在前幾天瞭解完有關反爬蟲的大致概念,包括IP封鎖、頻繁請求限制後,
我們就要來聊聊要如何「繞過反爬蟲」,換句話說,就是要怎麼樣
才可以讓我們順利的爬蟲,不受到反爬蟲的阻擋。
而我們今天要學習的就是其中一種方法,也就是「設置請求頭模擬瀏覽器行為」,
那它是什麼呢?它又可以為爬蟲發揮什麼功用?
簡單來說,設置請求頭模擬瀏覽器行為就是一個模擬瀏覽器在瀏覽網站的模式。
如果是一般爬蟲程式的話,其實很簡單的就可以被偵測出是機器,
而這時目標網站就因為你的行為,而對你的造訪發出限制,
就像我們前面提到的IP限制跟頻繁請求限制。
如此模擬真人瀏覽網頁的行為,相較於普通爬蟲更不容易被限制。
再白話一點來說,我們的這個動作的目的,就是讓爬蟲這個動作「隱形」。
同時這類型的技巧也被稱為「反反爬蟲」。
那接下來我們就進入到實作的環節,先看看我以下打的範例:
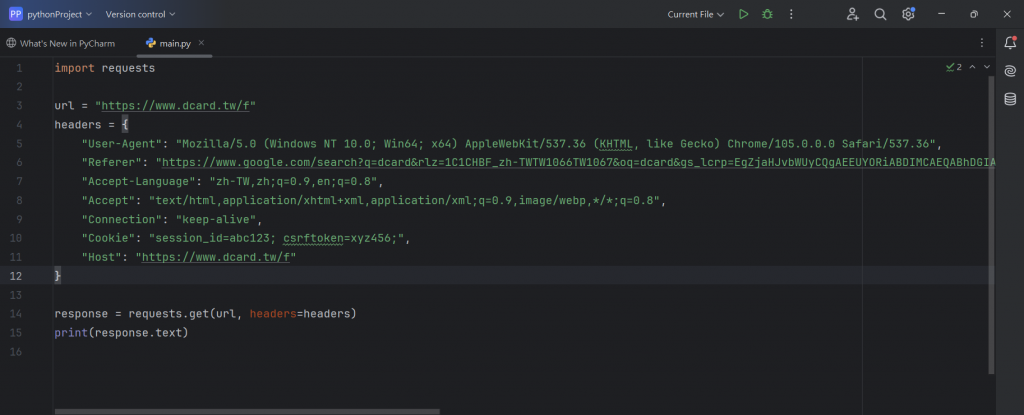
以下我們就來一行一行的做解析:
import requests:
這行是導入Python中的requests庫(沒有的就會進行下載)。
這個庫主要是用來發送HTTP的請求。爬蟲通常會用它來抓取網站內容。
Request就是之前提過的POST、GET等等的,這邊就不多提了。
url = https://www.dcard.tw/f:
這行的用意就是打出我們想要爬取的網址,我這邊是選用Dcard的首頁,
有興趣的可以自己去瀏覽看看。之前也解釋過URL的意思了,
反正簡單理解的話就是網址的意思。
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36":
這行我們之前大概也有提過,主要User-Agent的用意是能讓網站識別出
發出的請求是來自什麼設備上的,而若是發現它的來源是
顯示Python-requests(爬蟲的默認),那網站可能就會拒絕你的請求。
上面一坨拉庫的網址其實就只是google查詢dcard指令所跳出來的網頁。
Referer在這邊的意思是指所想爬取的網頁的「前一個頁面」,
換句話說,就是你是從哪個頁面跳轉過去的。
簡單來說,就是因為模擬真實瀏覽器的瀏覽行為,所以必須檢查此項目,
因為如果是基礎的爬蟲,會是顯示直接訪問的,那就有可能會被擋下來。
"Accept-Language": "zh-TW,zh;q=0.9,en;q=0.8"
在這邊就是進行你想要抓取語言的設定。因為Dcard是繁體中文為主嘛,
所以我這邊所選擇的指令就是zh-TW,意思就是抓取繁體中文,
也是在告訴網站你比較希望以什麼方式來顯示內容。
而後方的q則是權重的意思,表示程度,q的數字越高,
代表優先級越高(最高1,最低0)。
(若是你想要抓取的是英文,指令就是en-US,
參考的資料我會放在最下面,有興趣的讀者可以自行去參閱。)
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8":
Accept標頭主要是在告訴網站我所能處理的回應類型。
這裡表示瀏覽器期望的主要內容格式是HTML(text/html),其次是XHTML和XML,
然後還能接受圖片格式,例如像WebP和其他任意格式(/)。
這可以使得請求看起來更加像是來自普通瀏覽器的請求。
"Connection": "keep-alive”:
keep-alive是表示瀏覽器希望在一段時間內保持與伺服器的連接,
而不是在每個請求後關閉連接。
若是在每次請求後關閉,我們就必須重複輸入指令,就會大大的降低我們的效率。
在先進的瀏覽器中,大多都會使用這個類型指令。
"Cookie": "session_id=abc123; csrftoken=xyz456;":
Cookie裡面會包含瀏覽器對話中的一些狀態信息資料,
例如像是用戶的會話ID。這些是網站用來追蹤用戶、
保持登錄狀態或保證請求合法性的數據。
那要從哪裡獲取這些訊息呢?我們可以到目標的網頁,並按下F12,我們就可以得到下面的畫面:
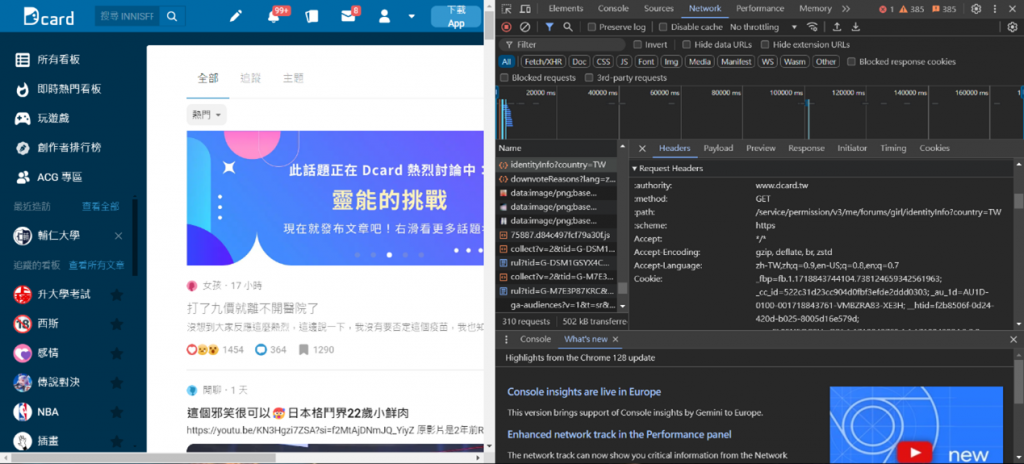
右邊所顯示的就是google的專屬開發者工具- Chrome DevTools,
在裡面,你就可以看到該網頁所構成的全部內容,例如像原始的HTML程式碼,
網路波動,以及cookies所存取的數據:
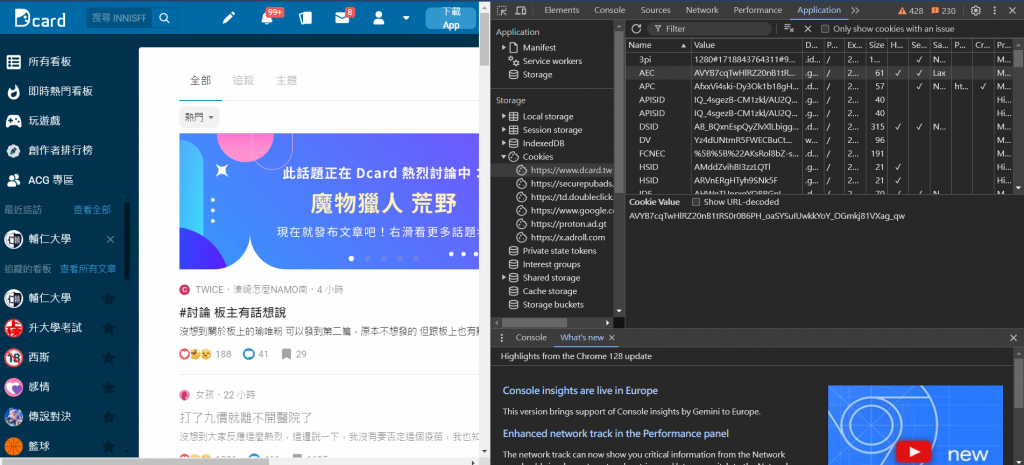
我們在上方找到Application並點選,就可以在左邊看到Cookies的選項,
裡面就有許多網站的資料,像是安全性識別碼 (SID)、整合開發環境(IDE)等。
這樣可以通過開發者工具查看瀏覽器發送的Cookie並複製到爬蟲裡,
就能夠幫助模擬已登錄的用戶行為。
那為什麼我這邊沒有打出實際的Cookies內容呢?因為我在裡面找了
好久都沒有找到相關所需的內容(也可能是因為找的檔案類型或檔名不一樣),
但因為每日的學習時間也有限,我就想將這個部分先稍微帶過去,等到之後的實作再一併處理。
"Host": https://www.dcard.tw/f:
Host就是幫我們指定當前所請求的目標網站域名。
當你同時向多個域名發送請求時,它就用來告訴伺服器這個請求是針對哪個域名的。
而在單一請求中,這邊應該會跟上面的URL一樣。
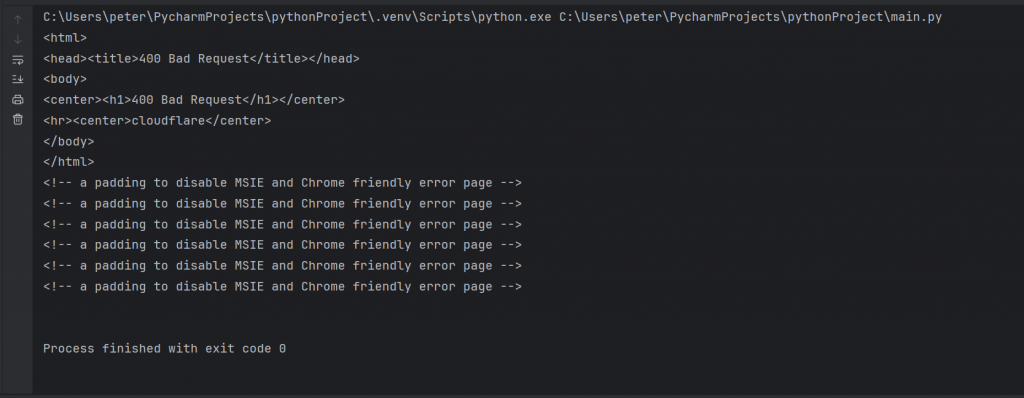
response = requests.get(url, headers=headers)
print(response.text):
最後,就是對指定的url發送GET請求,並將我們所自定義的headers
作為參數發送給伺服器。這樣爬蟲的請求就會模擬一個瀏覽器發出的請求。
但因為我們沒有完成所有的步驟,所以理所當然的,回應顯示了錯誤。
小結:
在今天,我學習了第一個爬蟲方法-設置請求頭模擬瀏覽器行為,
雖然過程非常不順利,也沒有達到我想達成的目標,但我還是有在過程中學習到很多,
像是Cookie的檔案內容、開發者工具的詳細使用、以及爬蟲的知識等等,
這些內容都令我收穫很多,感覺又學習到了一些會讓自己進步的東西。
參考資料:
https://hackmd.io/@AndyChiang/DynamicCrawler
https://www.kaspersky.com.tw/resource-center/definitions/cookies
https://learn.microsoft.com/zh-tw/windows-server/identity/ad-ds/manage/understand-security-identifiers
https://medium.com/@kaojia/%E8%B3%87%E6%96%99%E5%88%86%E6%9E%90-python%E7%88%AC%E8%9F%B2%E5%85%A5%E9%96%80%E5%AF%A6%E4%BD%9C-%E4%B8%8B-%E5%8B%95%E6%85%8B%E7%B6%B2%E9%A0%81%E7%88%AC%E8%9F%B2-%E5%8F%8D%E5%8F%8D%E7%88%AC%E8%9F%B2-json-%E6%A0%BC%E5%BC%8F-2170c88b0ec8
https://hoohoo.top/blog/national-language-code-table-zh-tw-zh-cn-en-us-json-format/
https://steam.oxxostudio.tw/category/python/spider/crack-spider.html