資料分析是從原始數據中提取有用信息的過程,通過清理、探索、建模和解釋數據,幫助識別趨勢、模式,並支持決策制定
Numpy是一個用於資料處裡的重要模組,其具備平行處理的能力,可以將操作動作一次使用在大型陣列上
Numpy函數
import numpy as np先利用import將numpy模組載入
Numpy中有部分函數與math模組內的功能重複,因此本篇會著重在只有Numpy有的函數
np.logical_and(a,b)將陣列 a 和 b 做 and 運算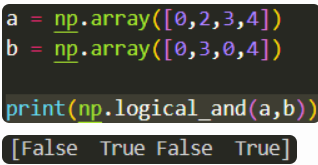
np.logical_or(a,b)將陣列 a 和 b 做 or 運算
np.logical_xor(a,b)將陣列 a 和 b 做 xor 運算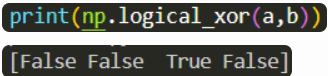
np.logical_not(a)將陣列做 not 運算
array_equal(a,b)比較陣列 a 和 b 是否相等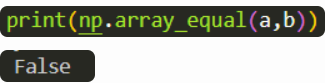
常用陣列處理函數
np.sum(arr,axis=i)沿軸 i 進行加總,如果沒設定i的方向,則全部加總
np.min(arr,axis=i)沿軸 i 方向找出元素最小值
np.max(arr,axis=i)沿軸 i 方向找出元素最大值
np.argmin(arr,axis=i)沿軸 i 方向找出最小值的位置
np.argmax(arr,axis=i)沿軸 i 方向找出最大值的位置
np.unravel_index(a,(m,n,...))將一維索引 a 轉換成形狀為 (m,n,...) 的索引
np.ravel_multi_index(a,(m,n,...))將維度 (m,n,...) 的索引轉換成一維索引
np.where(condition)找出 condition 為 True 的位置
np.where(condition,x,y)若 condition 成立則回傳 x ,否則回傳 y
np.all(arr,axis=i)沿軸 i 方向判別元素是否全為 True
np.any(arr,axis=i)沿軸 i 方向判別任意元素是否為 True
np.unique(arr,axis=i)沿軸 i 方向刪除重複的列
import numpy as np
a = np.array([[0,2,3,4],
[2,4,6,8],
[4,3,8,1]])
print(np.sum(a,axis=1))
print(np.min(a,axis=0))
print(np.max(a,axis=0))
print(np.argmin(a,axis=0))
print(np.argmax(a,axis=0))
print(np.unravel_index([4,1,2],(2,3)))
print(np.ravel_multi_index([[0, 1, 2], [1, 2, 0]],(3, 3)))
print(np.where(a))
print(np.where(a>3,1,0))
print(np.all(a, axis=1))
print(np.any(a, axis=0))
print(np.unique(a,axis=0))

參考資料:https://docs.python.org/zh-tw/3/tutorial/index.html


 iThome鐵人賽
iThome鐵人賽