天有別以往,我將提供今天的學習目標給大家,讓大家在閱讀文章之前心裡可以有個目標。
深度學習是機器學習的一個分支,基於多層人工神經網絡,模仿人腦的結構和功能,能夠自動從數據中學習特徵表示。
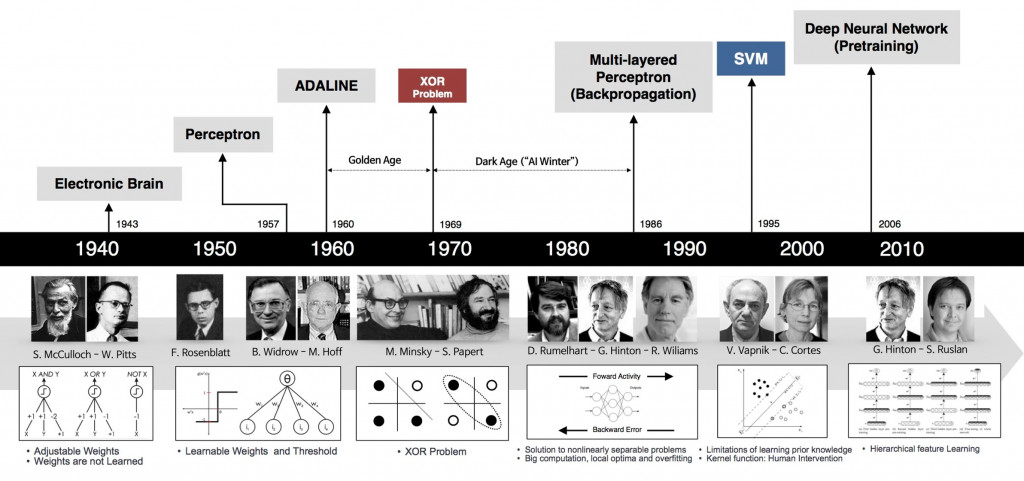
圖1 深度學習的發展歷程
人工神經元是模仿生物神經元的計算模型,主要包括以下部分:
激活函數(Activation Function)引入非線性,使神經網絡能夠學習複雜的模式。以下是常見的激活函數。
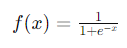
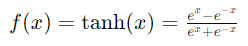
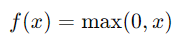
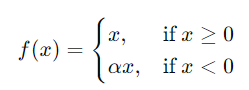
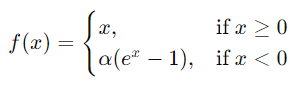
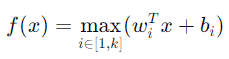
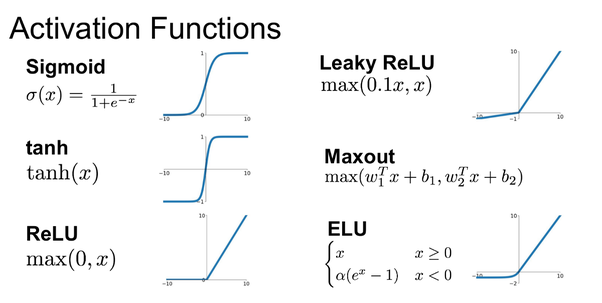
圖3 常見激活函數曲線
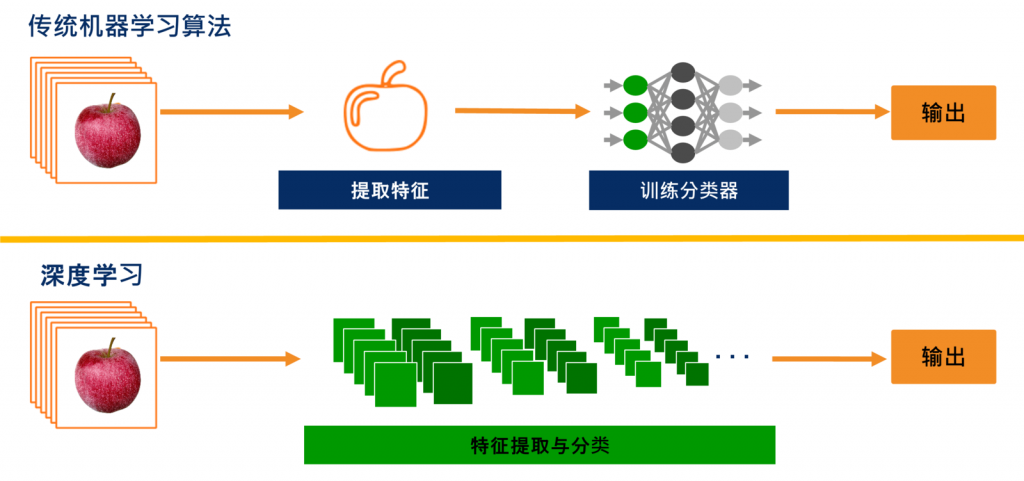
為了方便構建和訓練深度學習模型,開發者通常使用專門的深度學習框架。以下是兩個最流行的框架:


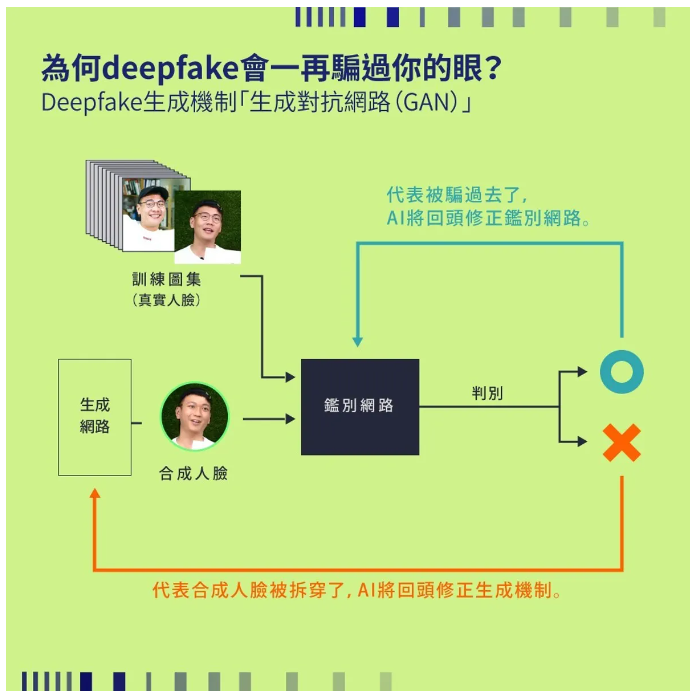
深度學習是實現AI換臉技術的核心。通過深度神經網絡,特別是生成對抗網絡(GAN),我們能夠生成逼真的人臉圖像,實現換臉效果。
通過今天的學習,我們深入了解了深度學習的概念、結構和應用,並詳細探討了各種激活函數及其特性,這對理解和構建神經網絡模型至關重要。深度學習為我們開啟了新的可能性,未來我們將進一步探討生成式模型和具體的換臉技術實現。
那我們就明天見!
圖1 來源 History of deep learning
圖3 來源 Introduction to Exponential Linear Unit
圖4 來源 传统视觉方法与深度学习
圖5 來源PyTorch vs TensorFlow – Which to Pick ?
圖6 來源關於影像辨識,所有你應該知道的深度學習模型
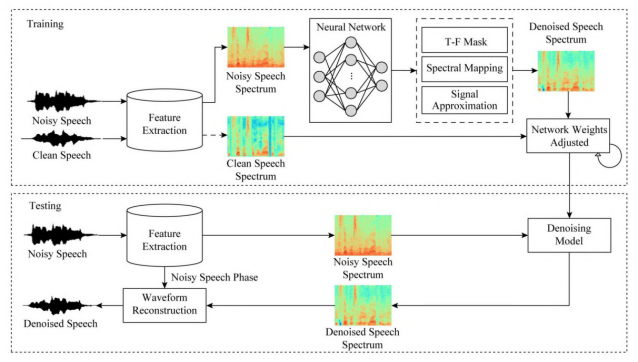
圖7 來源深度学习在语音增强中的应用
圖8 來源Deepfake大解密!「換臉」技術更簡單,到底怎麼辦到的?


 iThome鐵人賽
iThome鐵人賽