在前一篇文章中,我們對多種機器學習分類演算法進行了評估,發現 Random Forest 🌲模型在準確度、精確率和 F1 Score 🎯等指標上表現最佳。這篇文章將深入探討如何基於 Random Forest 模型進行優化,以提高其在醫療數據分析中的預測能力。優化的核心是平衡泛化誤差與模型複雜度,以最大化模型的準確性。泛化誤差反映了模型在未知數據上的表現,而模型複雜度則關係到模型的靈活性和過擬合風險。
在進行 🌲Random Forest 的參數調整時,以下是一些常見的參數及其含義:
1️⃣ n_estimators:控制隨機森林中樹的數量(即子樹數量🌲)。通常,增加樹的數量可以提高模型的穩定性和準確性,但過多的樹可能會導致訓練時間過長⏳,且在某個點後,增加樹的數量對模型性能的提升有限。
2️⃣ max_depth:限制每棵樹的最大深度。這個參數有助於控制模型的複雜性⚙️,從而降低過擬合的風險📉。若深度過小,模型可能擬合不足;若深度過大,則可能導致過擬合。常用的深度選擇包括 3、5 或 7。
3️⃣ max_features:每次分裂時考慮的特徵數量📑。這個參數決定了每棵決策樹在進行分裂時所能選擇的特徵數,適當的特徵數量可以提升模型性能🔧,並增加模型的多樣性。
⚠️需要注意的是在一定範圍內,子樹數量越多🌲,模型效果越好。但當子樹數量越來越大,準確率會發生波動📉📈。因此找到適當的平衡點非常重要⚖️。
學習曲線可以幫助我們了解模型在不同樣本數量下的表現,從而判斷模型是否存在過擬合或欠擬合的問題⚠️。在這裡,我們將通過調整 n_estimators 的範圍,繪製學習曲線,以找到最佳的子樹數量,從而最大化模型的性能。在初始階段,我們會擴大數據範圍🌍,觀察模型在不同 n_estimators 值下的表現,當準確率開始穩定並出現輕微波動時,便可縮小參數範圍🔍,進一步尋找最佳子樹數量。在模型評估過程中,我們的目標是優化 Random Forest 的性能,而使用交叉驗證可以確保評估結果的穩定性和可靠性,雖然這個過程可能會導致準確度的輕微變化,但它有助於我們更全面地理解模型的表現💡。程式碼如下:
from sklearn.model_selection import cross_val_score, cross_val_predict
score_lt = []
for i in range(0,500,10):
rfc = RandomForestClassifier(n_estimators=i+1
,random_state=42)
score = cross_val_score(rfc, X_train, y_train, cv=5).mean()
score_lt.append(score)
score_max = max(score_lt)
print('highest_score:{}'.format(score_max),
'subtree_num:{}'.format(score_lt.index(score_max)*10+1))
x = np.arange(1,501,10)
plt.subplot(111)
plt.plot(x, score_lt, 'r-')
plt.show()
得到的輸出如下: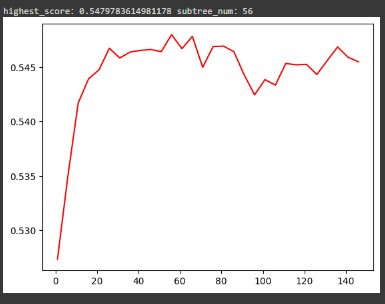
可以看到線圖在 60 個子樹以內有慢慢趨緩平滑的趨勢,後面都是一些波動且目前看起來是子樹設定在 56 時,準確度最高,達到 54.7978%。因此可以在找到平滑的範圍後,我們嘗試縮小範圍,並在小範圍內一個一個點去找到準確度最高點的位置和數值。程式碼如下:
# 缩小n_estimators的範圍從 10-60
score_lt = []
for i in range(10,60):
rfc = RandomForestClassifier(n_estimators=i
,random_state=42)
score = cross_val_score(rfc, X_train, y_train, cv=5).mean()
score_lt.append(score)
score_max = max(score_lt)
print('highest_score:{}'.format(score_max),
'subtree_num:{}'.format(score_lt.index(score_max)+10))
# 繪製學習曲線
x = np.arange(10,60)
plt.subplot(111)
plt.plot(x, score_lt,'o-')
plt.show()
得到的結果如下圖: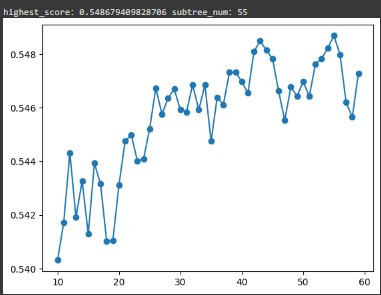
可以看到我們的 n_estimators 一個一個點去找時,已經不是找到 56,而是在子樹為 55 時,準確度提升到了54.8679%,這就是微調的用處 💡。
找到最佳子樹數量後,我們可以用 Grid Search 方法來調整 max_depth 和 max_features。通常會基於已找到的最佳 n_estimators,再進一步微調其他超參數。
此步驟基於找到的 n_estimators=55 去搜尋最佳的 max_depth。程式碼如下:
from sklearn.model_selection import GridSearchCV
rfc = RandomForestClassifier(n_estimators=55, random_state=42)
param_grid = {'max_depth':np.arange(1,20)}
GS = GridSearchCV(rfc, param_grid, cv=5)
GS.fit(X_train, y_train)
best_param = GS.best_params_
best_score = GS.best_score_
print(best_param, best_score)
輸出結果為:{'max_depth': 18} 0.5472002050554043
結果顯示最佳深度為 18,準確度為 54.72%。與之前僅調整 n_estimators 時的準確度相比,雖然看起來有些波動,但差異並不大。因此,可以先保留這個超參數,繼續進行下一步的 max_features 優化。
此步驟基於找到的 n_estimators = 55 、max_depth = 18 去尋找最佳 max_features。程式碼如下:
# 用grid_search 調整 max_features
param_grid = {'max_features':np.arange(5,35)}
rfc = RandomForestClassifier(n_estimators=55, random_state=42
,max_depth=18)
GS = GridSearchCV(rfc, param_grid, cv=5)
GS.fit(X_train, y_train)
best_param = GS.best_params_
best_score = GS.best_score_
print(best_param, best_score)
通常情況下,若未特別設定 max_features,其預設值為總特徵數量的平方根。但建議大家可以多方嘗試不同組合。此程式碼得到的輸出結果為:{'max_features': 20} 0.552184825900075
結果顯示最佳 max_features 為 20,準確度提升至 55.21%📈。這意味著在每次決策樹的分裂過程中,考慮 20 個特徵能夠達到最佳效果,這不僅提高了模型的準確度,也代表了特徵的選擇對於隨機森林模型的性能影響是顯著的🚀。
在模型優化階段,需要不斷測試不同的參數組合。有時候,調整後的結果反而會更差,這可能意味著當前的參數組合不適合,或者模型過於複雜⚠️;但如果僅有輕微的落差,則不必過於擔心,因為這對整體性能影響不大。因此,對於不理想的調整結果,可以選擇不進行調整。最終在完成所有參數調整後,我們便可使用這個調整後的模型進行測試並保存🔍。
在完成所有參數調整後,我們發現在這個隨機森林模型中,n_estimators=55, max_depth=18, max_features=20 時結果最佳🌟。經過微調後,我們需要進行最終的模型測試。以下程式碼呈現如何使用 KFold 交叉驗證來評估模型性能,包括計算常見的醫療指標 (計算準確度、靈敏度、特異性、PPV、NPV、正負似然比(LR+ 和 LR-)等性能指標,以及 ROC AUC 🩺指標。) 這些指標提供了全面的性能評估,幫助我們確定模型的效能✔️:
from sklearn.model_selection import KFold
from sklearn.metrics import roc_auc_score
X = cleaning_data_filtered.drop('Test Results', axis=1) # Since we are predicting Type: Normal/Abnormal, those are the output
y = cleaning_data_filtered['Test Results'] # output is the label
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
rf = RandomForestClassifier(n_estimators=55, max_depth=18, max_features=20
)
kfold = KFold(n_splits=5, random_state=42, shuffle=True)
cm_holder = []
for train_index, valid_index in kfold.split(X_train):
train_x, X_valid = X_train.iloc[train_index].values, X_train.iloc[valid_index]
train_y, y_valid = y_train.iloc[train_index].values, y_train.iloc[valid_index]
rf.fit(train_x, train_y)
cm_holder.append(confusion_matrix(y_valid, rf.predict(X_valid.values)))
print("Confusion matrix: ", cm_holder)
accuracy = []
Sen = []
Spe = []
ppv = []
npv = []
LR_Pos = []
LR_Neg = []
for cm in cm_holder:
TN = cm[0][0]
FN = cm[1][0]
TP = cm[1][1]
FP = cm[0][1]
PPV = TP/(TP+FP)
NPV = TN/(TN+FN)
Sensitivity = TP/(TP+FN)
Specificity = TN/(TN+FP)
ACC = (TP+TN)/(TP+FP+FN+TN)
FPR = FP/(FP+TN)
TPR = TP/(TP+FN)
TNR = TN/(TN+FP)
FNR = FN/(FN+TP)
LR_pos = TPR/FPR
LR_neg = FNR/TNR
accuracy.append(ACC)
Sen.append(Sensitivity)
Spe.append(Specificity)
ppv.append(PPV)
npv.append(NPV)
LR_Pos.append(LR_pos)
LR_Neg.append(LR_neg)
print("mean_acc: ", np.mean(accuracy))
print("mean_sen: ", np.mean(Sen))
print("mean_spe: ", np.mean(Spe))
print("mean_ppv: ", np.mean(ppv))
print("mean_npv: ", np.mean(npv))
print("mean_LR+: ", np.mean(LR_Pos))
print("mean_LR-: ", np.mean(LR_Neg))
roc_auc = roc_auc_score(y_valid, rf.predict(X_valid.values))
auc_score = cross_val_score(rf, X_valid, y_valid, scoring='roc_auc')
print("AUC", auc_score.mean())
我們可以得到結果如下圖: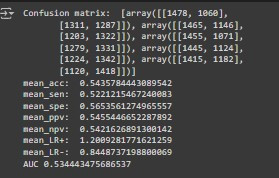
我們使用 5 折交叉驗證,最終測試結果的平均值顯示,平均準確度達到 54.36%,平均靈敏度為 52.21%,平均特異度為 56.54% 等。
這些結果仍需詢問專業人士(例如醫療人員)🤝,以確定這樣的準確度是否可以接受。如果認為這些結果不可接受或低於預期,我們將需要嘗試更進階的演算法🔍、調整超參數或其他參數,甚至返回數據前處理步驟進行修正。不過,這系列文章的主要目的是向讀者介紹機器學習的流程及其應用實作📚,而並非追求特定水準的預測準確度。因此,我們這系列文章將不再進行持續優化,而是進入後續步驟🔄,保存已優化的模型並開始進行預測。這樣的做法不僅能幫助讀者了解如何在實際應用中使用這些模型,還能展示它們的實用性💡。如果有興趣的讀者,可以自行嘗試模型的建立與優化,以進一步提升結果的準確度,深入了解機器學習的過程與技術喔~✨
完成這些測試後,我們可以選擇將最佳模型保存,以便在未來使用新的數據進行預測:
import pickle
from google.colab import files
# 假設 'best_model' 是我們找到的最佳 Random Forest 模型
best_model = rf # 這裡填入您的最佳模型程式碼
# 將模型保存為 Pickle 檔
with open('best_random_forest_model.pkl', 'wb') as file:
pickle.dump(best_model, file)
# 顯示成功訊息
print("模型已成功保存為 best_random_forest_model.pkl")
# 下載文件到本地
files.download(filename)
本文深入探討了如何優化 Random Forest 模型以提高醫療數據分析中的預測能力。我們評估了多個超參數,發現 n_estimators、max_depth 和 max_features 是關鍵因素。在調整過程中,我們通過學習曲線找到最佳的子樹數量,並使用 Grid Search 確定最佳的樹深度和特徵數量。最終,模型的準確度和其他性能指標得到了顯著提升。這一過程展示了在醫療領域中,合理的超參數調整能顯著增強模型的預測效能,為未來的醫療數據分析提供了有力支持。

