在未來的某一天,你有沒有想過,當我們打開電影、廣告甚至新聞節目時,看到的那些面孔、聽到的那些聲音,很可能不是真實存在的人?AI技術日新月異,尤其是Deepfake的技術,感覺好像很複雜,但簡單來說,這些都是讓AI「學會模仿」和「學會創造」的工具。今天,我們就來聊聊這些技術是如何運作的吧。
一、生成對抗網絡(GAN):Deepfake的核心驅動力
什麼是Deepfake?
合成某個(不一定存在的)人的圖像或影片、甚至聲音,讓整體看起來很自然、我們也辨認不出它的真假,這種栩栩如生底下的技術主要源自於Generative Adversarial Networks(GAN)
原理:
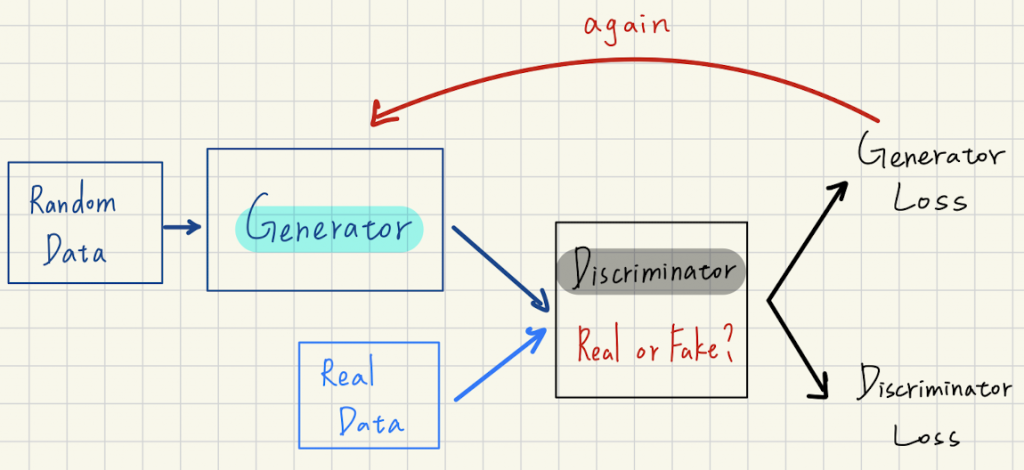
GAN是一種深度學習架構,主要為訓練兩個不同的網絡並使它們相互對抗。
A網絡從資料集取得輸入,它會盡可能地修改並產生新資料,而B網絡會嘗試預測這個資料輸出是否屬於原始資料集。A不斷地取資料來修改、B不斷地去預測及猜測該資料是否來自於原始資料庫(也就是分辨虛擬或真實),直到B再也無法區分虛假與原始資料,Deepfake的影片或照片就這樣生成了。其中,不斷修改資料的A網絡被稱為生成器(Generator),反之,B被稱為鑑別器(Discriminator)。
例如,A以一個人臉作為輸入並改變他的表情由微笑變成露齒笑,B就會收到好幾筆資料,都是同一人但有好幾種表情的圖片,其中只有露齒笑的那張是假照片,B必須試圖找到那張唯一假的表情,否則就算A獲勝。
二、RNN與LSTM:處裡序列數據
LSTM(長短期記憶網絡):
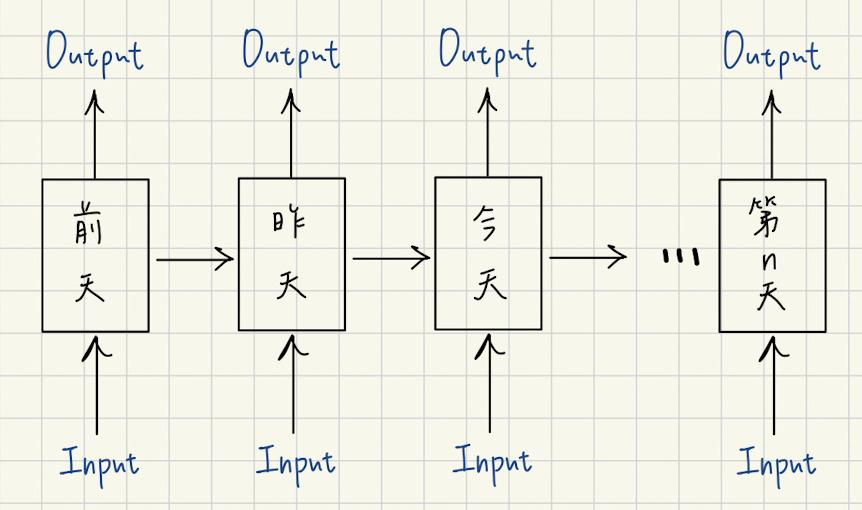
是RNN的進階版,為了解決RNN無法擁有長期記憶的問題。而LSTM的架構多了遺忘門(決定什麼資料要忘掉)和記憶單元(什麼資料該記住),能夠更好地記住長時間序列中的重要信息,同時忽略不重要的部分。
應用
主要用於處理連續幀,使得影片中的動作和表情更加連貫自然,更是確保了Deepfake中的面部表情和動作在時間維度上保持一致,增強了影片的真實感。
此外,有別於其他神經網絡,它們能一次處理多組輸入或一次產生多組輸出,讓神經網絡不在只能處理分類問題。
例如:一組輸入多組輸出時,就可以將圖片自動標上文字。多組輸入一組輸出則可以處理文本的情感理解,像是從一段文章中知道是正面或反面的結果。而多組輸入,多組輸出時,就可以自動翻譯。
三、人臉對齊的基本技術
AI必須能夠實現人臉在不同角度和光線下的精確對位,才能讓影片每個瞬間都能無縫換臉、讓影片更真實順暢,如何對齊影片中的人臉就是至關重要的一環。
特徵點定位:識別人臉上的關鍵特徵點,如眼睛、鼻子、嘴巴的位置
68點或5點模型(如:Dlib)來檢測面部特徵點,點越多就能更詳細檢測臉部。
面部對齊:根據特徵點將人臉圖像轉換到標準坐標系中。
現在網路上不少照片或影片都是由AI所生成,到目前為止我們都還能通過人眼分辨、糾出他們影片或照片中不自然的地方,從影片中的面部細節,到動作的自然連續,甚至捕捉面部表情的小細節,每個環節AI都有可能出錯。雖然現在的技術或許還有待加強,不過隨著AI一次一次的更新學習、技術不斷成熟後,我們不可否認AI可能有一天會取代影視業。

