今天是整個系列的最後一天啦,在系列結尾,我會告訴你如何訓練一個屬於自己的聊天機器人。這在企業的內部培訓或解答系統中非常有用。我們只需要請每位員工列出他們可能遇到的幾個問題,並給予對應的答案即可。而聊天機器人的訓練並不像我們想像中那麼困難。我們其實只要按照今天介紹的幾個簡單步驟,之後只需要更換資料集的內容,就能培訓出不同版本的聊天機器人。現在讓我們來看看如何使用LLaMA 3這一個強大模型吧。另外在這次我們同樣使用PTT鄉民的語料庫來幫助我們訓練出一個充滿鄉民風格的聊天機器人。
在我們GPT的章節中可以知道在轉換資料格式時其實非常的麻煩,而在LLaMA中又有自己的獨特轉換方式,例如我們想要賦予系統一個Instruction時就必須讓該系統的指令放置在<|begin_of_text|><|start_header_id|>system<|end_header_id|>0x0A0x0A這是系統指令<|eot_id|>這一段指令中其中0x0A是換行符號,輸入與模型對應的回復也要轉換成相對應的格式。而會出現這樣的問題,是因為LLaMA基本上是一個支援多輪對話的模型。因此,每一輪的對話會疊加在這些Token上,所以需要使用不同的Token來判斷角色、對話內容以及對話結尾。
那麼LLaMA模型中的Token系統是如何工作的呢?每個Token標籤都有其特定的功能。例如,<|start_header_id|><|end_header_id|>這組Token用來標示角色,這樣模型便可以區分不同對話者。而當模型讀取這組Token時,它會知道接下來的信息是該角色的台詞,這些台詞在實際對應的對話中是由兩個0x0A來間隔開。除此之外,<|begin_of_text|><|eot_id|>這組Token則負責界定某一角色對話的開頭和結尾,以便模型能夠正確了解每段對話的開始和結束位置。這整套系統使得LLaMA模型能夠有效管理和處理多輪對話,確保每一個對話回合之間的上下文得以正確理解和關聯。這樣一來,模型便能夠在多輪對話中保持高水準的連貫性和精確性。
不過,在 Hugging Face 的最新版本中,已經幫我們設定了一個 apply_chat_template 方法。因此,我們可以直接通過傳入一個由多個字典包圍住的列表,快速地轉換這些格式。其方式很簡單,就是通過 role 賦予我們要給予的指令與對應的文字到 content 中。最後,我們可以通過 append 等方式,將對話依序通過該方法轉換。這樣子,在後續多輪流的對話中,我們只需要不斷地 append 使用者和模型的回覆,就能讓用戶和使用者順利地進行聊天。
# 讀取Tokenizer
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
'meta-llama/Meta-Llama-3-8B-Instruct',
trust_remote_code=True,
add_special_tokens=False
)
tokenizer.pad_token = tokenizer.eos_token
system_format = {"role": "system", "content": '這是系統指令'}
question_format = {"role": "user", "content": '這是用戶的輸入'}
answer_format = {"role": "assistant", "content": '這是模型回復'}
chat_format = tokenizer.apply_chat_template([system_format, question_format, answer_format])
print(tokenizer.decode(chat_format))
# ----- 輸出 -----
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
這是系統指令<|eot_id|><|start_header_id|>user<|end_header_id|>
這是用戶的輸入<|eot_id|><|start_header_id|>assistant<|end_header_id|>
這是模型回復<|eot_id|>
同樣的我們使用 Hugging Face 提供的 BitsAndBytesConfig 來進行模型的量化動作,將原本 32-bit 浮點數轉換成更低精度4-bit使模型能使用一張消費及險卡進行訓練。
from transformers import BitsAndBytesConfig
import torch
quantization_params = {
'load_in_4bit': True,
'bnb_4bit_quant_type': "nf4",
'bnb_4bit_use_double_quant': True,
'bnb_4bit_compute_dtype': torch.bfloat16
}
bnb_config = BitsAndBytesConfig(**quantization_params)
而在上述的參數中我們基本上不會有變動,雖然可以直接照抄但我們還是先來理解一下這些參數的用處:
load_in_4bit: 將模型的權重加載為 4-bit 的精度。bnb_4bit_quant_type: 設定量化的類型為 nf4(Normalized Float 4),這是一種比較先進的量化技術,能在低精度的條件下保持更好的數值表現。bnb_4bit_use_double_quant: 開始雙重量化技術,開啟後會將權重和計算的中間數據都會被壓縮,節省更多資源。bnb_4bit_compute_dtype: 設定計算時的精度類型為 torch.bfloat16,這是一種比 32-bit 更低精度但表現較穩定的浮點數格式,在不顯著降低模型精度的前提下,能減少計算資源需求,但只有部分顯卡支援bfloat16的運算,若顯卡不支援則可以轉換成float16。這裡與之前並無太大的差異,唯一的不同之處在於我們使用了Accelerator來判斷顯示卡的位置。這是因為在訓練大型語言模型時,可能會面臨多張顯示卡訓練的需求。如果有多張顯示卡的話,使用Accelerator可以自動將模型拆分並分配到多張顯示卡上進行訓練。當然如果只有一張顯示卡,使用to(device)也是可以的。
from accelerate import Accelerator
from transformers import AutoModelForCausalLM
device_map = {"": Accelerator().local_process_index}
model = AutoModelForCausalLM.from_pretrained(
'meta-llama/Meta-Llama-3-8B-Instruct',
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map=device_map,
use_cache=False,
)
print(model)
# ----- 輸出 -----
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear4bit(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear4bit(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear4bit(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear4bit(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear4bit(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=128256, bias=False)
而這時我們把模型的結構print出來時可以看到self_attn下的Q、K、V、O層,而這幾個參數也是我們下一個步驟中需要進行加入LoRA適配器的部分。
我們把剛剛找到的Attention層資料寫入到target_modules以幫助我們在這些層中加入LoRA適配器,而我們在這裡不需要手動凍結其他網路層,這是因為在peft庫當我們自動加入LoRA層時就會幫我們自動凍結target_modules的參數。
在進行4-bit類型的訓練時,我們通常會使用prepare_model_for_kbit_training進行包裝。這個方法主要用於在進行低位量化的過程中,為模型做好準備,使其在記憶體有限的環境下可以更高效地進行訓練和推理,同時儘量減少量化帶來的性能損失。完成這個步驟後,接著使用get_peft_model將剛剛設定好的peft_config傳入,就完成模型的配置了。
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
peft_params = {
'r': 32,
'target_modules': ["q_proj", "k_proj", "v_proj", "o_proj"],
'lora_dropout': 0.1,
'task_type': "CAUSAL_LM",
}
peft_config = LoraConfig(**peft_params)
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=True)
model = get_peft_model(model, peft_config)
print(model)
最後,我們來將NEFtune的方法加入到模型中。在這裡,我們不是採用原始論文的方法來找出模型的Embedding層,而是先通過unwrap_model的方式找出模型的Embedding層,再用register_forward_hook的方式讓模型在前向傳播時先執行NEFtune公式,再傳遞到下一層。我已經將相關的知識寫在註解中。因此加入NEFtune的程式可以撰寫成以下形式。
from transformers.modeling_utils import unwrap_model
def activate_neftune(model, neftune_noise_alpha = 5):
unwrapped_model = unwrap_model(model)
embeddings = unwrapped_model.base_model.model.get_input_embeddings()
embeddings.neftune_noise_alpha = neftune_noise_alpha # 讓Embedding層的__init__多一個neftune_noise_alpha參數
# hook embedding layer
hook_handle = embeddings.register_forward_hook(neftune_post_forward_hook)
return model
def neftune_post_forward_hook(module, input, output):
# 公式來源:https://github.com/neelsjain/NEFTune
# 論文網址:https://arxiv.org/abs/2310.05914
if module.training: # 讓他再訓練時有用而已
# 實現NEFtune公式
dims = torch.tensor(output.size(1) * output.size(2))
mag_norm = module.neftune_noise_alpha / torch.sqrt(dims) # 這裡的neftune_noise_alpha就是在__init__的參數
output = output + torch.zeros_like(output).uniform_(-mag_norm, mag_norm)
return output
model = activate_neftune(model)
而在我們這次的對話集中由於是單輪對話格式,因此user與assistant只會有一個,而我在這個過程中也加入了一個簡單的Instruction: 你是一個zh-tw版本的聊天機器人,加強模型的回覆可以用繁體中文進行聊天與回覆的能力。。
import pandas as pd
def transform_format(questions, answers, system='你是一個zh-tw版本的聊天機器人'):
context = []
for q, a in zip(questions, answers):
system_format = {"role": "system", "content": system}
question_format = {"role": "user", "content": q}
answer_format = {"role": "assistant", "content": a}
context.append([system_format, question_format, answer_format])
return context
# 讀取CSV檔案
df = pd.read_csv('Gossiping-QA-Dataset-2_0.csv')
# 提取問題和答案的列表
questions = df['question'].tolist()[:5000]
answers = df['answer'].tolist()[:5000]
# 轉換格式
formatted_context = transform_format(questions, answers)
不過由於這次資料集的數量過於龐大,而模型又有著8B的參數量,因此為了節省時間,我將資料限制在5000個,這樣我們才能夠順利進行Demo。
這次的DataLoader建立起來比較簡單。因為在聊天版本的大型語言模型中,無論是輸入的文字還是答案,都是下一輪對話的一部分,模型應該能更好地理解這些上下文關係。因此,我們只需要對Padding的Token進行處理即可。
import torch
from torch.utils.data import Dataset, DataLoader
# 定義自定義 Dataset
class PTTDataset(Dataset):
def __init__(self, formatted_context, tokenizer):
self.formatted_context = formatted_context
self.tokenizer = tokenizer
def __getitem__(self, index):
return self.formatted_context[index]
def __len__(self):
return len(self.formatted_context)
def collate_fn(self, batch):
formatted_contexts = self.tokenizer.apply_chat_template(batch, padding=True, return_dict=True, max_length=8192, return_tensors='pt', truncation=True)
attention_mask = formatted_contexts['attention_mask']
labels = formatted_contexts['input_ids'].clone()
labels[attention_mask == 0] = -100
formatted_contexts['labels'] = labels
return formatted_contexts
# 建立資料集
trainset = PTTDataset(formatted_context, tokenizer)
validset = PTTDataset(formatted_context, tokenizer)
# 創建 DataLoader
train_loader = DataLoader(trainset, batch_size=4, shuffle=True, collate_fn=trainset.collate_fn)
valid_loader = DataLoader(validset, batch_size=4, shuffle=True, collate_fn=validset.collate_fn)
而在訓練模型的部分我們同樣使用get_cosine_with_hard_restarts_schedule_with_warmup進行排程,而後續的動作都與之前相同,無任何的差異。
import torch.optim as optim
from transformers import get_cosine_with_hard_restarts_schedule_with_warmup
from trainer import Trainer
# 訓練設置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
optimizer = optim.AdamW(model.parameters(), lr=5e-5)
scheduler = get_cosine_with_hard_restarts_schedule_with_warmup(
optimizer,
num_warmup_steps=len(train_loader) * 0.2,
num_training_steps=len(train_loader) * 10,
num_cycles=1,
)
trainer = Trainer(
epochs=10,
train_loader=train_loader,
valid_loader=valid_loader,
model=model,
optimizer=[optimizer],
scheduler=[scheduler],
early_stopping=3,
device=device
)
trainer.train()
# ------ 輸出 -----
Train Epoch 9: 100%|██████████| 1250/1250 [12:01<00:00, 1.73it/s, loss=1.960]
Valid Epoch 9: 100%|██████████| 1250/1250 [04:07<00:00, 5.04it/s, loss=2.114]
Saving Model With Loss 1.80411
Train Loss: 1.83201| Valid Loss: 1.80411| Best Loss: 1.80411
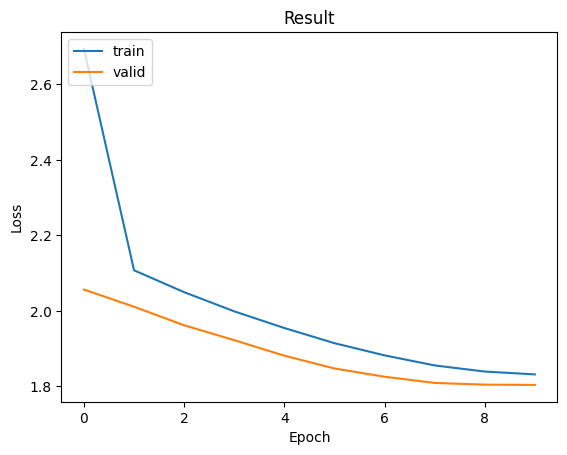
而在訓練曲線上可以發現在這9次的訓練中沒有發生過度擬合的狀況,且模型正在進行收斂,而對於這種狀況我們其實還可以繼續訓練,因為這時模型的損失值明顯還能在下降。
最後讓我們來看看生成的效果。在生成時,我們要注意一點,也就是和使用Tokenizer時一樣,由於該模型沒有Padding Token,因此我們要通過 model.generation_config.pad_token_id = tokenizer.eos_token_id 來設定這個數值。不然程式會出現警告(其實這不是很大的問題,因為生成時不該出現PAD token)。
model.load_state_dict(torch.load('model.ckpt'))
model.eval()
model.generation_config.pad_token_id = tokenizer.eos_token_id
messages = [
{"role": "system", "content": '你是一個zh-tw版本的聊天機器人'},
{"role": "user", "content": 'PTT是甚麼阿?'},
]
input_data = tokenizer.apply_chat_template(messages, padding=True, return_dict=True, max_length=8192, return_tensors='pt', truncation=True).to(device)
ids = model.generate(**input_data)
print(tokenizer.decode(ids[0]))
# ----- 輸出 ------
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
你是一個zh-tw版本的聊天機器人<|eot_id|><|start_header_id|>user<|end_header_id|>
PTT是甚麼阿?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
一個垃圾論壇<|eot_id|>
而我們可以看到,我們僅僅使用了10個訓練週期和5000筆資料,就讓模型成為了一個沒素質的聊天機器人。因此,我們也可以發現這些大型語言模型的能力其實非常強大。這一點歸功於它具備強大的基礎知識,所以在微調時才能更好地收斂損失值。
我們的從零開始學AI:數學基礎與程式碼撰寫全攻略的30天教學終於結束啦。在這段期間,你可能會發現我在前幾天特別強調數學公式的講解,這是因為我希望你們能理解這些基礎公式的用途與用法。通過這樣的學習,你是否能夠在後續的模型中更好地理解這些作者在設計模型時的想法呢?
因此在預訓練模型之後,我基本上不再詳細講解這些公式,因為這些公式大致相同。唯一的差異通常可以用文字講解相關理念來說明,就算我們想模仿這些做法時,我們只需參考原始論文的程式碼即可,因此對數學公式的依賴相對減少。
而在這30天的內容中,我的主要目的是幫助你們慢慢理解相關領域的發展與應用,更重要的是我要傳達的是該如何遇到問題後找到解決的方向,而不是單純教你如何使用最新技術。這樣一來當你們遇到問題時,可以更有條理地分析問題並找到解決方法,而不會成為我們在AI界所說的“套模仔”。
這次的內容主要是想把我在研究所中自學這些AI知識的過程整理成一篇文章讓大家可以跟我一樣慢慢的進入AI的領域,所以在這篇文章中的內容我在文章中的細節中加入了我以前遇過的問題,並且把我踩過的坑告訴大家,來增加你學習的速度,當然一開始不一定要馬上的理解這些數學式而是先知道相關的概念即可,這樣子你至少會有著撰寫程式的能力,而當你有這能力後你會慢慢的理解這些數學式,而今年也是我第三年參加鐵人賽了,從懵懂無知的AI人蛻變到現在有能力站上AI競賽的舞台,而這次撰寫內容的過程只能說是壓力山大啊,雖然說寫作的速度變快了,但對於內容的壓縮與編排真的是我這次最大的挑戰,希望這次的學習內容能對你們有所幫助,那麼我們明年再見(?

