昨天提到了一個Q-learning中的策略 Epsilon-greedy 策略,那這個東西到底是甚麼呢?他跟Q-learning有甚麼關係呢?今天的文章就會介紹,接著會將昨天的程式繼續完成,那我們接著往下看吧。
在強化學習中,代理人需要在「探索」和「利用」之間取得平衡。「探索」是指嘗試新的行動,以期望發現更好的獲取獎勵的方法;而「利用」則是基於當前的經驗,選擇已知的最佳行動來最大化當前的回報。
epsilon-greedy 策略是一種簡單且常用的方式來實現這個平衡。在該策略中,代理人會以一定的機率  進行「探索」,即隨機選擇一個行動;而以機率
進行「探索」,即隨機選擇一個行動;而以機率 進行「利用」,即選擇目前 Q-table 中獲取回報最高的行動。這樣代理人既能嘗試新的策略,又能根據已有的經驗做出最佳決策。
進行「利用」,即選擇目前 Q-table 中獲取回報最高的行動。這樣代理人既能嘗試新的策略,又能根據已有的經驗做出最佳決策。
看到這裡,不知道大家有沒有注意到昨天的初始化的時候就有用到epsilon呢?昨天說到epsilon是用來控制代理在選擇行為時隨機性(探索)與基於 Q 表的策略(利用)的平衡。
也就是說,透過 epsilon-greedy 策略,我們能夠有效地解決「探索」與「利用」的權衡問題。若只進行探索,代理人可能無法充分利用已知的最佳行動;而若只進行利用,代理人可能會錯失學習到更好策略的機會。因此,epsilon-greedy 策略能夠在這兩者之間取得平衡,特別是在 Q-Learning 的早期階段尤為重要。
在 Q-Learning 中,我們透過不斷更新 Q 表來讓代理人學會選擇最優的行動,但若代理人只根據已知的 Q 值進行行動,可能會過早陷入一個次優解中,而錯過了潛在的更高獎勵。這時,epsilon-greedy 策略就能發揮作用。
假設我們設置一個 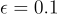 ,這意味著每次選擇行動時,代理人有 10% 的機率進行隨機選擇,90% 的機率根據 Q 表選擇最優行動。隨著學習的進展,我們可以逐漸減少 ,讓代理人更多地依賴已經學到的知識,逐步從「探索」過渡到「利用」。
,這意味著每次選擇行動時,代理人有 10% 的機率進行隨機選擇,90% 的機率根據 Q 表選擇最優行動。隨著學習的進展,我們可以逐漸減少 ,讓代理人更多地依賴已經學到的知識,逐步從「探索」過渡到「利用」。
知道了這個後,應該就對於我們的訓練功能更了解了吧~ 那接著我們就要繼續完成我們剩餘的部分。
self.epsilon = max(self.epsilon - self.epsilon_decay_rate, 0)
if self.epsilon == 0:
self.alpha = 0.0001
if reward == 1:
rewards_per_episode[i] = 1
self.env.close()
# 關閉環境
self.plot_rewards(rewards_per_episode, episodes)
# 繪製每個回合的獎勵情況圖,方便視覺化觀察代理人的學習進展。
self.save_q_table("result.pkl")
# 將最終學到的 Q 表保存到檔案 "result.pkl" 中,這樣下次可以直接讀取,不需要重新訓練。
self.epsilon = max(self.epsilon - self.epsilon_decay_rate, 0)
這一行的作用是隨著訓練過程的進行,逐漸減少 epsilon 的值。epsilon_decay_rate 是一個設定好的衰減率,隨著每個回合的進行,epsilon 會慢慢減少,最終達到 0。
這種設計反映了 epsilon-greedy 策略中的「探索」與「利用」之間的平衡。在訓練初期,epsilon 值較大,代理人會更多地進行「探索」;隨著訓練的進行,代理人逐漸減少隨機行動,更多地進行「利用」,從而更依賴 Q 表中所學到的策略。
當 epsilon 減少至 0 時
當 epsilon 減少至 0 時,程式碼會將學習率 alpha 調整到非常小的值(0.0001)。這意味著當代理人完全不再進行隨機探索時,它的 Q 值更新速度會顯著減慢。
這樣做的原因是,在訓練的後期,代理人已經學到了足夠多的知識,並不需要頻繁地更新 Q 值。通過減少 alpha,代理人能夠更穩定地遵循學到的最佳策略,而不會因為較高的學習率而過度調整現有的 Q 表。
rewards_per_episode[i] 設置為 1,這可以用來在後續進行統計和視覺化處理,幫助觀察模型在訓練過程中的表現。def plot_rewards(self, rewards, episodes):
sum_rewards = np.zeros(episodes)
# 初始化累積獎勵陣列
for t in range(episodes):
sum_rewards[t] = np.sum(rewards[max(0, t-100):(t+1)])
# 計算每回合的累積獎勵
plt.plot(sum_rewards)
# 繪製累積獎勵曲線
plt.savefig('frozen_lake8x8.png')
# 儲存圖像
在程式碼最開始,我們給定了這個函數兩個參數
def save_q_table(self, file_name):
with open(file_name, 'wb') as f:
pickle.dump(self.q_table, f)
在這邊我們將結果儲存取名為帶入的file_name
接著下面的pickle 是 Python 的內建模組,專門用來序列化和反序列化 Python 物件。序列化的意思是將物件(如列表、字典或在這裡的 Q-table)轉換為二進位格式,以便儲存到檔案中或傳輸到其他系統。反序列化則是將二進位格式轉換回 Python 物件。
今天針對這幾項部分繼續進行補充說明,並且說明了Epsilon-greedy Strategy,相信這些部分大家應該也都更了解了。
(題外話:這幾天真的是太忙了,文章庫存也一天天見底。)
(誤)

