連載要滿一星期了,又回到 Day 03 的職棒官網故事。如果是 20 年看球背景的老球迷,應該會發現 "Lamigo" 穿越時空進到 2007 年的戰績表裡了。當時正確的隊名還叫做 Lanew 熊,Lamigo 是 2011 年開始的新隊名。感覺一定是哪個地方 JOIN 出錯了!
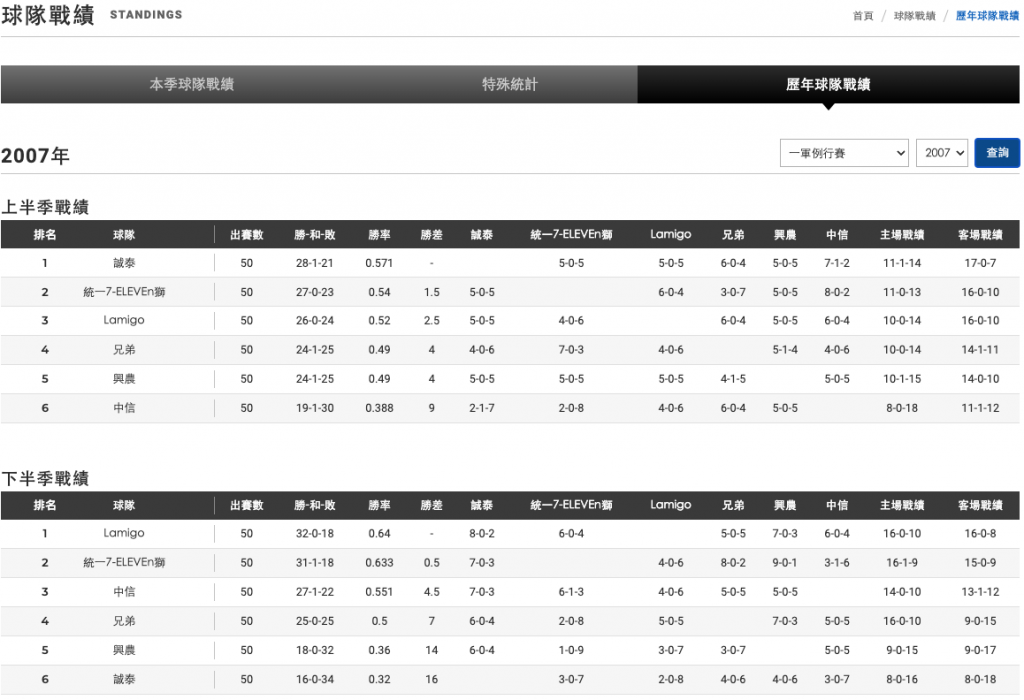
圖/2007 年戰績,擷取自中職官網歷年球隊戰績 https://www.cpbl.com.tw/standings/history。
承襲先前的觀察,資料源包含:games, teams, venues 三張表,而這些表要透過適當的 JOIN 結合後才能展現意涵。而結合的資訊主體和輔助說明分別有著正式的名稱-事實表 (fact table) 和維度表 (dimension table)。
事實表 (fact table)
表名習慣:fct_xxx
事實表是主要的表,它主要記載業務流程的歷程訊息,欄位多為可用於分析的量化資料。以職棒而言,舉辦賽事就是主要的業務,比賽兩隊的分數就事可分析的量化資料,因此 games 表是事實表。
維度表 (dimension table)
表名習慣:dim_xxx
和事實表剛好相反,維度表是一種描述性質的表,定義業務對象的特徵,輔助說明了事實的背景。例如透過與 teams 表和 venues 表的 JOIN 讓事實表 games 的隊伍資訊與場地資訊更完備。
這兩者還有一個區別:事實表的增長速度通常比維度表更快,因為事實表反映了企業業務的情況。
有了事實表與維度表的概念以後,我們接著觀察他們之間的連接方式。
星狀模型(Star Schema)
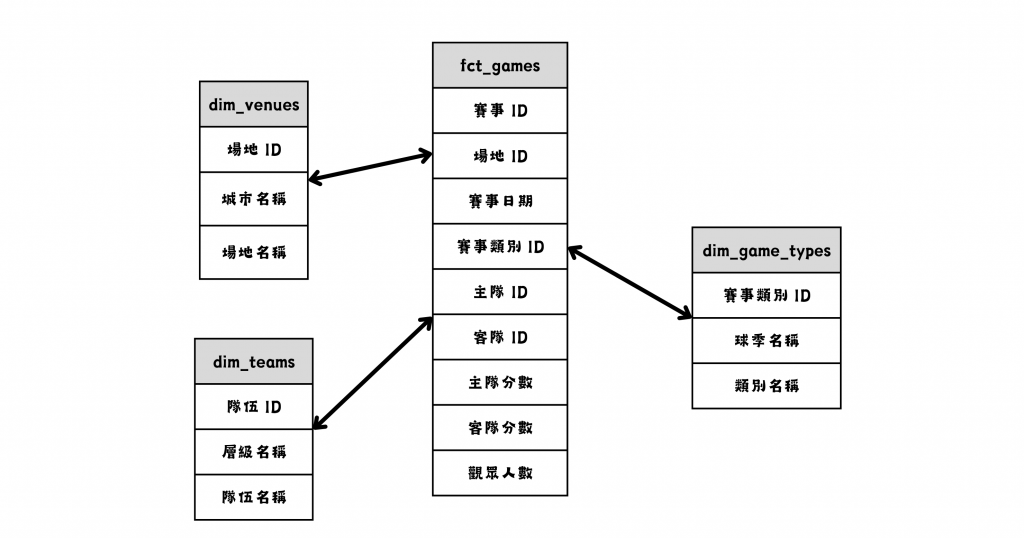
圖/中職官網可能的星狀模型。簡書廷製。顧名思義就是整個結構長得像星星啦!
星狀模型由一個中心事實表組成,所有的維度表直接連接到事實表。因為維度表和事實表之間的關聯只有一層,查詢時的 JOIN 操作較少,效能通常較好。以這個案例而言,以 fct_games 表為中心,場地、隊伍及賽事類別等資訊則存放在四周連接的維度表 dim_venues, dim_teams, dim_game_types。
雪花模型(Snowflake Schema)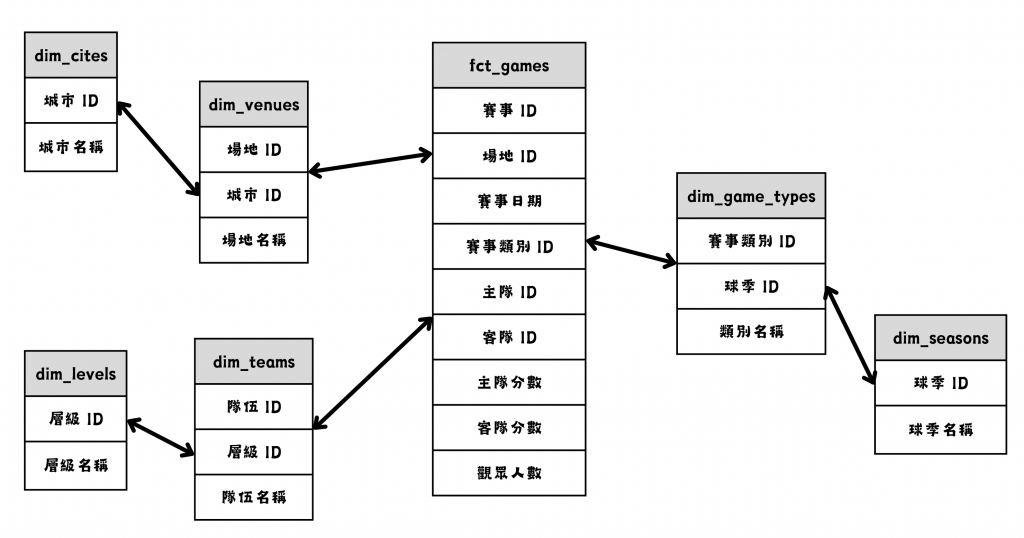
圖/中職官網可能的雪花模型。簡書廷製。雪花模型一樣是得名自結構外型,是星狀模型的擴展。
維度表進一步被細分為多個層次,讓表之間的關聯更為複雜。維度表的設計會類似 Day 02 提到的正規化,以避免資料冗餘造成的不一致,但查詢效能可能會降低。
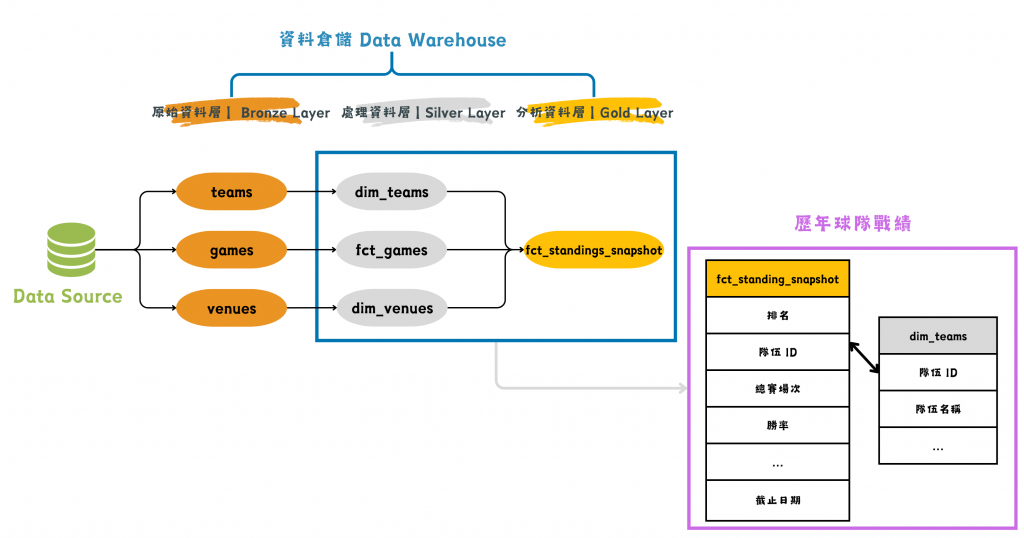
圖/中職官網歷年球隊戰績可能的資料架構與組合方式。簡書廷製。
這張圖把 Day 06 提到的三層式架構也納入考量,「歷年球隊戰績」的頁面看起來需要把事實表 fct_standing_snapshot 和 維度表 dim_teams 拼接在一起取得球隊名稱,最後呈現在官網上。問題就在這了,這張 Silver 層級的 dim_teams 到底存了什麼內容?
回推一步,這張表的主題是球隊資訊,根據資料倉儲紀錄所有歷程變化的能力,應該是歷來所有球隊名稱異動都能存下。從官網球隊沿革看起來,這支球隊的起源可回推至 2003 的第一金剛隊,2004 ~ 2010 的 Lanew 熊隊,2011 ~ 2019 的 Lamigo 桃猿隊,還有 2020 至今的樂天桃猿隊。
silver.dim_teams 的長相好像有點眉目了: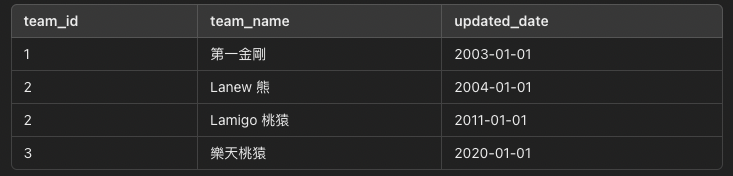
這樣一切都說得通了,在資料源裡頭, Lanew 熊 這筆資料在 2011 年被更新為 Lamigo 桃猿 ,所以它們有同一個 team_id 。而在 gold.fct_standing_snapshot 的計算時,是使用 team_id 去統計,而不是 team_name。到了最終呈現分析結果時,再把兩張表 JOIN 在一起,因此出現了 2007 年有 Lamigo 這樣的情形。
在這次的案例,或許是計算歷史戰績時就先 JOIN 比較適當,若是在電商情境,也許我們並不希望店家更名造成業績統計的斷裂,此時就是呈現再 JOIN 較合適。這也告訴我們,在資料倉儲裡無論是星狀模型或是正規化更極致的雪花模型,由於有歷程變化這個時間維度的存在,除了效能問題外,資料正確 JOIN 的難度遠比 OLTP 的業務資料庫來得更高。
明天我們再深入地聊聊時間維度在資料倉儲裡的運作與影響。

