
[圖片生成:DALL-E]
在完成特徵選擇和數據切分後,我們需要根據 scikit-learn 的 cheatsheet 選擇合適的演算法📘,這是提升模型性能的關鍵步驟🔑。除了 cheatsheet 的建議,我們也應該嘗試不同的常見演算法,以擴展選擇範圍。🎯也方便在接下來的模型評估階段比較不同模型的表現,選擇最佳解決方案。🏆
[source]
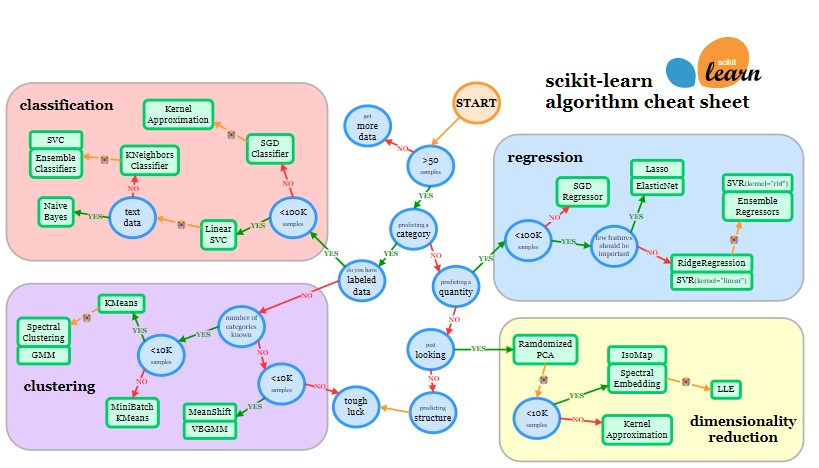
回顧之前的 scikit-learn cheatsheet,我們可以根據我們的題目進行對應,從 START 開始,步驟如下:
cleaning_data_filtered.shape
我們得到的輸出為: (36683, 27)
也就是說總共有 36683 筆數據,共有 27 個欄位,因此有超過 50 筆📂。在圖表中往 Yes 的路徑走。
cleaning_data['Test Results'].unique()
輸出結果: array(['Normal', 'Abnormal'], dtype=object)
我們得到的輸出是 Abnormal/ Normal 是屬於類別,並非數值。在圖表中往 Yes 的路徑走。
我們收案時的資料庫是有 Test Results 這個欄位的,我們不是只要分群而已,而是期望輸出可以給明確的 Abnormal 或 Normal。在圖表中往 Yes 的路徑走。
此時此刻,我們就可以很明確看到一個大框,我們的題目任務是 Classification 分類。 [圖中呈現粉紅色]
由於在第一步驟中我們看到是 36683,因此在圖表中往 Yes 的路徑走。
現在,我們終於可以進入演算法推薦的階段📑。根據圖表,第一個要嘗試的演算法是 Linear SVC。如果訓練結果不理想,我們還可以考慮預測的輸出類型。如果預測的輸出是文本資料,例如履歷中的字詞,則需要用貝氏統計相關演算法,這是因為文本中的每一個字之間都可能存在相關性。這些模型會根據字與字之間的機率來判斷是否將它們放在一起,這和最近流行的生成式 AI 概念類似。不過,回到我們的主題,我們的預測輸出是簡單的類別(Abnormal 或 Normal),這並不屬於文本數據,因此在圖表中我們選擇 No 的路徑。
如果 Linear SVC 的訓練結果不佳,我們可以接著試試 KNeighbors Classifier。如果仍然不理想,那就可以考慮 SVC 或各種 Ensemble Classifiers。
總結一下,我們可以嘗試的演算法包括:
除了以上提到的演算法,還有一些常見的非 Ensemble Classifiers 的方法可以多方嘗試,如簡單有效的二分類方法:Logistic Regression (邏輯回歸)。
這一階段的目的是幫助我們選擇合適的演算法。下一篇文章中,我們將實際進行演算法的建立,讓模型能夠真正運作。🚀

[圖片生成示意:DALL-E]
參考資料:
https://scikit-learn.org/stable/machine_learning_map.html

