在最新的自然語言技術進展中,語言模型的規模變得越來越龐大,模型的參數量從數百萬到數十億,甚至上千億。雖然這些大型語言模型在許多任務中表現出卓越的能力,但也帶來了嚴峻的計算效能與記憶體空間問題。例如:LLaMA 3 擁有 4050 億個參數,僅進行微調就至少需要 3-4 張 H100 顯卡(每張內存 80GB,且單張售價近百萬台幣),這對大多數研究機構和企業來說是巨大的負擔。
因此有許多研究開始探索如何在有限資源下高效微調這些大型語言模型。今天我們要特別介紹的 QLoRA 就是一種這樣的方法,它能夠在不犧牲模型性能的前提下,顯著減少計算和存儲需求。且我還會介紹一種針對大型語言模型的優化技術 NEFTune,這是一種正規化技術,為大型語言模型提供了另一種發展方向。
QLoRA(Quantized Low-Rank Adaptation)是一種針對大型語言模型的高效微調技術。其目標是減少模型參數數量和計算需求,通過量化(Quantization)和低秩適應(Low-Rank Adaptation)技術達到高效微調的效果。具體來說該技術通過量化模型來降低精度,使其能夠用更少的存儲空間在記憶體中運行。這個概念就像是將float64的資料轉換成float32一樣,雖然這會減少記憶體的消耗,但也會導致部分精度的丟失。
當然QLoRA技術中的模型並非如此簡單,其量化技術通常基於固定點量化(Fixed-Point Quantization)與動態範圍量化(Dynamic Range Quantization)。對於有興趣深入了解的讀者,可以參閱原論文中的詳細介紹。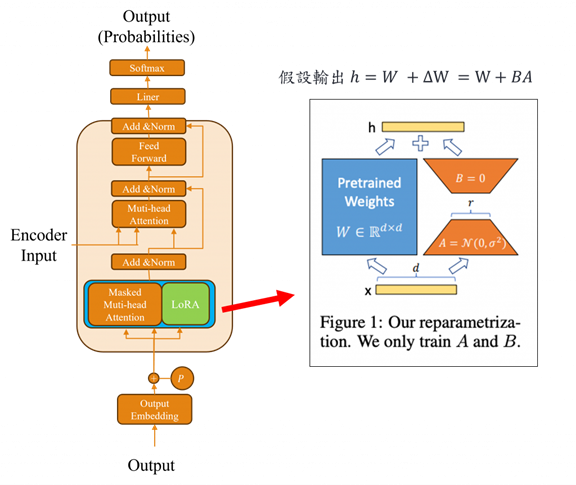
不過量化後的模型在推理能力上其實並沒有顯著減少效能,甚至可以說是完全沒有變化。因此量化後的模型往往能使用更少的資源來進行文字內容的生成。但是對於微調模型而言則不然,由於大型語言模型是多層的Transformer Decoder結構,**在經度丟失的情況下進行微調時,模型可能會出現一步錯步步錯的現象,這很容易導致模型不知道何時該生成EOS Token,或者推理出的內容出現嚴重問題。**總體而言對比全量微調(我們之前的訓練方式稱為全量微調),這種方法會導致模型性能明顯下降。
因此LoRA這一方法被用來解決這個問題的,如果我們沒辦法調整原本的模型架構,那麼我們可以訓練一個適配器,並外掛在模型旁邊來輔助該模型嗎?答案是可以的。所以在 LoRA 這一方法中,在微調模型時會凍結大部分模型權重僅調整少量的參數以減少計算量。而 LoRA 的方式是通過微調過程中需要更新的權重矩陣 ΔW,將其分解成兩個較小的矩陣 A 和 B,來達到降低計算需求的效果: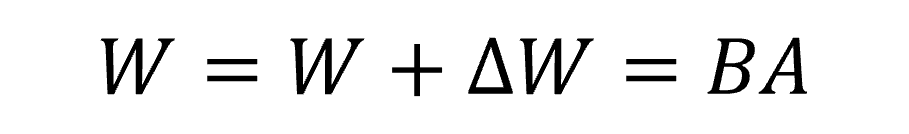
這樣的矩陣分解方式可以顯著減少所需的存儲和計算資源。例如當 r = 2 時,A 和 B 只會是兩個列向量和行向量。當 r = 3 時,則變成三個列和行向量。這種方法能有效降低訓練時的計算複雜度,同時保持模型的高效能。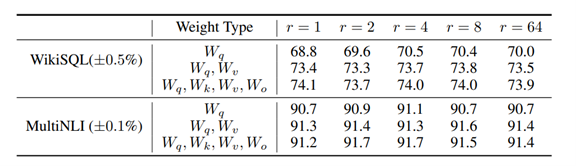
而我們通常會將其LoRA框架加入在Transformer的Q、K、V與輸出層O上,而根據研究顯示LoRA這種微調方式在 WikiSQL 和 MultiNLI 等數據集上的表現與傳統微調幾乎無異。但更重要的是該方式顯著的減少了模型在微調時的時間。
NEFTune(Noisy Embeddings Improve Instruction Finetuning)是一種針對語言模型微調的創新方法,**通過在嵌入層中引入噪音(如高斯分布噪音),來提高模型面對不確定數據的性能表現。**這樣的技術模擬了現實世界中數據的隨機性和變異,類似於訓練飛行員在各種惡劣天氣下駕駛飛機,以便應對突發狀況。對語言模型來說,這樣的噪聲正規化技術能有效防止模型過度擬合訓練數據,使其學會如何在「有噪音」的環境中依然準確執行指令。
而另外一點適在訓練過程中,神經網絡的每一層往往需要設定不同的學習率。例如,詞嵌入層的學習率通常需要較低,否則容易過度擬合特定的數據特徵。通過引入噪音,這種技術與數據增強技術相似,能提高模型的泛化能力,幫助其在面對新情況時表現出更好的適應性。這樣的策略能促使模型學習更廣泛的特徵和模式,並有效提升模型的整體性能。而其程式碼的實現也非常簡易讓我們先看看原始的Paper所開放出來的寫法:
from torch.nn import functional as F
def NEFTune(model, noise_alpha=5):
def noised_embed(orig_embed, noise_alpha):
def new_func(x):
# during training, we add noise to the embedding
# during generation, we don't add noise to the embedding
if model.training:
embed_init = orig_embed(x)
dims = torch.tensor(embed_init.size(1) * embed_init.size(2))
mag_norm = noise_alpha/torch.sqrt(dims)
return embed_init + torch.zeros_like(embed_init).uniform_(-mag_norm, mag_norm)
else:
return orig_embed(x)
return new_func
##### NOTE: this is for a LLaMA model #####
##### For a different model, you need to change the attribute path to the embedding #####
orig_forward = model.base_model.embed_tokens.forward
model.base_model.embed_tokens.forward = noised_embed(orig_forward, noise_alpha)
return model
在原始的論文中,由於測試使用了LLaMA 2,當提取其嵌入架構時,我們使用了model.base_model.embed_tokens.forward。接著將原始的嵌入層通過new_func加入噪音。我們可以看到,這個方法非常簡單,首先通過提取seq_len * 嵌入特徵數來獲取當前輸入的資料長度,然後通過嵌入維度的平方根調整噪音的幅度,並用uniform_(-mag_norm, mag_norm)生成一個範圍為[-mag_norm, mag_norm]的雜訊,並將其加入到原始的嵌入層中,而這簡單的實現就能讓模型瞬間提升了許多能力。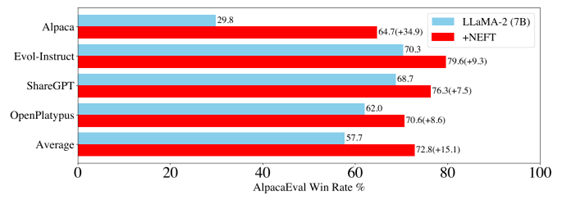
研究結果顯示,NEFTune 能在更複雜、多變的環境下進行指令微調訓練,使模型的表現達到顯著進步。實驗顯示在某些數據集上,NEFTune 的引入甚至能帶來將近兩倍的性能提升。這種技術展示了噪音注入對語言模型微調的強大潛力,進一步拓展了模型在真實世界應用中的實用性。
這次主要是為了傳達了幾個重點,首先在量化模型下進行微調並不太理想,雖然能取得一定效果,但生成出的結果多半會有問題。正確的做法是凍結原始參數,加入適配器以達到微調的目的。由於我們進行了量化並凍結參數,即使加入了多個適配器,訓練速度依然會變快。
另外NEFTune是一種專門針對大型語言模型的方法。大型語言模型具有強大的推理能力,因此通過加入噪音的方式反而能增強效能。然而,如果將此技術應用於類似BERT的模型,效果只會更差。這兩項技術為大型語言模型的高效微調提供了創新解決方案,能以更少的硬體成本實現更佳的訓練效果和推理能力,適合應對真實世界中的資源挑戰。


 iThome鐵人賽
iThome鐵人賽