
經過 Day 05 的討論,我們已經瞭解資料倉儲、資料湖及資料湖倉的差異了,今天我們進一步來談談資料倉儲的內部架構。
Day 04 提到資料收集步驟是針對內部資料源或外部資料源進行採集,收集之後會有匯入、轉換等流程。然而,分析情境千變萬化,我們不能期待一個轉換招式打天下,為了保留擴充性滿足已出現或未出現的各種需求在進行轉換時,不能一步到位,得要按部就班。
其中,最廣受歡迎的就是三步驟轉換,其架構也被稱為「三層式架構」。
典型的資料倉儲三層次分別為:原始資料層 (raw data layer)、處理資料層 (processed data layer) 以及分析資料層 (analytical data layer)。以下會和 Delta Lake 提出的獎章架構 Medallion Architecture 整合討論。
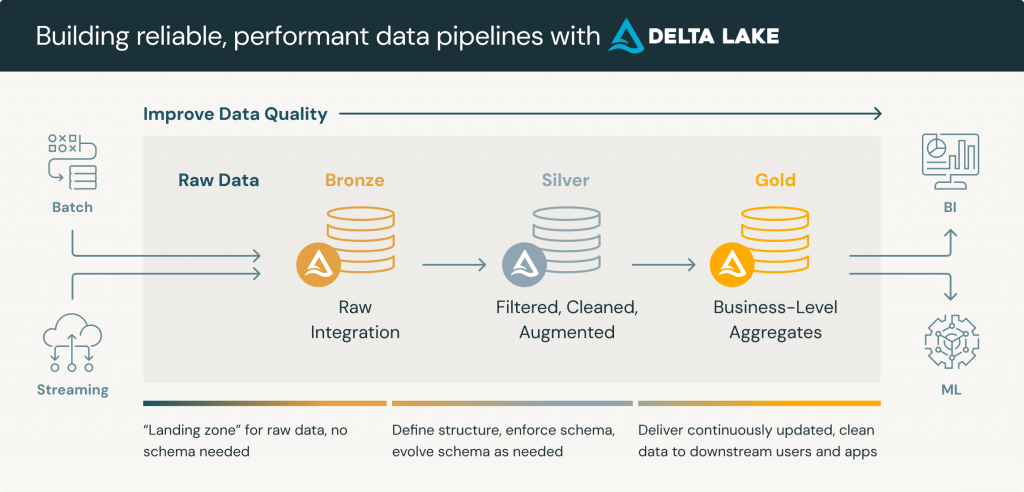
Source: https://www.databricks.com/glossary/medallion-architecture
【原始資料層 | Staging Layer | Bronze Layer】
由於資料源可能是企業內部的營運資料庫或外部資料,為了避免定義 schema 成為 data pipeline 的開發瓶頸,會傾向以原始型態儲存資料。這層的資料表結構可以單純的只有 id 和相關時間戳 created_at, updated_at ,剩餘的資料都用 json 字串格式存在 data 欄位。
其餘特性包含:
【處理資料層 | Intermediate Layer | Silver Layer】
在分析資料層中,資料經過清理和結構化 (解構 data 欄位) 等精煉處理,準備好成為分析與查詢的後盾。其餘特性包含:
GROUP BY 算出必要的統計值,但不會和其他主題表做 JOIN 避免提早耦合。
【分析資料層 | Mart Layer | Gold Layer】
分析資料層就是針對業務需求進行設計了,處理資料層選取跨主題進行 JOIN、GROUP BY 等統計聚合,甚至更複雜的時間分析都是可能的。資料會被組織成最終使用者易於理解和存取的結構。
其他特性包含:
讓我們再以網購平台作為案例。資料分析師提出希望以 RFM 模式對顧客進行分群分析,掌握既有客群的消費模式。這個模式需要的資訊是:
資料工程師聽完說明後,理解這個模型需要顧客與訂購資料兩個主題的資料。於是轉身詢問後端工程師業務資料庫的結構,得到資訊如下:
顧客表 users:包含顧客 id、顧客姓名、註冊時間等
訂購資料表 orders:包含訂單 id、顧客 id、下單時間、下單金額等
根據接收到的資料長相
# users
{
"id": "1",
"data": {
"user_name": "Alice",
"email": "alice524@gmail.com",
"signup_date": "2020-01-01",
"status": "active",
"other_fields": "..."
},
"created_at": "2020-01-01T00:00:00Z",
"updated_at": "2020-01-01T00:00:00Z"
} ...
# orders
{
"id": "2",
"data": {
"user_id": 1,
"ordered_at": "2020-01-01T12:00:00Z",
"order_amount": 100,
"other_fields": "..."
},
"created_at": "2020-01-01T12:00:00Z",
"updated_at": "2020-01-01T12:00:00Z"
} ...
以下就是資料倉儲內各層的內容
【Bronze Layer】 以接近原始狀態的資料直接匯入
CREATE TABLE bronze.users (
user_id INT,
data STRING,
created_at TIMESTAMP,
updated_at TIMESTAMP,
_processed_at TIMESTAMP
);
CREATE TABLE bronze.orders (
order_id INT,
user_id INT,
data STRING,
created_at TIMESTAMP,
updated_at TIMESTAMP,
_processed_at TIMESTAMP
);
【Silver Layer】 進行結構化,解構資料欄位
CREATE TABLE silver.users (
user_id INT,
user_name STRING,
email STRING,
signup_date DATE,
status STRING,
created_at TIMESTAMP,
updated_at TIMESTAMP,
_processed_at TIMESTAMP
);
CREATE TABLE silver.orders (
order_id INT,
user_id INT,
ordered_at TIMESTAMP,
order_amount DECIMAL(10, 2),
created_at TIMESTAMP,
updated_at TIMESTAMP,
_processed_at TIMESTAMP
);
同時我們發現,RFM 的資料都跟 orders 有關,所以我們針對 silver.orders 進行 GROUP BY ,算出最近一次日期、購買頻率與購買金額。
CREATE TABLE silver.rfm_aggregates (
user_id INT,
last_order_date DATE, --最近一次日期
order_count INT, --購買頻率
total_spent_amount DECIMAL(10, 2) --購買金額,
_processed_at TIMESTAMP
);
-- Transformation Logic
SELECT
user_id,
MAX(ordered_at) AS last_order_date,
COUNT(order_id) AS order_count,
SUM(order_amount) AS total_spent_amount,
TODAY() AS _processed_at
FROM
`silver.orders`
WHERE
{condition}
GROUP BY
user_id
;
【Gold Layer】 最後進入商業邏輯的部分,這個模型只取狀態仍是 active 的顧客訂單進行計算,因此要把 silver.rfm_aggregates 和 silver.users 進行 JOIN 才能得知顧客狀態。
CREATE TABLE gold.rfm (
user_id INT,
recency INT,
frequency INT,
monetary DECIMAL(10, 2),
_processed_at TIMESTAMP
);
-- Transformation Logic
SELECT
users.user_id,
DATEDIFF(TODAY(), aggregates.last_order_date) AS recency,
aggregates.order_count AS frequency,
aggregates.total_spent_amount AS monetary,
TODAY() AS _processed_at
FROM
`silver.rfm_aggregates` AS aggregates
LEFT JOIN
`silver.users` AS users
ON
aggregates.user_id = users.user_id
WHERE
users.status = 'active'
;
算出所有活躍顧客的 R、F、M 三個維度之後,進一步將各個維度用中位數切開,優於中位數的表現得 2 分,低於中位數的表現得 1 分。
CREATE TABLE gold.rfm_scores (
user_id INT,
user_name STRING,
user_email STRING,
user_signup_date DATE,
recency_score INT,
frequency_score INT,
monetary_score INT,
rfm_score INT,
_processed_at TIMESTAMP
);
-- Transformation Logic
WITH rfm_data AS (
SELECT
user_id,
recency,
frequency,
monetary,
PERCENTILE_CONT(recency, 0.5) OVER() AS recency_median,
PERCENTILE_CONT(frequency, 0.5) OVER() AS frequency_median,
PERCENTILE_CONT(monetary, 0.5) OVER() AS monetary_median
FROM
`gold.rfm`
),
rfm_scores AS (
SELECT
user_id,
CASE
WHEN recency <= recency_median THEN 2
ELSE 1
END AS recency_score,
CASE
WHEN frequency >= frequency_median THEN 2
ELSE 1
END AS frequency_score,
CASE
WHEN monetary >= monetary_median THEN 2
ELSE 1
END AS monetary_score,
TODAY() AS _processed_at
FROM
rfm_data
)
SELECT
rfm_scores.user_id,
users.user_name,
users.email AS user_email,
users.signup_date AS user_signup_date,
rfm_scores.recency_score,
rfm_scores.frequency_score,
rfm_scores.monetary_score,
(recency_score + frequency_score + monetary_score) AS rfm_score,
TODAY() AS _processed_at
FROM
rfm_scores
LEFT JOIN
`silver.users`
ON
rfm_scores.user_id = users.user_id
;
至此我們就能從 gold.rfm_scores 這張表裡,得出每個顧客的 RFM 分數,可以據此對他們進行分眾行銷了!
我們可以從資料血緣圖看看從業務資料庫的原始資料到最終分析資料這長長的 data pipeline,資料到底歷經了什麼樣的流轉。
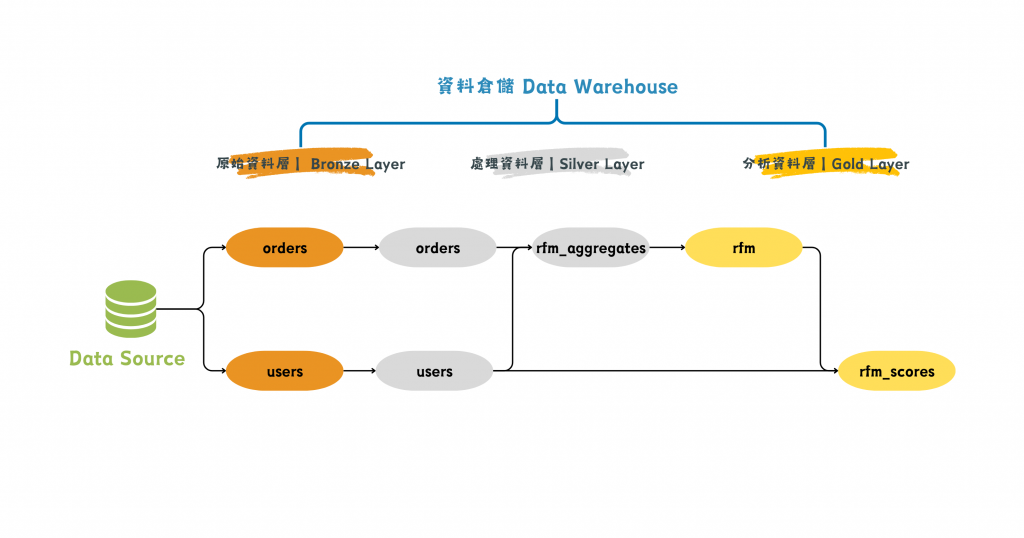
圖/展示出資料流轉歷程的資料血緣圖。簡書廷製。
試想,如果我們為了 RFM 模型 ,連同只取 status = 'active' 的邏輯直接用一個複雜的 SQL 將所有資料轉換完成,當資料出現不合理狀況時,要梳理問題就不容易了。觀察實體資料還是比讀一段過長的 SQL 簡單一些。
分層架構不只是一個概念,也是一種 data pipeline 設計的策略:經過適度的拆分,將可共用的邏輯或資料表抽取出來,建構起來的資料倉儲才會容易擴展且方便維護。分層架構還有以下特性:
參考資料


 iThome鐵人賽
iThome鐵人賽