
過去幾天我們一再強調捕捉時間維度的變化是資料倉儲重要的能力,但在 Day 07『穿越到 2007 年戰績表的 Lamigo』事件裡,我們也見證了時間維度是資料倉儲系統在運用資料時,必須駕馭的問題。
從資料源將資料送入資料倉儲時,根據應用情境與成本考量,有許多種不同的載入 (load) 方式。今天我們來觀察不同的載入方式,對於資料的新鮮度是如何保存的。
這裡我們先有個共識,接下來談的資料源/原始表,指的就是業務資料庫,他就是 Day 03 提到的 OLTP,裡頭存的資料就是事務的最新狀況,
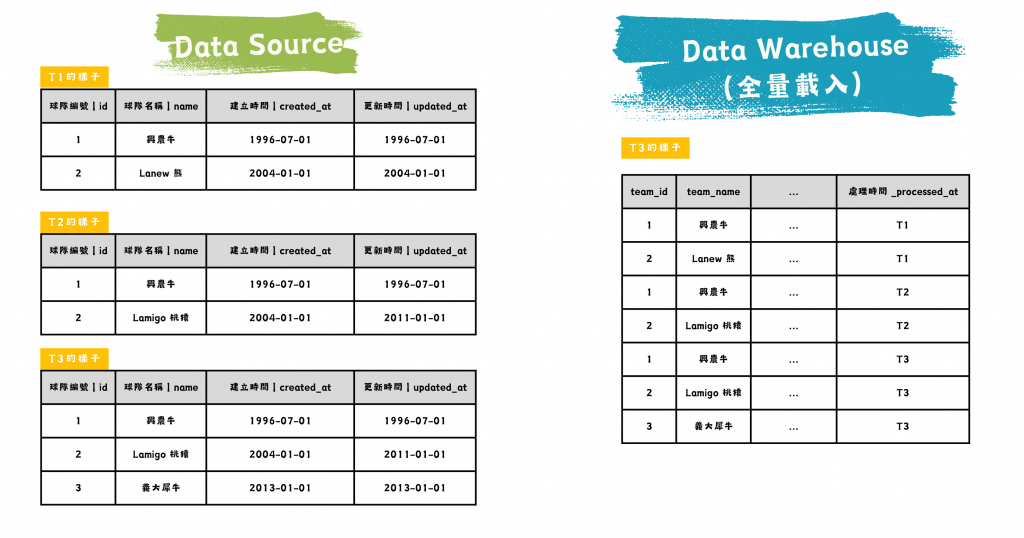
圖/全量載入的資料源與資料倉儲比較。簡書廷製。
全量載入是定時將「整張原始表當時的樣貌」完整地送入資料倉儲中,可以理解為清點貨品的人針對貨源拍照 (snapshot) 後送入倉庫。這種方式適合資料量較少,且需要完整重建資料的場景。以中華職棒隊伍資訊而言,整張原始表最大的一刻是 1997 年的 7 列。假如職棒元年就開始有 data pipeline,載入頻率可以一年一次,資料倉儲的對應表至今也不到 300 筆而已。
全量載入的優點是能夠確保資料的一致性,避免資料遺漏。在 Day 06 的事件中,我們在顯示歷年戰績時,也可以根據年份找到對應的那份 snapshot 來 JOIN,就不容易出錯。
隨著資料規模的增長,這種方法的效能與成本問題也變得不可忽視。舉個好理解的例子就是電商平台,無論是顧客、訂單或是使用者行為事件,從增長性看來三者都不適合全量載入資料倉儲。另外,如果一張原始表裡面的資料列 (row) 大部分都不太會異動,那全量載入顯然是浪費了。
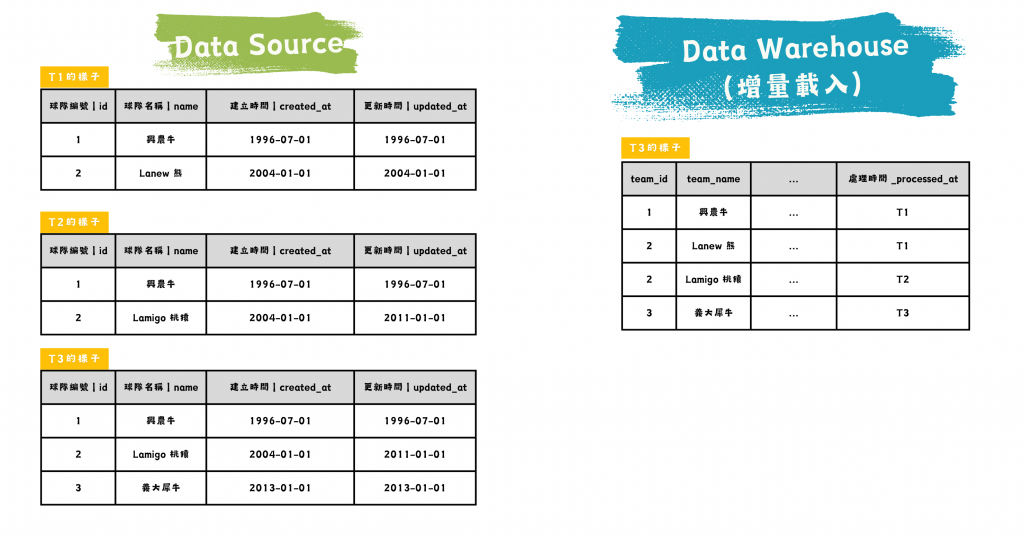
圖/增量載入的資料源與資料倉儲比較。簡書廷製。
與全量載入相對,增量載入只會將「兩次載入之間原始表的變動資料」載入到資料倉儲中,而非每次都重新載入所有資料。在資料源的資料量級龐大的情況下,這不僅縮減了載入時間,也減少寫入與儲存成本。
例如,訂單資料表每天新增 1,000 筆,並且每天會有過去的 500 筆訂單有資料異動,觀察一年過去以後表格的筆數:
資料源:1,000 * 365 = 365,000 筆
若採用每天定時增量載入,我們只需載入,無需重新處理過去的所有資料。
資料倉儲:1000*1 + (1000+500)*364 = 547,000 筆
若採用全量載入,試算結果就可見資料儲存落差之大!
資料倉儲:(1,000 + 365,000) * 365 / 2 = 66,795,000 筆
增量載入讓資料保持足夠的新鮮度,同時避免系統過載。不過在資料倉儲取用時,稍微比全量載入來的麻煩些。假設有一張訂單在 2024/1/1 創建,後續 2024/1/5、2024/1/14、2024/1/30 都有變動紀錄,資料分析師想要分析訂單全表 fct_orders 在 2024/1/20 的狀況,增量與全量的查詢方式分別如下:
-- 全量
SELECT
order_id,
...
FROM
`fct_orders`
WHERE
_processed_at = '2024-01-20'
--- 增量
WITH orders AS (
SELECT
order_id,
...,
ROW_NUMBER() OVER(PARTITION BY order_id ORDER BY _processed_at DESC) AS rn
FROM
`fct_orders`
WHERE
_processed_at <= '2024-01-20'
)
SELECT
...
FROM
orders
WHERE
rn = 1
可以看出增量匯入的策略上,要重現 2024/1/20 的情況,得要對表格用上 Window Function。不過為了節省可能指數成長的儲存成本,寫個 Window Function 來找最新鮮的資料,可能還算小事一樁。
資料保鮮度的挑戰之一,是如何處理變化不頻繁的維度資料如顧客地址、產品分類等,這些資訊可能多年都不會發生變動。如何記錄並追蹤這些維度變動帶出了 SCD 的概念。
SCD Type 0:Retain Original 維持原狀
資料一旦載入即不變動,適用於不應該修改的靜態資料,例如原始資料建立日期。若隊名被認為不應該修改,以下方這張圖紅色列而言,就會記到原本的隊名。
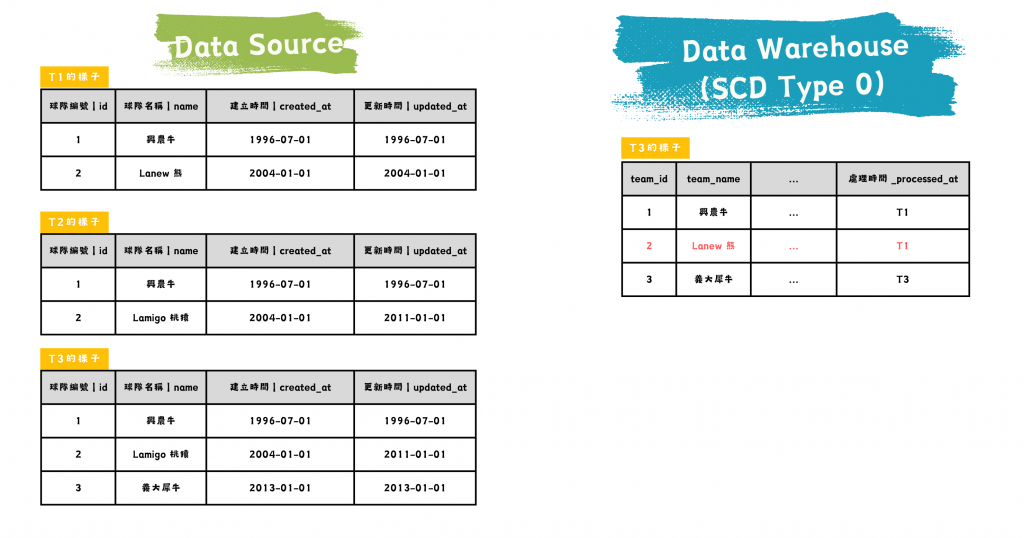
圖/SCD Type 0 的資料源與資料倉儲比較。簡書廷製。
SCD Type 1:Overwrite 覆蓋
變動資料直接覆蓋舊資料,不保留歷史紀錄,適合只需要最新資料的情境。
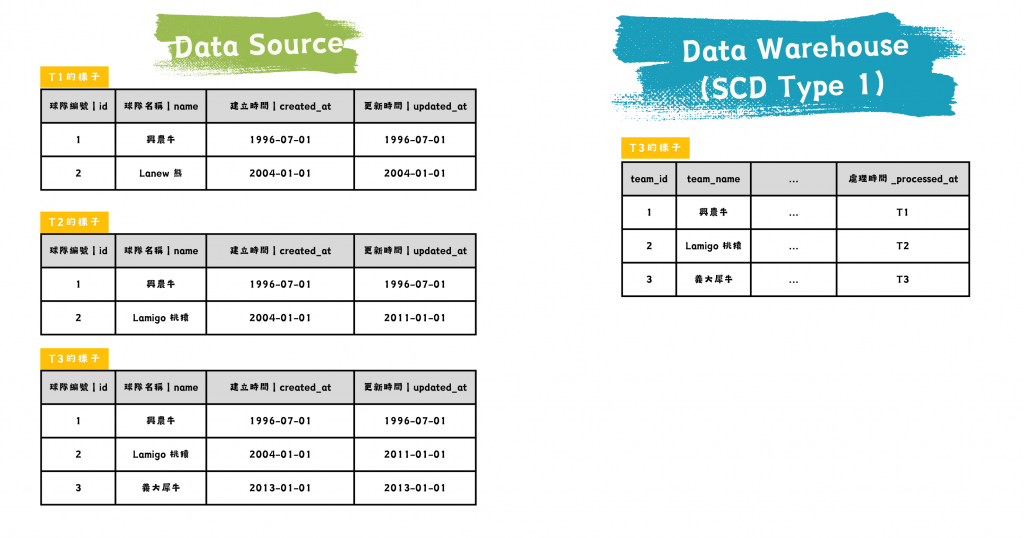
圖/SCD Type 1 的資料源與資料倉儲比較。簡書廷製。
SCD Type 2:Add New Row 增加新列
為每次變更建立新版本,並記錄開始與結束日期,保留完整歷史紀錄。這種方法適合需要追蹤資料變動歷史的場景,如隊名變更歷程。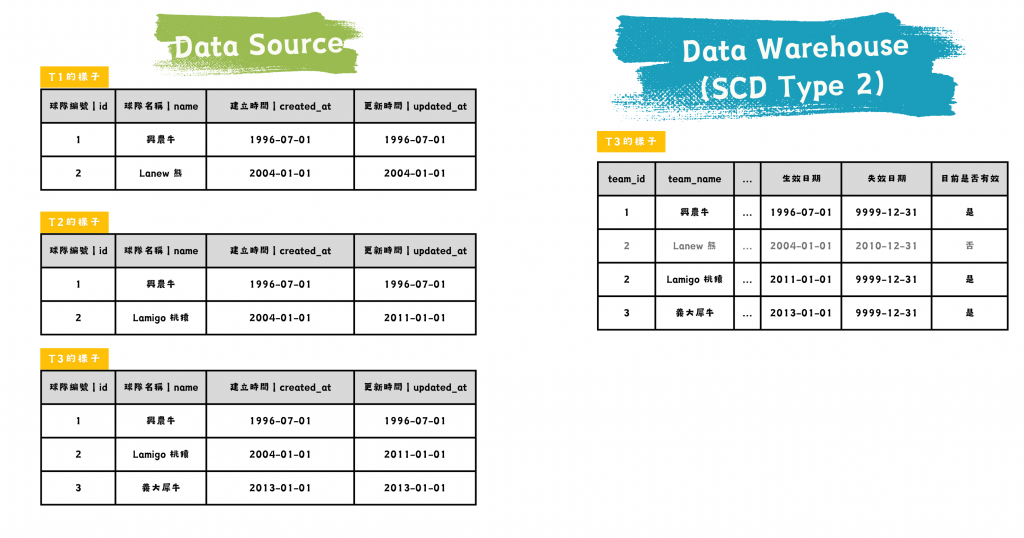
圖/SCD Type 2 的資料源與資料倉儲比較。簡書廷製。
資料倉儲中會用生效日期和失效日期來控管資料新鮮度,長相像是拉鍊一樣,因此也稱為拉鍊表。
SCD Type 3:Add New Attribute 新增欄位
保留部分歷史資料,通常限於特定欄位。比如保留前一個隊名,但不記錄兩次變更以前的隊名。
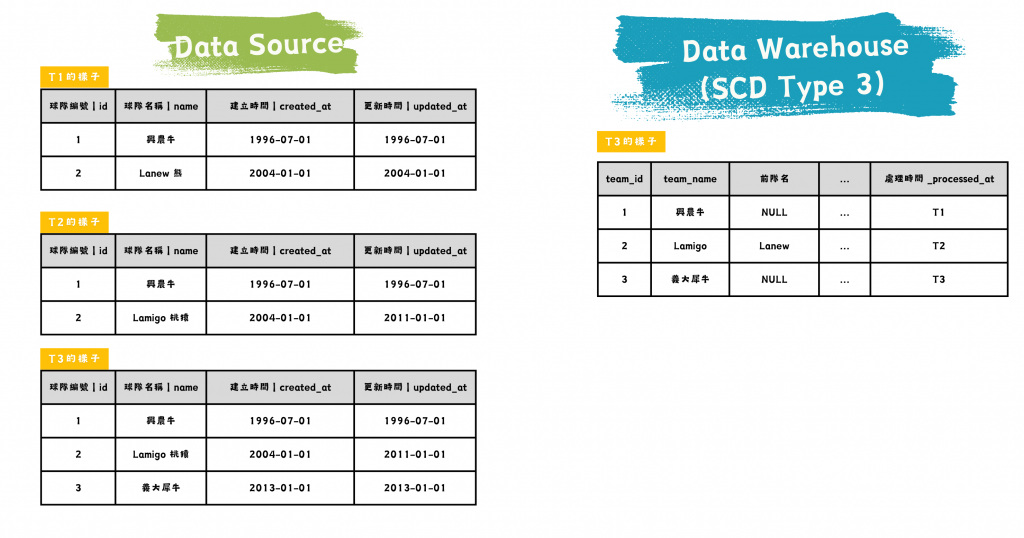
圖/SCD Type 3 的資料源與資料倉儲比較。簡書廷製。
SCD Type 4:Add New Table 另存新表
與前幾種方法不同,SCD Type 4 使用一張獨立的歷史表來保存過去的資料變更。主資料表中只保留最新的資料,所有歷史資料則儲存在獨立的歷史表中。這種方式有效減少主資料表的負擔,同時又能提供完整的歷史資料查詢。
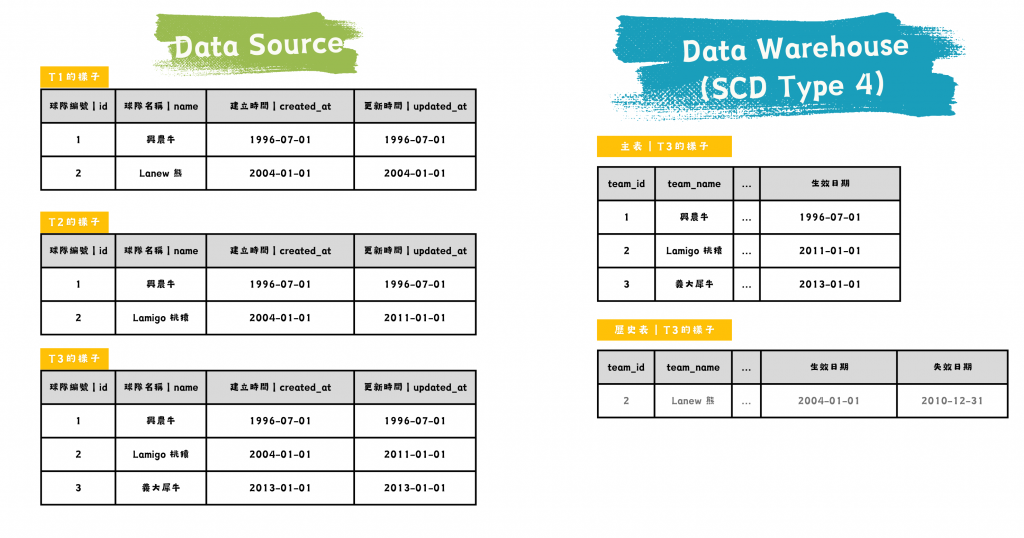
圖/SCD Type 4 的資料源與資料倉儲比較。簡書廷製。
在實務中,我們會根據每張原始表不同的特性,選擇合適的載入策略。
除了全量載入以外,增量載入或者 SCD 都需要在載入前掌握哪些資料有過變動。以下就來介紹變動資料的掌握方法。
時間戳記
在資料表中以創建時間 created_at及修改時間 updated_at 欄位找到兩次載入間的變動資料。這種方法簡單且實用,適合大部分的增量載入場景。時間戳記的優點是易於實作,缺點則是每次變更都需正確記錄時間戳,否則會導致載入資料倉儲的資料有遺漏。這就仰賴資料工程端 (通常是資料工程師) 與資料源端 (通常是後端工程師) 及兩方團隊有效配合與溝通。
變更資料捕捉(Change Data Capture, CDC)
這是一種專門追蹤資料變更的技術,它監控資料庫中的每次插入、更新和刪除操作,簡言之是透過資料庫變動日誌 (log) 去進行後續的 data pipeline。這個方法就很多可以談的技術了,包含 CDC 本身、串流 (streaming)、訊息佇列 (message queue) 等,之後詳細獨立一篇篇拆解。
CDC 的優點是可以精確捕捉每個變動,適合大規模資料庫操作。缺點則是需要額外的系統設定和維護,對於小型系統可能不太適合。
時間戳記法搭配資料工程端定時對資料源 query,才能找出異動資料。CDC 法則是資料源本身就主動記下所有異動,資料更為細緻,但資料量也較多。
目前為止我們掌握了載入的策略,以及資料變動的追蹤方式。這兩者的判斷邏輯通常是設計在 data pipeline 上,那在 data pipeline 完工上線以前,那些資料源已經發生過的變動該怎麼處理呢?這就需要「資料搬遷」了!
可能的做法是如下圖:在 data pipeline 上線後進行一次初始的全量載入,後續則讓 data pipeline 開始運行,逐步增量載入。但如果沒有配合 CDC 法,即便全量載入,資料倉儲初始能獲取的也只有載入時資料源的樣子。
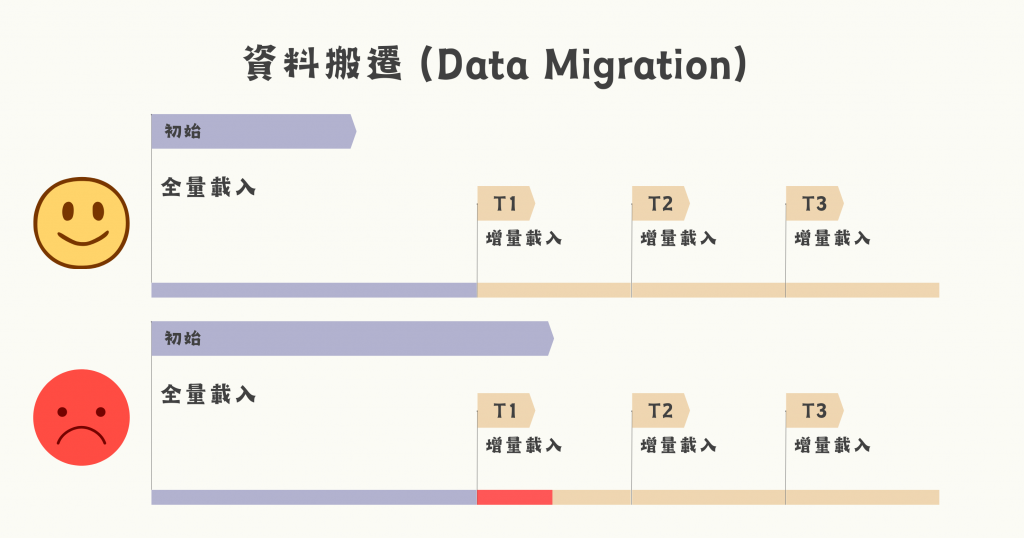
圖/資料搬遷任務的時間軸。簡書廷製。
資料搬遷也需要考量時序性,第一種搬遷時序就能確保資料的完整性與正確性。但若初始化的搬遷因為打包份量過大,導致未能於 data pipeline T1 開始進行前全部完成,則會造成舊的打包資料覆蓋新寫入資料的錯誤,如圖中紅色區段所示。由此可知,data pipeline 的完工只是資料工程的一部分,資料的完整打包與搬遷也是資料保鮮度的一大影響因子
總結今天提到的觀念,資料倉儲對於每個維度隨時間變化的保存過程,可以分為兩個面向來看:
載入方式:只載入差異 (增量)、全表載 (全量)、觀察維度差異 (SCD)
異動追蹤:用 updated_at 判斷 (時間戳記法)、從日誌全搜刮 (CDC)
保留得越完整,能夠觀察的異動歷程就越細緻,但也要付出對應的開發成本,以及過度設計 (over design) 的風險。

