在今天的內容中,我們主要討論以下兩個重點。第一個重點是如何建立一個通用的神經網路模型。因為在神經網路中,模型可能會因為色彩通道或長寬不相等的情況,需要不斷重新計算每一層的輸出,這種方式顯得非常不切實際。第二個重點是通過對資料集(Dataset)進行二次包裝,來解釋資料集與數據加載器(Dataloader)究竟做了哪些事情。
今天我們會用到昨日使用昨日建立的Trainer類別進行訓練,因此我們需要先將其文件命名為Trainer.py才能夠完成我們後續的步驟。
由於同樣是對圖像進行處理,在第一步我們同樣使用torchvision進行圖像前處理與正規化的動作。此外,我們需要多import昨日建立的Trainer類別來幫助我們進行訓練。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from Trainer import Trainer
# 資料轉換操作,將圖片數據正規化並進行標準化處理
transform = transforms.Compose([
transforms.ToTensor(), # 將圖片轉為張量
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 標準化
])
# CIFAR-10 類別名稱
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
# 載入 CIFAR-10 資料集 (訓練集與測試集)
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
在這裡,我們的操作與MNIST基本上沒有變化,唯一的差別是我們還需要定義CIFAR-10類別名稱。這是因為在深度學習中,我們所對應的標籤通常是數字而非文字,因為文字是無法直接計算損失值的。因此我們需要一個映射列表來對這些標籤進行轉換。
在 PyTorch 中,通常會將一個容器型態的資料交由資料加載器進行包裝。這麼做的主要原因是將資料切割成批量,便於模型進行訓練。此外我們還能指定在每個周期訓練完後重新打亂數據的排列,這樣模型就不會在每個周期中學到相同排列的訓練資料。只需要設定 shuffle=True 這個參數即可。在非 Windows 環境中,PyTorch 的資料加載器可以透過設定 num_workers 來進行平行處理資料,但在 Windows 環境中,該值不能超過 0,否則程式會出現錯誤。
# 將資料加載器的輸出調整為字典格式以符合 Trainer 的需求
class DatasetWrapper(torch.utils.data.Dataset):
def __init__(self, dataset):
self.dataset = dataset
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
data, label = self.dataset[idx]
return {'input': data, 'labels': label} # 對應Trainer的格式使用字典存放
資料加載器通常包括三個主要部分:__init__、__len__ 和 __getitem__。其中,__init__ 負責初始化資料集,這點大家應該已經很熟悉了。__len__ 則用於返回資料集的大小,讓我們可以使用 len() 函數來計算其長度。至於 __getitem__,這是資料加載器的核心部分。當我們使用 data_loader[index] 語法來存取資料時,__getitem__ 會被調用,返回對應索引的資料。這種按需存取的方式特別適合處理大型資料集,避免一次性載入所有資料,從而節省記憶體。
# 重新包裝資料加載器
trainloader_wrapped = torch.utils.data.DataLoader(DatasetWrapper(trainset), batch_size=32, shuffle=True)
testloader_wrapped = torch.utils.data.DataLoader(DatasetWrapper(testset), batch_size=32, shuffle=False)
print(next(iter(trainloader_wrapped))['input'].shape)
# -----輸出-----
(32, 3, 32, 32)
接下來我們只需要將剛剛下載的資料傳入該類別中,就能讓資料在每次迭代時以批量方式運行。這裡我們還展示了每一筆迭代出來的圖片大小,其輸入維度是 (batch_size, input_channel, height, width)。
同樣的,我們可以先繪製圖片來觀察這些圖片的特徵。在這裡我們直接使用dataloader來顯示圖片,但需要注意的是,由於我們在第一步驟中將圖像從(height, width, input_channel)轉換成(input_channel, height, width),並且進行了正規化(公式為(image - mean) / std),因此其還原公式為img_grid * std + mean,並且在顯示時需要將其維度轉換回來。
# 顯示圖片的工具函數
def imshow(dataloader, num_images=8):
dataiter = iter(dataloader)
images, labels = next(dataiter).values() # 取得一個批次的圖片和標籤
# 隨機選擇 num_images 張圖片
selected_images = images[:num_images]
selected_labels = labels[:num_images]
# 把多張圖片組合成一個網格
img_grid = torchvision.utils.make_grid(selected_images, nrow=num_images)
# 反正規化
# 由於我們設置的mean和std都是0.5,因此具體公式為`img_grid / 2 + 0.5`。
img_grid = img_grid / 2 + 0.5
# 轉換維度以適應 matplotlib 的顯示要求 (C, H, W -> H, W, C)
npimg = img_grid.permute(1, 2, 0).numpy()
# 顯示圖片
plt.imshow(npimg)
plt.axis('off') # 隱藏座標軸
# 設置標籤
num_per_row = min(num_images, 8) # 每行最多顯示8張圖片
for i in range(num_images):
plt.text(i * (npimg.shape[1] // num_per_row) + 5, npimg.shape[0] - 5, f'{selected_labels[i].item()}',
color='white', fontsize=12, ha='center', backgroundcolor='black')
plt.show()
imshow(trainloader_wrapped)

而當程式執行過後我們就可以看到其對應的圖片與類別
前天我們說到,在計算卷積神經網路模型時,需要計算每一層的卷積神經網路輸出維度。這是因為 input_shape_H 與 input_shape_W 在遇到不同資料集時,輸出維度會有所不同。這時進入全連接層就可能會導致模型發生 shape error 的問題。
因此我們可以將前天提到的卷積神經網路輸出公式代入,以更好地計算每一層的輸出。如此一來,當我們更換資料集或放大縮小圖像時,模型就能夠自動適應其資料,以下將所有模型的輸出與輸入細節寫入註解中。
# 定義 CNN 模型
class CNNModel(nn.Module):
def __init__(self, input_channels=3, input_shape_H=32, input_shape_W=32, output_shape = 10):
super(CNNModel, self).__init__()
# 第一層卷積:將輸入圖像 (batch_size, 3, 32, 32) 經過 32 個 3x3 的卷積核 (padding=1)
# 輸出形狀為 (batch_size, 32, 32, 32)
self.conv1 = nn.Conv2d(input_channels, 32, 3, padding=1)
# 第二層卷積:將 (batch_size, 32, 32, 32) 經過 64 個 3x3 的卷積核 (padding=1)
# 輸出形狀為 (batch_size, 64, 16, 16)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
# 最大池化層:每次將高和寬減半
# 在第一次池化後,輸出形狀為 (batch_size, 32, 16, 16)
# 在第二次池化後,輸出形狀為 (batch_size, 64, 8, 8)
self.pool = nn.MaxPool2d(2, 2)
# 計算全連接層輸入的特徵圖大小
# conv_output_H = input_shape_H // 4 = 32 // 4 = 8
# conv_output_W = input_shape_W // 4 = 32 // 4 = 8
conv_output_H = input_shape_H // 4
conv_output_W = input_shape_W // 4
# 全連接層1:輸入來自卷積層的展平結果,4096 = 64 * 8 * 8
# 輸出 256 維度,輸入形狀 (batch_size, 4096),輸出形狀 (batch_size, 256)
self.fc1 = nn.Linear(64 * conv_output_H * conv_output_W, 256)
# 全連接層2:輸入 256 維度,輸出 64 維度,輸出形狀 (batch_size, 64)
self.fc2 = nn.Linear(256, 64)
# 全連接層3:輸入 64 維度,輸出 output_shape 維度,對應 output_shape 個類別
# 輸出形狀為 (batch_size, output_shape)
self.fc3 = nn.Linear(64, output_shape)
self.criterion = nn.CrossEntropyLoss()
def forward(self, input, labels):
# 第一層卷積 + 池化:將輸入 (batch_size, 3, 32, 32) -> (batch_size, 32, 16, 16)
x = self.pool(torch.relu(self.conv1(input)))
# 第二層卷積 + 池化:將輸入 (batch_size, 32, 16, 16) -> (batch_size, 64, 8, 8)
x = self.pool(torch.relu(self.conv2(x)))
# 展平:將輸入 (batch_size, 64, 8, 8) 展平成 (batch_size, 4096)
x = x.view(x.size(0), -1)
# 全連接層1:輸入 (batch_size, 4096) -> (batch_size, 256)
x = torch.relu(self.fc1(x))
# 全連接層2:輸入 (batch_size, 256) -> (batch_size, 64)
x = torch.relu(self.fc2(x))
# 全連接層3:輸入 (batch_size, 64) -> (batch_size, 10)
x = self.fc3(x)
return self.criterion(x, labels), x # 回傳Loss與前向傳播結果。
model = CNNModel()
在這裡還有一個很重要的點,為了符合我們的Trainer設計,forward(self, input, labels)中的input和labels必須要與資料載入器中定義的字典鍵(key)相同,並且在回傳時要把損失的位子設定成損失值,否則程式就會發生錯誤。
由於訓練器已經建立完畢,因此只需將相關參數傳入即可。這裡因為我們沒有從訓練資料集中分割出驗證資料集,所以直接用測試資料集來代替。
# 定義損失函數和優化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 建立 Trainer 實例並開始訓練
trainer = Trainer(
epochs=10,
train_loader=trainloader_wrapped,
valid_loader=testloader_wrapped,
model=model,
optimizer=[optimizer], # 當初設計的時候有考慮多的優化器,因此要用容器型態
)
# 開始訓練
trainer.train(show_loss=True)
# -----輸出-----
Train Epoch 2: 100%|██████████████████████████████████████████████████| 1563/1563 [00:14<00:00, 109.76it/s, loss=0.853]
Valid Epoch 2: 100%|████████████████████████████████████████████████████| 313/313 [00:01<00:00, 159.68it/s, loss=0.941]
Saving Model With Loss 0.83767
Train Loss: 0.74112| Valid Loss: 0.83767| Best Loss: 0.83767
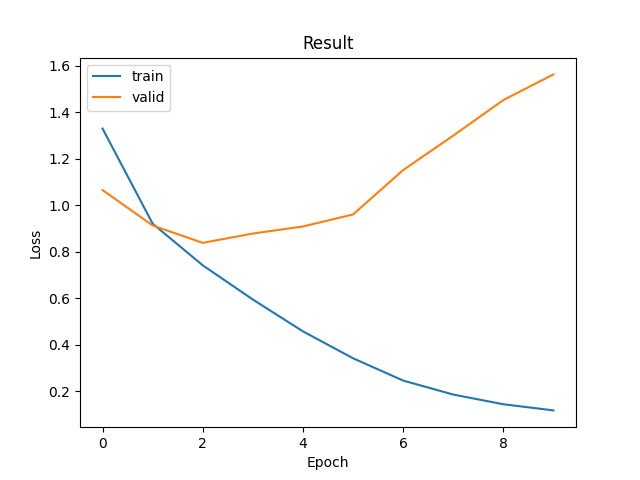
在這裡我們發現,模型在第三次訓練時達到了最佳損失,隨後的過程中出現了過擬合的現象。我們也看到儘管損失值達到了約0.83已經在可用範圍內,但明顯的有優化空間。
但是我不會先告訴你該如何優化的答案,而是希望你能先自行測試與調整這些參數設計與模型結構。這樣做的原因是,這些調整將成為實際應用中的寶貴經驗。不過我能給你一個提示:為什麼模型損失值下降如此之快,以及模型訓練損失值為何會持續下降。
在今天的內容中,我們學習了如何使用昨天建立的Trainer類別來訓練卷積神經網路模型,並深入探討了資料加載器的運作原理與優勢。並且也知道了該如何建立了一個簡單的卷積神經網路模型,並自動計算每一層的輸出維度,已適應不同的資料輸入大小。
並且我們使用Trainer進行模型訓練,並繪製出損失值之間的相互關係,讓我們能一眼察覺到過度擬合的問題。不過,今天的內容還沒結束。你可以嘗試進一步優化模型,例如調整學習率、批次大小、網路層數,甚至是使用不同的優化器或正則化方法來提升模型的性能。這些實踐不僅能增強你的深度學習技能,也能幫助你更好地理解模型訓練中的細節。

