不同的編碼方式,在解碼的時候,可能導致亂碼,如下圖所示: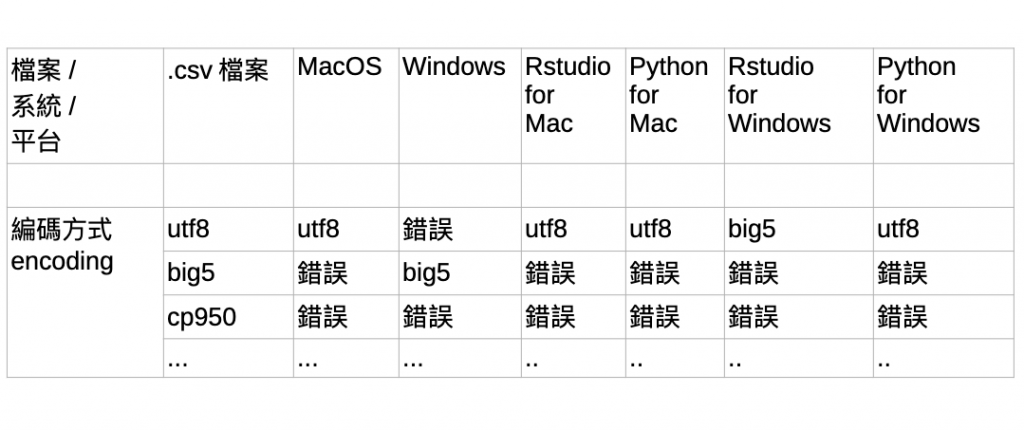
請先執行:
def decode1():
x = input()
a = ''
for i in x:
a+=i
if len(a)<6:
c = chr(int(a))
print(c)
else:
a=a[-1]
def decode2():
x = input()
a = ''
for i in x:
a+=i
if len(a)==5:
c=chr(int(a))
print(c, end='')
if len(a)>=6:
a=a[-1]
decode1 和 decode2 是我寫的二個功能(function),中文又稱作函式,最後一行的 # 解碼,示範 解碼 "20320229092196665311"這串數字。
以ASCII,big5,utf8,utf16四個編碼方式為例:

ord( ) <-> chr( )
ord('你')
20320
chr(20320)
'你'
a = '好'
a.encode('utf8')
b'\xe5\xa5\xbd'
print('\u4f60', '\u597d')
你 好
# ascii將中文字轉成utf16
ascii('你好嗎?')
"'\\u4f60\\u597d\\u55ce\\uff1f'"
# 記得先執行前面的 def
20320229092196665311
#decode1()
decode2()
20320229092196665311
你好嗎?
讀檔的時候,有時會加encoding='utf-8'這一行,來解決亂碼的問題。
with open('檔名.副檔名', encoding='utf-8') as f:
f.read...

