上一篇我們用了加權的方式,幫股票的未來漲幅算了一個加權分數,還做了一個從10MA到200MA的Boxplot列表。從結果來看,每個MA下的中位數其實差不多,沒有特別顯著的差異。這次,我們要改進一下加權分數的算法,看看能不能讓我們更好地選出長、中、短期MA,讓分析結果更明顯一些。
因為上一篇的參數是我自己隨意設定的,結果可能不太理想,所以這次我決定調整一下加權計算的參數。我們會使用 Grid SearchCV(網格搜索) 來幫我們找出更好的參數組合。簡單來說,Grid SearchCV 是一種方法,它會自動幫我們試出所有可能的超參數組合,找出最佳的模型配置,讓結果更精確。
下面是使用 Grid SearchCV 進行計算的程式碼:
import pandas as pd
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LinearRegression
import numpy as np
import os
folder_path = r'C:\iThome\raaa'
all_files = [f for f in os.listdir(folder_path) if f.endswith('.csv')]
data_frames = []
for file in all_files:
df = pd.read_csv(os.path.join(folder_path, file))
data_frames.append(df)
# 合併所有資料
data = pd.concat(data_frames, ignore_index=True)
X = data[['5日漲跌幅', '20日漲跌幅', '60日漲跌幅', '5日最大漲幅', '20日最大漲幅', '60日最大漲幅']]
y = data['future_return']
param_grid = {
'5日漲跌幅_weight': [0.1, 0.2, 0.3],
'20日漲跌幅_weight': [0.1, 0.2, 0.3],
'60日漲跌幅_weight': [0.05, 0.1, 0.2],
'5日最大漲幅_weight': [0.1, 0.2, 0.3],
'20日最大漲幅_weight': [0.1, 0.15, 0.2],
'60日最大漲幅_weight': [0.05, 0.1, 0.2],
}
class WeightedModel:
def __init__(self, **weights):
self.weights = weights
def fit(self, X, y=None):
return self
def predict(self, X):
weighted_sum = (
X['5日漲跌幅'] * self.weights['5日漲跌幅_weight'] +
X['20日漲跌幅'] * self.weights['20日漲跌幅_weight'] +
X['60日漲跌幅'] * self.weights['60日漲跌幅_weight'] +
X['5日最大漲幅'] * self.weights['5日最大漲幅_weight'] +
X['20日最大漲幅'] * self.weights['20日最大漲幅_weight'] +
X['60日最大漲幅'] * self.weights['60日最大漲幅_weight']
)
return weighted_sum
# 添加 get_params 讓 GridSearchCV 可以提取參數
def get_params(self, deep=True):
return self.weights
# 添加 set_params 讓 GridSearchCV 可以設置參數
def set_params(self, **params):
for key, value in params.items():
self.weights[key] = value
return self
from sklearn.model_selection import GridSearchCV
model = WeightedModel()
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, scoring='neg_mean_squared_error', cv=5)
grid_search.fit(X, y)
print(f"Best weights: {grid_search.best_params_}")
print(f"Best score: {grid_search.best_score_}")
程式輸出為:
Best weights: {'20日最大漲幅_weight': 0.2, '20日漲跌幅_weight': 0.3, '5日最大漲幅_weight': 0.1, '5日漲跌幅_weight': 0.3, '60日最大漲幅_weight': 0.05, '60日漲跌幅_weight': 0.05}
接下來,我們可以列出每個 MA_window 的平均加權分數,這樣可以幫助我們判斷哪條均線表現得比較好。
以下是各均線的平均加權分數: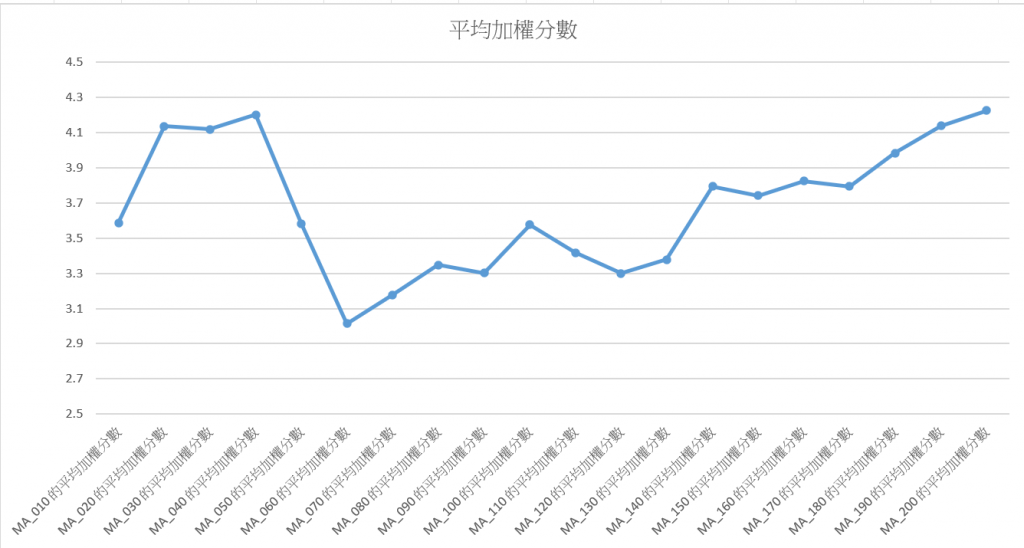
不過,因為加權分數中有一些離群值出現,我們這次使用了四分位距(IQR)來計算離群值的範圍,並把超出這個範圍的值給移除。這是移除離群值後的結果: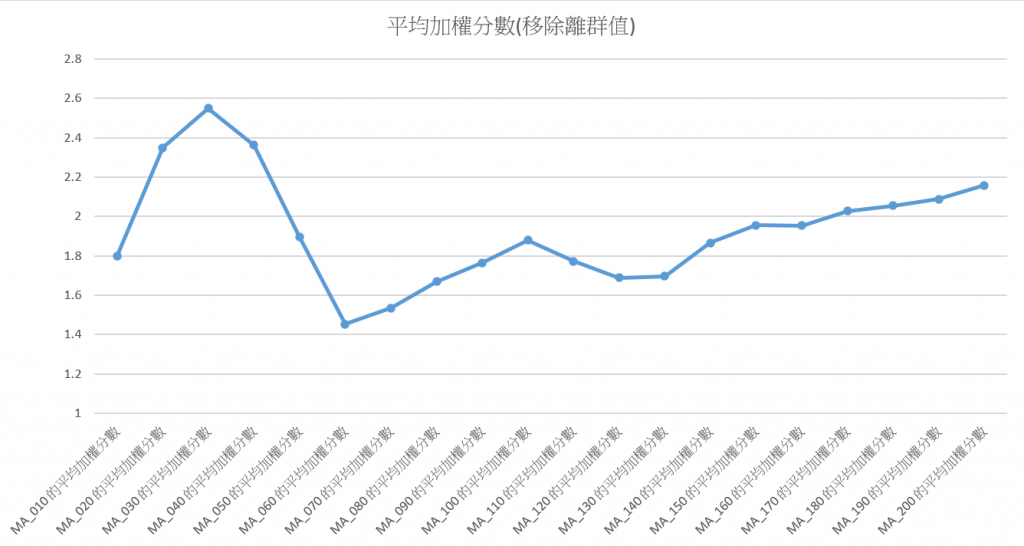
根據 Investopedia 提到的「最常使用的移動平均線 (MA) 期間」:
我們可以進一步將這些期間分成三類:
根據我們先前計算的平均加權分數,我們可以採用以下期間作為基準:
這樣就找出長中短均線了。
這篇文章中,我們通過改進加權分數的算法,成功選出了適合的長、中、短期移動平均線。透過使用 Grid SearchCV,我們找到了更佳的權重參數,這不僅提升了模型的精確度,還讓我們更清楚地理解各均線的表現。
在平均加權分數的分析中,雖然最初的數據中出現了一些離群值,但透過四分位距(IQR)進行處理後,我們得到了更乾淨的數據,讓分析結果更具參考價值。最終,我們根據 Investopedia 提到的常用期間,將移動平均線分類為短期(30MA)、中期(100MA)及長期(200MA),這樣的分類也能幫助我們在投資決策時更加明確。


 iThome鐵人賽
iThome鐵人賽