若想要將模型的輸出轉換成程式可用的資料型態,我們可以用 Langchain 的 StructuredOutputParser 的方法去幫我們達成,其實現方法也就是在打一次請求,將我們 invoke 的結果送回 LLM 幫我們轉換成 Markdown 或 Json 格式的資料
from langchain_community.chat_models import ChatOllama
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
response_schemas = [
ResponseSchema(name="建議", description="模型回覆的建議")
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(
template="請根據使用者給予的內容,給予實質的建議或者有用的回覆,回覆請使用繁體中文.\n{format_instructions}\n{question}",
input_variables=["question"],
partial_variables={"format_instructions": format_instructions},
)
llm = ChatOllama(
model="gemma2",
base_url="http://127.0.0.1:11434"
)
chain = (
prompt
| llm
| output_parser
)
print(chain.invoke({"question": "我想要買一台筆電,但是不知道要選擇哪一台,可以給我一些建議嗎?"}))
可以得出以下回覆

也可以從官方文檔中得到更多有關 Parser 的不同用法
不只輸出格式可以設定,連記憶會話的方法也有不同的選擇
如 ConversationBufferMemory、ConversationBufferWindowMemory 以及 ConversationSummaryBufferMemory 等等
不同的 Memory 方法,適用的時機也不同
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory, ConversationBufferWindowMemory, ConversationSummaryBufferMemory
from langchain_core.prompts.prompt import PromptTemplate
template = """你是一個聊天機器人,請盡根據使用者的需求進行回覆,回覆請使用繁體中文
History:
{history}
Human: {input}
AI Assistant:"""
PROMPT = PromptTemplate(input_variables=["history", "input"], template=template)
conversation = ConversationChain(
prompt=PROMPT,
llm=llm,
verbose=True,
memory=ConversationBufferMemory()
)
conversation.predict(input="你好!")
conversation.predict(input="告訴烘焙的相關知識")
conversation.predict(input="烘焙技巧和方法")
若我們想要預先初始化先前的對話,也可以直接透過 .save_context() 直接設定
memory = ConversationBufferMemory()
memory.save_context({"input": "告訴烘焙的相關知識"}, {"output": "好的,我可協助您了解烘焙相關知識。請問您想了解哪些方面呢?\n\n* **烘焙材料和方法**\n* **烘焙技巧和方法**\n* **烘焙流程**\n* **烘焙設備**\n* **烘焙常見問題**\n* **烘焙相關歷史**"})
conversation = ConversationChain(
prompt=PROMPT,
llm=llm,
verbose=True,
memory=memory
)
conversation.predict(input="烘焙技巧和方法")
用法與 ConversationBufferMemory 一樣,不過超過 k 所設定的歷史對話將被捨棄,其中原因包含 ConversationBufferMemory 的運作方法就是將歷史對話一起丟給 LLM 去做處理,好處當然就是可以有「對話」的感覺,缺點就是會很吃 Token,畢竟給的不只當前的輸入與輸出,還給了過往的對話紀錄,這時若使用 ChatOpenAI 去打 OpenAI 的服務,可以說,帳單跟 Token 使用量一起起飛。
# 透過 k 來設定留下多少個對話
conversation = ConversationChain(
prompt=PROMPT,
llm=llm,
verbose=True,
memory=ConversationBufferWindowMemory(k=2),
)
...
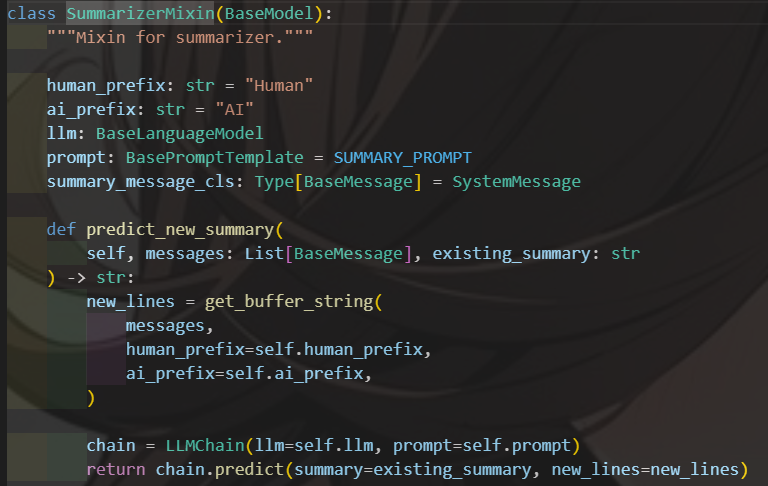
我們也可以使用 Langchain 自帶的「總結」工具
memory = ConversationSummaryBufferMemory(llm=llm)
memory.save_context({"input": "告訴烘焙的相關知識"}, {"output": "好的,我可協助您了解烘焙相關知識。請問您想了解哪些方面呢?\n\n* **烘焙材料和方法**\n* **烘焙技巧和方法**\n* **烘焙流程**\n* **烘焙設備**\n* **烘焙常見問題**\n* **烘焙相關歷史**"})
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=memory
)
conversation.predict(input="烘焙技巧和方法")
若使用本地語言模型,則需特別注意模型的回覆效果,倘若模型本身不夠給力,總結有可能失效,或者總結的不好
然後,沒錯,能做到總結功能,也是 Langchain 偷偷幫你再多打一次 API 喔 XD


 iThome鐵人賽
iThome鐵人賽