在上篇文章中,我們探討了如何根據 scikit-learn 的 cheatsheet 選擇合適的演算法及常見的演算法選擇,但光有理論上的選擇還不夠,我們還需要將這些演算法實際應用於數據上,進行模型的訓練和評估。這篇文章將實作這些演算法,並對不同模型的性能進行比較,從而選擇出最佳的解決方案。
沿用前幾篇的程式碼後,我們已經做好數據清理和特徵工程部分,接下來就是模型的建立。我們將根據上篇文章選擇的幾個演算法來建立模型。模型的建立就短短三行可以搞定。難的地方還是在如何選擇並花時間嘗試找到最好的演算法。程式碼如下:
from sklearn.svm import LinearSVC
# 建立 Linear SVC 模型
linear_svc = LinearSVC()
linear_svc.fit(X_train, y_train)
from sklearn.svm import SVC
# 建立 SVC 模型
svc = SVC()
svc.fit(X_train, y_train)
from sklearn.neighbors import KNeighborsClassifier
# 建立 KNeighbors Classifier 模型
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
from sklearn.ensemble import RandomForestClassifier
# 建立 Random Forest 模型
random_forest = RandomForestClassifier()
random_forest.fit(X_train, y_train)
from sklearn.ensemble import GradientBoostingClassifier
# 建立 Gradient Boosting 模型
gradient_boosting = GradientBoostingClassifier()
gradient_boosting.fit(X_train, y_train)
from sklearn.linear_model import LogisticRegression
# 建立 Logistic Regression 模型
logistic_regression = LogisticRegression()
logistic_regression.fit(X_train, y_train)
在完成模型的建立後,我們需要對不同模型的性能進行評估。透過這個步驟,我們能夠了解哪些模型最適合我們的數據集,以及它們在預測任務中的表現如何。由於我們的問題任務是分類,因此將使用準確度、精確率、召回率、F1 Score 和混淆矩陣等指標來進行評估。此外,Sensitivity(靈敏度)和 Specificity(特異性)指標對於醫療工作者來說至關重要,因為他們通常需要準確了解模型在不同情況下的表現,以便做出合理的臨床決策,以滿足醫療領域的預測需求。程式碼如下:
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
models = {
"Linear SVC": linear_svc,
"KNeighbors Classifier": knn,
"SVC": svc,
"Random Forest": random_forest,
"Gradient Boosting": gradient_boosting,
"Logistic Regression": logistic_regression
}
for name, model in models.items():
y_pred = model.predict(X_test)
# 計算混淆矩陣
conf_matrix = confusion_matrix(y_test, y_pred)
tn, fp, fn, tp = conf_matrix.ravel()
# 計算主要指標
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='binary')
recall = recall_score(y_test, y_pred, average='binary') # 靈敏度 (Sensitivity)
f1 = f1_score(y_test, y_pred, average='binary')
specificity = tn / (tn + fp) if (tn + fp) > 0 else 0.0 # 特異度 (Specificity)
# 結果輸出
print(f"{name} 的模型評估:")
print(f"準確度: {accuracy:.4f}")
print(f"精確率: {precision:.4f}")
print(f"召回率 (Sensitivity): {recall:.4f}")
print(f"F1 Score: {f1:.4f}")
print(f"Specificity: {specificity:.4f}")
print(f"混淆矩陣: \n{conf_matrix}\n")
print("-" * 50)
在我們的模型評估中,五種不同的分類器表現各異。以下是每個模型的關鍵指標輸出結果: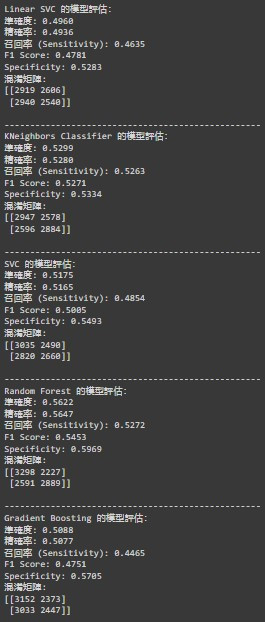
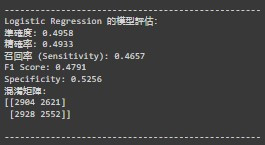
從以上結果可以看出,各模型的表現有明顯差異。Random Forest 模型整體表現最佳,具備最高的準確度(0.5622 = 56.22%)、精確率(0.5647 = 56.47%)和 F1 Score(0.5453),顯示其在 Normal 和 Abnormal 識別上相對較為平衡。而 KNeighbors Classifier 和 SVC 模型的表現也相對穩定,雖然準確度稍低,但在其他指標上仍然表現可圈可點👍。
然而,Linear SVC、Gradient Boosting 和 Logistic Regression 的結果顯示出模型在敏感性(Sensitivity)和 F1 Score 上的不足,特別是在醫療數據的應用中,這可能會影響實際的臨床決策。這意味著我們的模型尚未能夠有效區分疾病狀態,尤其是對於陽性樣本的識別🚨。
在評估模型時,建議與醫療專業人士進行深入討論,了解他們在醫療場景中最看重的指標🩺。
如果專業人士認為模型的結果不可接受,則應回顧前面的數據清理、特徵選擇和模型訓練過程。透過專業人士的意見,我們能夠針對性地調整模型,以更好地滿足實際需求🎯。
如果模型結果不如預期,我們可以考慮以下幾個方向進行改進:
1️⃣ 數據品質檢查:確保訓練數據集的品質,檢查是否存在缺失值、不平衡問題或不正確的標籤等,這些問題都會影響模型的表現。
2️⃣ 特徵工程:重新檢視特徵選擇和特徵處理過程,確保選擇的特徵對預測有實質貢獻。
3️⃣ 模型調整:考慮使用更複雜的模型或調整現有模型的參數,以提升性能。
4️⃣ 交叉驗證:使用交叉驗證來更好地評估模型的穩定性和泛化能力。
透過以上步驟,我們可以進一步提升模型的預測能力,應對醫療數據分析中的挑戰,並提供更具信賴性的預測結果。
在本篇文章中,我們針對多種機器學習模型進行了評估,結果顯示不同模型在分類任務中的性能差異明顯。雖然Random Forest 模型表現最佳,具備較高的準確度和精確率,但其他模型在特定情境下仍有其價值。關鍵在於如何利用這些評估結果進行後續的改進。如果專業人士認為某些模型的表現不可接受,則需重新檢視數據前處理、特徵選擇和模型訓練的各個步驟。與醫療專業人士的深入討論對於確保模型符合實際應用需求至關重要。
在下一篇文章中,我們將基於 Random Forest 模型進行進一步的優化,探索如何調整模型參數以提升其預測能力,從而應對醫療數據分析中的挑戰。

