在第五天的內容我們提到了推薦系統,主要是計算「用戶」的相似度以及「項目」的相似度(稱為協同過濾),今天要來學習AI如何統整這些大量又複雜的數據、還有它們的評估標準又是什麼,才使得它可以快速又精準的推測我們的喜好。
一、矩陣分解技術
當我們處理協同過濾時,很多時候數據是非常稀疏的,因為不是每個用戶都對每個項目評分。矩陣分解可以幫助我們從這些零散的評分數據中推測出用戶對其他項目的潛在喜好,並提高模型的推薦精度。
SVD(Singular Value Decomposition)
將用戶-項目矩陣拆解為更小的矩陣:用戶矩陣、奇異值矩陣(代表數據特徵重要性順序)、以及項目矩陣,可以預測缺失的評分。
例如:有一張包含用戶對電影評分的表格,但不是每個人都對所有電影評分。SVD 就是幫你把這張表拆解成兩張更小的表,分別代表用戶和電影的特徵,而奇異值代表了數據中的重要性排序,如「喜劇」對推薦影響很大,那這個奇異值就會比較高。
NMF(Non-negative Matrix Factorization)
和SVD差不多但數據只能為正數
二、模型優化與評估指標
在優化推薦系統時,經常使用的評估指標包括:
RMSE(Root Mean Squared Error)
即數學統計中「標準差」的算法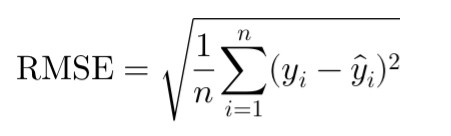
MAE(Mean Absolute Error)
即數學統計中「離均差」的算法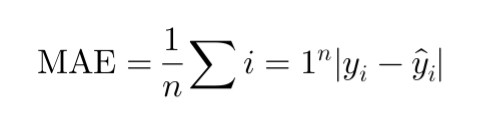
三、實作:創造推薦模型為用戶推薦電影
STEP 1 下載數據集
可以搜尋MovieLens Dataset從網站下載不同用戶對不同電影的評分紀錄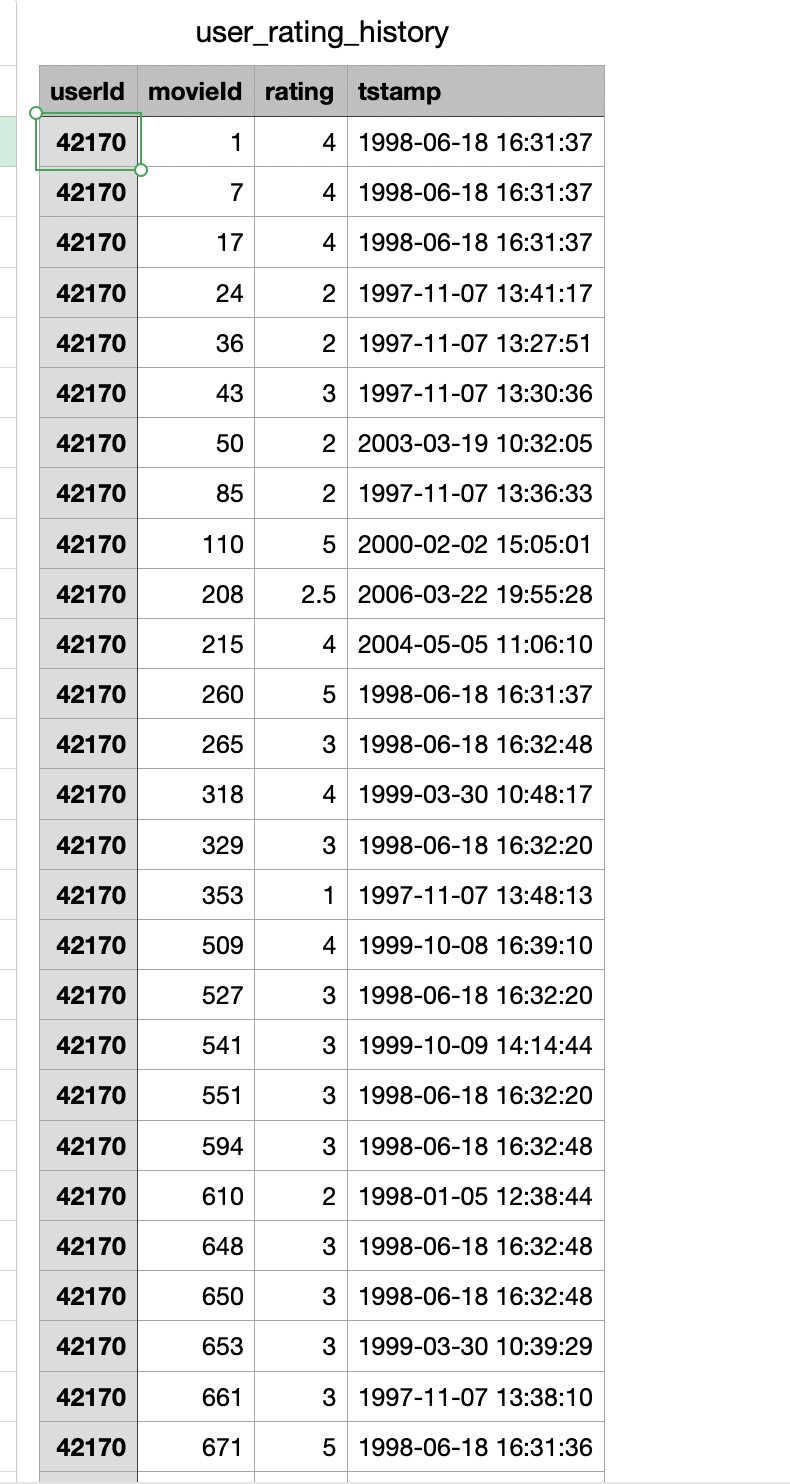
STEP 2 整理數據、生成SVD矩陣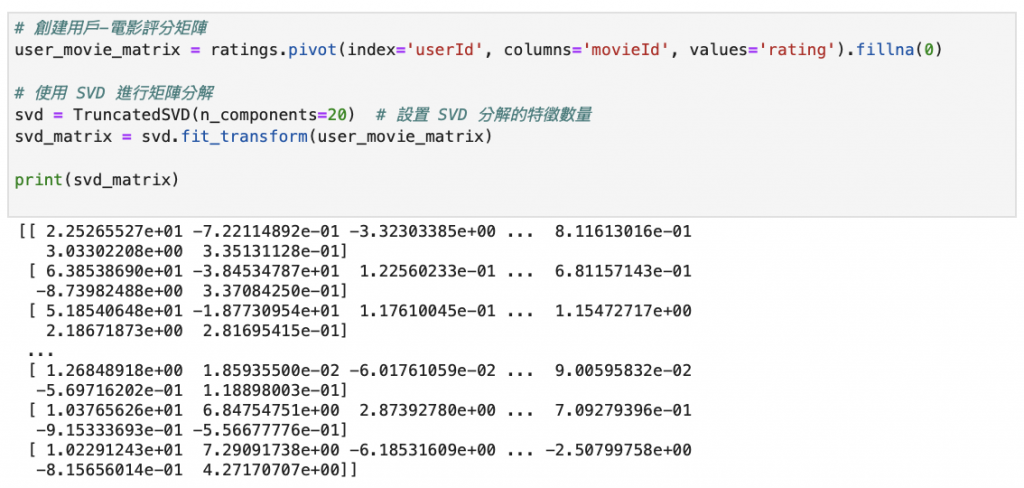
STEP 3 計算其RMSE、MAE評估指標,得出此模型和真實評分之差距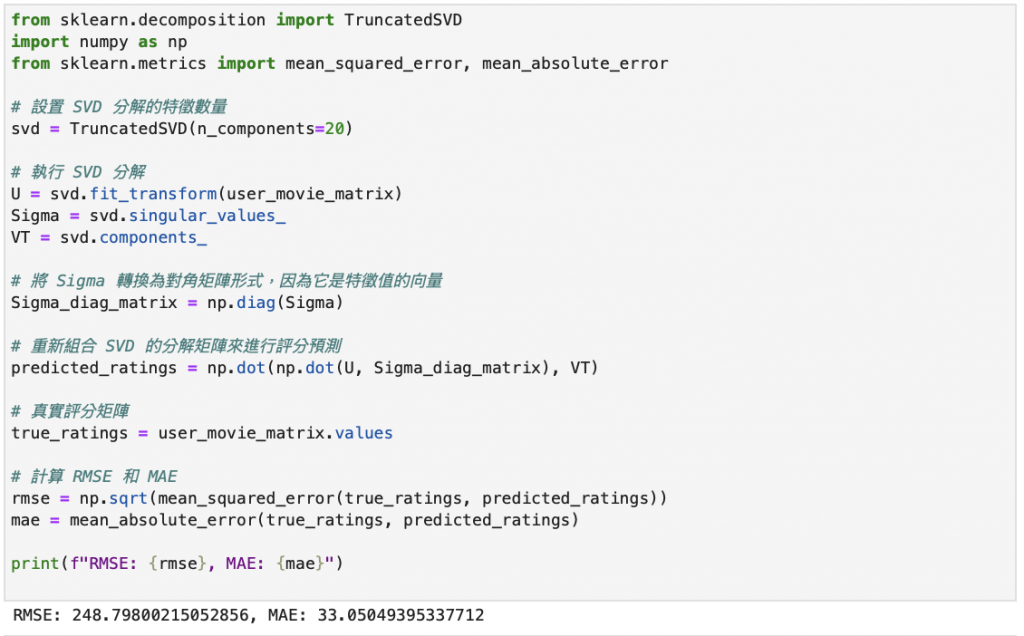
STEP 4 選定一個用戶,讓模型根據該用戶的評分排列出他可能會推薦的驗影前五名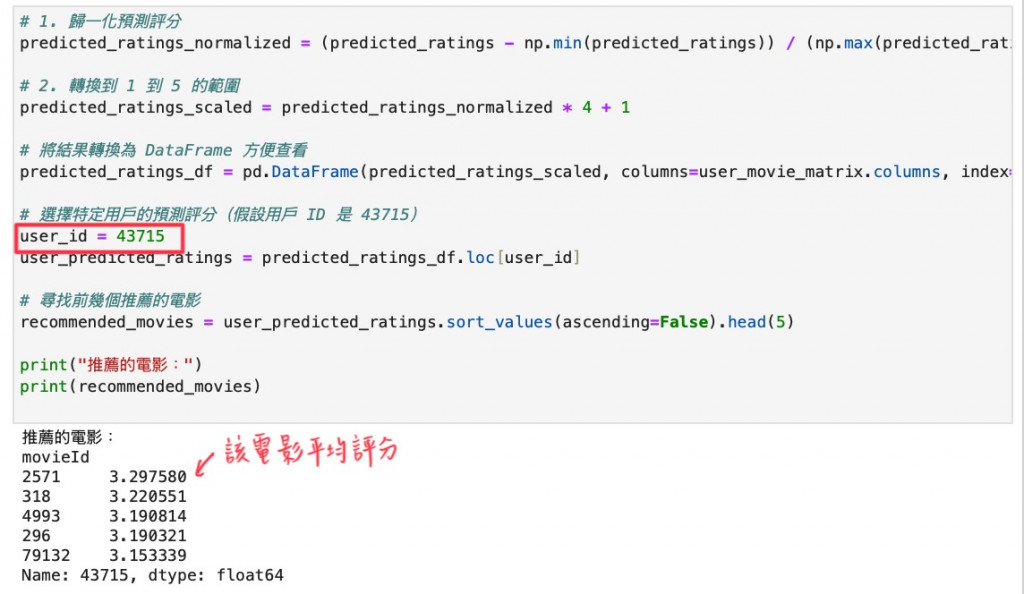
推薦系統不僅僅是依賴於用戶的歷史評分,還透過先進的數據處理技術來分析和預測用戶的需求。隨著技術的進步,這些系統將變得更加智能和個性化,能夠為每位用戶提供更符合他們興趣的內容。

