在資料分析的第一步,我們通常需要快速檢視資料集的內容,以便了解資料的基本結構和特徵。今天,我們將學習如何使用 Pandas 來查看資料的前幾筆和後幾筆數據,並運用 Iris 資料集來進行實作。
以下有任何問題,都可以私訊我的IG
點我私訊IG
首先,我們需要在昨天創建的 Iris 資料夾中,再新增一個 Google Colab 筆記本,並命名為 iris_check。
首先,我們需要載入 Iris 資料集,這個資料集包含 150 筆資料,每筆資料有 4 個特徵(花萼長度、花萼寬度、花瓣長度、花瓣寬度)以及 3 種類型的花卉。
from google.colab import drive
import pandas as pd
# 掛載 Google Drive
drive.mount('/content/drive/')
# 讀取 CSV 檔案
iris_df = pd.read_csv('/content/drive/MyDrive/iris/iris_dataset.csv')
我們可以使用 head() 函數來檢視資料集的前幾筆資料。預設情況下,它會顯示前 5 筆資料,但你也可以指定顯示的行數。
# 查看前 5 筆資料
print(iris_df.head())
# 查看前 10 筆資料
print(iris_df.head(10))
這段程式碼將顯示 Iris 資料集的前 5 筆或前 10 筆資料,我們可以看到每個特徵的數值以及它們對應的花卉類型。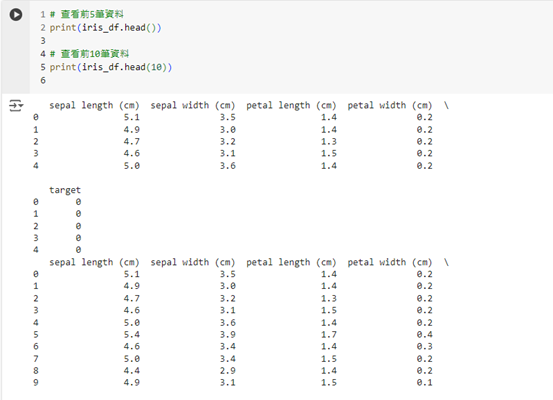
同樣地,我們可以使用 tail() 函數來查看資料集的最後幾筆資料,預設會顯示最後 5 筆資料。
# 查看後 5 筆資料
print(iris_df.tail())
# 查看後 10 筆資料
print(iris_df.tail(10))
這段程式碼會顯示資料集的最後幾筆資料,幫助我們檢查資料集末尾的數據情況。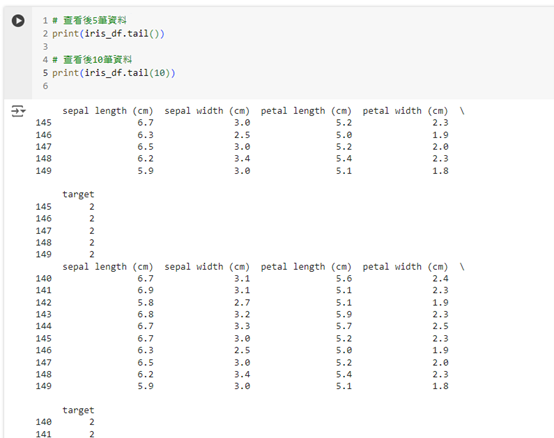
有時候,我們想要隨機查看一些資料點,而不是固定的前幾筆或後幾筆。我們可以使用 sample() 函數來隨機抽取資料。
# 隨機抽取 5 筆資料
print(iris_df.sample(5))
這樣,我們可以隨機抽取資料集中的幾筆資料進行檢查,特別適合用來查看資料集中是否有潛在的異常值或誤差。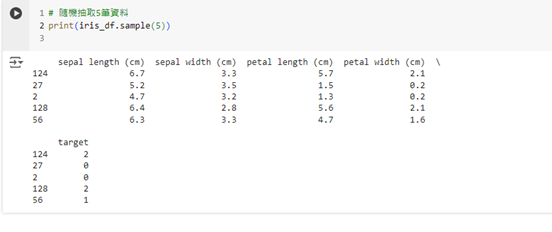
Pandas 還提供了一些實用的函數,幫助我們快速了解資料的大小、結構和欄位名稱。例如,我們可以使用 info() 函數來查看資料集的基本結構和每個欄位的數據類型。
# 查看資料集的基本資訊
print(iris_df.info())
這段程式碼會顯示資料集的總行數、每個欄位的名稱、數據類型和缺失值的數量,讓我們對資料集的概況有一個全局的了解。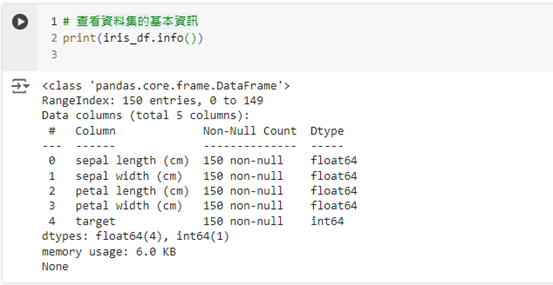
我們還可以使用 describe() 函數來查看資料集的統計摘要,包括平均值、標準差、最大值、最小值等信息。
# 查看統計摘要
print(iris_df.describe())
這樣我們可以快速了解每個數值型特徵的分佈情況,有助於進一步的資料處理和分析。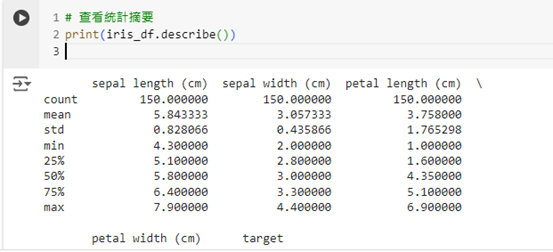
今天我們學習了如何使用 Pandas 來快速檢視資料集的內容,包括查看資料集的前幾筆、後幾筆和隨機抽取的資料,這些技巧能幫助我們在資料分析的第一步迅速掌握資料的基本結構。這些工具能夠提高我們檢查資料的效率,為後續的資料清理和分析打下基礎。

