
故事回到 Day 02 講的新創團隊弄的網購服務吧。本來只有兩個工程師在開發功能,沒想到這個平台有口皆碑,用戶一傳十十傳百,現在用戶已達千萬等級。為了落實『一站式』服務的理念,團隊也持續擴編,把金流、物流、倉儲、訂購、顧客還有 APP 拆分成一個個微服務 (micro-service) 小組各自進行開發,彼此功能透過 API 來相互聯通。
組織的拆分讓資料分析師一個頭兩個大,要做個訂單 x 商品與顧客的交互分析,得和各個小組各自要資料,不但資料可能對不起來,取用的介面也不方便,有的團隊給 CSV,有的開了個 API 內部接口要自己打參數。
自此我們才發現,『資料和程式碼的交鋒』終究要各自處理的,應用程式可以拆成微服務,資料得放在一起才能交互運用啊!
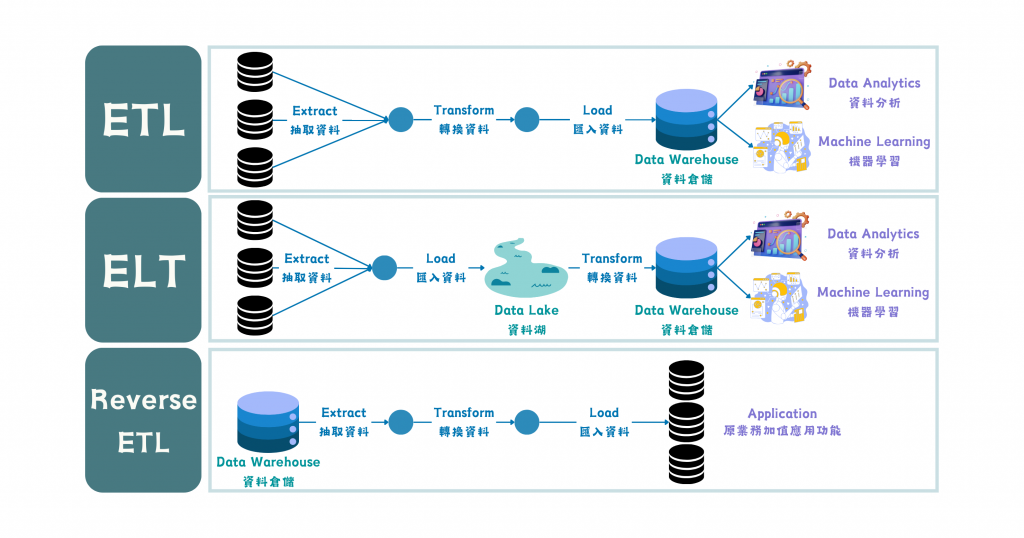
圖/Data Pipeline 的不同運用場景。簡書廷製。
再讓我們看一次這張資料處理流程,黑色的桶子不只是不同的表,而是不同微服務各自的資料集 (dataset),這也再次呼應了 Day 03 所提到的資料寬度。資料除了有著服務場景的不同,本身的特性也會影響處理的手法,初步分類如下:
{
"product_id": "12345",
"name": "智慧型手機",
"categories": ["3C", "手機"],
"price": 13,500.00,
"reviews": [
{
"user_id": "67890",
"rating": 5,
"comment": "非常好!"
}
]
}
無論是資料湖 (Data Lake) 或是資料倉儲 (Data Warehouse) 都是用來集中儲存各處所來的資料。但資料倉儲需要嚴謹的資料表 Schema 定義欄位特性,例如:儲存整數 (integer) 的欄位,就不能存放文字 (string)。但也因為這樣的嚴謹性,所以適合用 SQL 查詢、計算及分析。資料湖就沒有 schema 的限制了,可以放入任何格式的資料,包含結構化、半結構化或非結構化的資料,但要做統計時就不方便。
所以,在 Day 04 提到靜態資料儲存成本小於轉換成本的背景條件下,ELT 流程的設計上可能會先讓不同格式的資料都先快速地進到資料湖,再開發轉換的部分,後續才送進資料倉儲。兩者的拼接並存兼容了取用彈性及設計嚴謹帶來的資料品質。
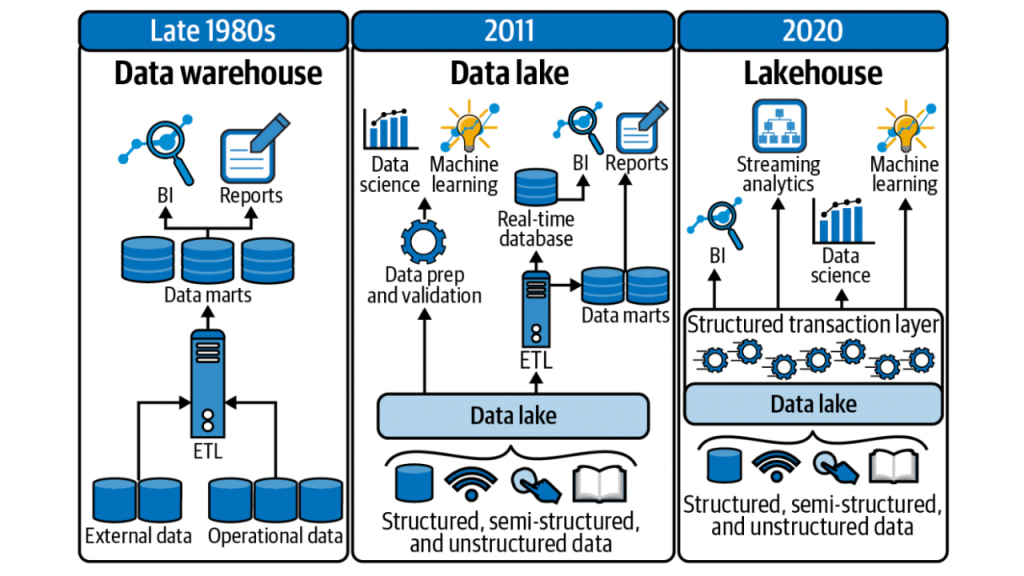
Source: The Modern Cloud Data Platform by Alice LaPlante (ISBN: 9781492087946)
上面這張圖說明了資料運用隨時間的推移。20 世紀末針對商業智慧運用 (Business Intelligence, BI) 及報表產製 (reports) 就已有資料倉儲的概念。把營運資料 (operation data, 也就是我們之前說的 in-house data) 和外部資料 (external data) 結合,透過 ETL 流程將資料轉換送進資料倉儲,根據分析場域進行分送,最後產出報表或儀表板 (dashboard)。
進到 21 世紀後,機器學習 (machine learning) 逐漸被運用到企業裡,例如:
只能支援結構化資料的資料倉儲不再能夠完全符合後續運用場景,因此有了資料湖的出現。有些資料團隊選擇將兩種系統拼接在一起,擷取各自的優點,但隨之而來的就是重複資料、額外的基礎建設成本、資訊安全挑戰等等。
此時資料湖倉 (Data Lakehouse) 應運而生,它的出現整合了資料湖與資料倉儲的優點,包含低成本的儲存費用、格式彈性,但又能透過資料人熟悉的 SQL 語句進行高效能的查詢。資料湖倉具體上有哪些特點呢?
總結起來,資料湖倉想透過檔案形式的資料,改善資料湖與資料倉儲並行時的高成本問題,但又不想割捨資料庫的查詢效率,因此得引入查詢引擎的設計,這也是一個建構成本。資料團隊在做選擇時,除了資料本身的查詢/儲存成本外,工程師開發/維護系統的成本也要考慮進去。
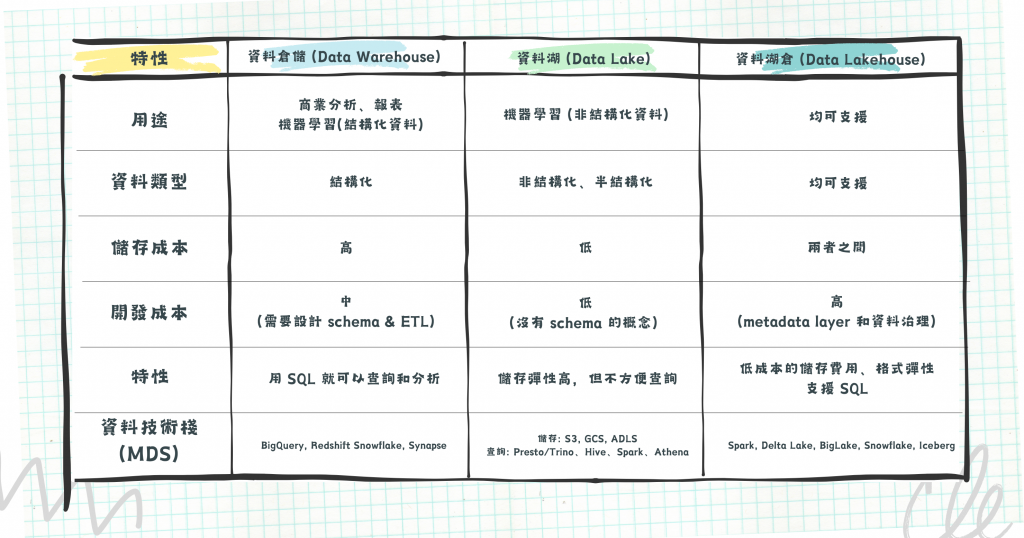
圖/資料倉儲、資料湖與資料湖倉的綜合比較。簡書廷製。
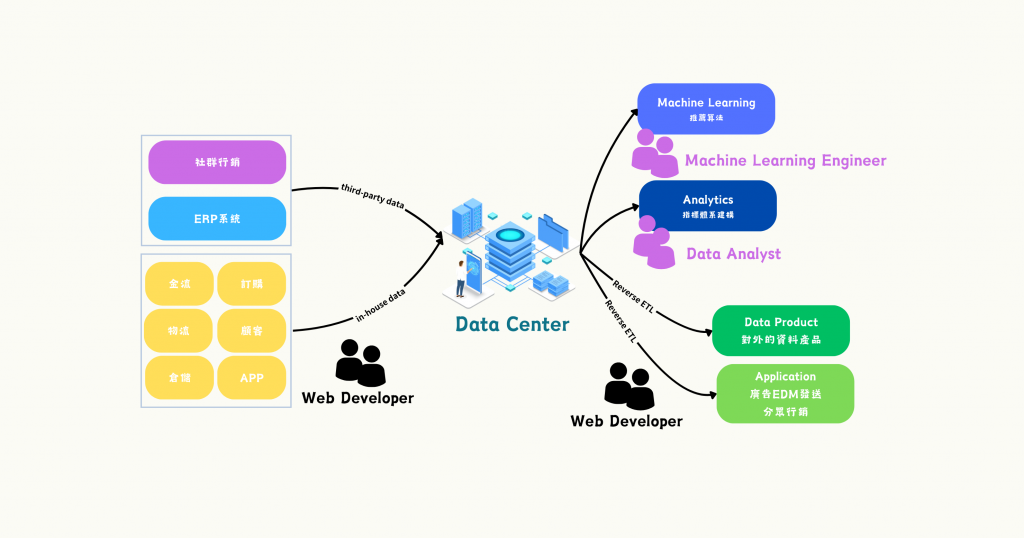
圖/電商平台的資料運用。簡書廷製。
資料團隊在整個公司裡,就像是一個資料中心一樣,無論選用了資料倉儲 + 資料湖的雙拼架構,還是新世代的資料湖倉,對資料使用者而言只有一個期待:『盡快給我高品質的資料。』這當然也是每個資料團隊的目標,為了發揮資料本身的價值,資料中心需要具備以下能力:
所以,資料工程師並非不管程式碼只管資料,而是*『為了盡快提供高品質的資料,而在資料基礎建設與資料處理上煞費苦心(與大量的時間)』*。
有趣的是,後端工程師在 Reverse ETL 上,是資料的取用者 (consumer),但從上面的圖看起來,也同時是資料的產製者 (producer),所以說到底,程式碼 (應用程式) 和資料還是分不開呀~

