BERT 不僅僅是個能讀懂文字的模型,它還能通過理解上下文來識別語句中的情感。今天,我們要揭開 BERT 如何成為情感讀者的神秘面紗,看看它如何通過「讀懂」文本來預測情緒。
一、BERT模型
在之前第六天的內容中,我們提到了自然語言處理(NLP)領域的一個強大模型——基於Transformer架構的BERT(Bidirectional Encoder Representations from Transformers)。BERT具有雙向語境理解能力,能夠同時考慮句子的前後文來預測隱藏的單詞,從而比傳統模型更精確地捕捉語義信息,特別適合處理各類語言任務如情感分類、問答系統等。
STEP 2 微調
完成預訓練後,在有標註的數據集上進行有監督的訓練,BERT 可以針對特定的任務進行微調,例如情感分類,權重會根據不同需求進行更新,使其能夠適應各種不同的 NLP 任務。
BERT的情感分類
BERT 可以被應用於多種語言處理任務,包括問答系統、文本生成、命名實體識別等。而在情感分類任務中,BERT 的雙向理解能力非常有用,主要為分析文本的情感傾向,分為三類:正面、負面和中立。情感分析通常涉及語義理解和上下文語境的捕捉,BERT 的架構就非常適合這樣的任務,不僅可以理解單詞的字面意思,還能通過上下文來推斷語句的隱含情感,像是區分出句子中的諷刺或雙關語。
優勢
1.BERT 的雙向上下文學習能力使其能夠更好地理解每個詞的真實語義。
2.預訓練在大規模語料庫上進行,具備強大的通用語言理解能力。微調可以讓它快速適應不同的下游任務,如情感分析。
3.模型可以根據需要進行擴展,例如處理多語言文本、對應更細的情感分類(如悲傷、憤怒、喜悅等)。
二、創造BERT模型
1.使用 Hugging Face 載入 BERT 模型
2.準備文本輸入
3.產生一個數據結構輸出,包含每個字詞的隱藏表示(隱藏狀態),表示字詞在語句中的語義。
4.結果會是一個大型的數字矩陣,每個字詞都有一個 768 維的數據表示,這些數據能幫助我們理解字詞的意思和上下文,也是主要BERT如何理解文字的方式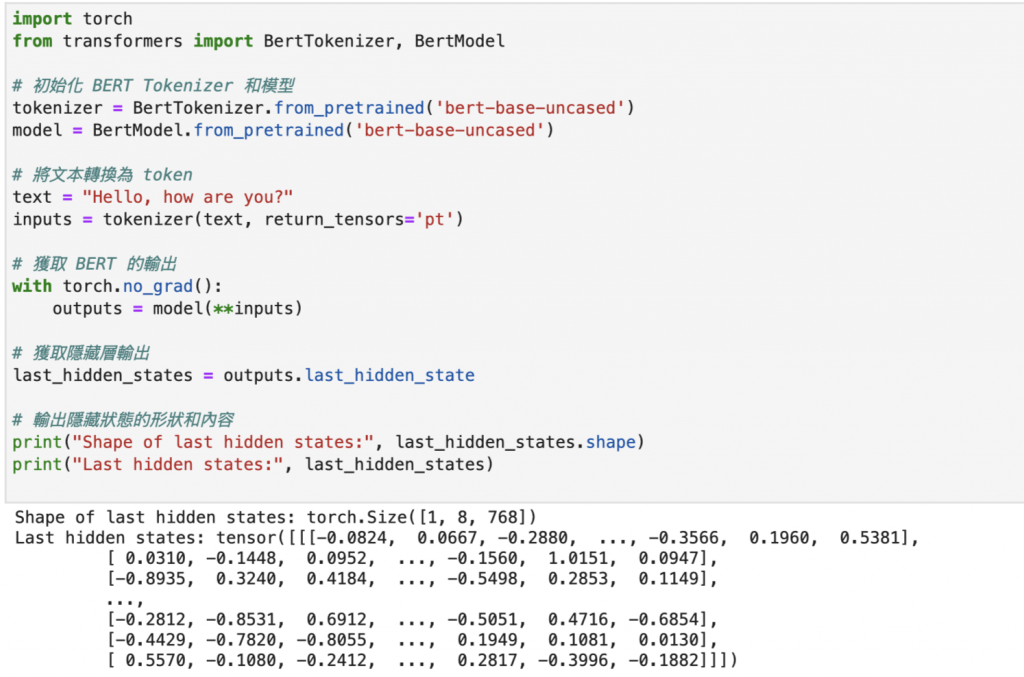
無論是面對短短的一句話,還是長篇的討論,BERT 都能精準捕捉語句中的情感。這就是為什麼它在情感分析、問答系統等任務中表現出色的原因,隨著技術的進步,BERT 這樣的模型將能夠幫助我們更好地與機器交流,甚至讓它們更加理解我們的情緒。

