前面有提到過,若是你大量使用同一個IP來進行爬蟲,
可能會導致目標發現你是在使用特定程式進行爬取,
那如此就可能會被封鎖,就像我們前幾天提過的IP封鎖,
會禁止你使用這個IP再次對網站來進行訪問。
那我們在前幾天也有說過了,我們可以透過模擬真實瀏覽器,
也就是設置請求頭模擬瀏覽器行為來避開目標網頁對於爬蟲的偵測。
那除了該方法,還有其他方式可以避開網頁的反爬蟲嗎?
答案當然是有的,我們今天就要介紹另外一個隱藏自己爬蟲行為的方式-代理IP
那到底什麼是代理IP呢?其實顧名思義,就是隱藏自己原本發出的原IP,
改成使用不同的代替IP地址來發出給目標網頁,
讓網頁不會因為是同個IP所發出大量請求而屏蔽掉你的爬蟲造訪
(像是我們前面說過的頻繁請求限制),進而達成爬蟲的爬取目標。
那要怎麼使用代理IP呢?一般來說有兩種方法,
分別為較適合初學者使用的request 要求,
以及較專業的scrapy爬蟲框架,
而以下我們都會對他們做一個初步的講解。
這是我們之前就使用過的python功能,主要是用來發送所有HTTP的請求,
像是GET、POST、PUT等方法。
那在Python中,我們只要輸入以下指令,就可以正常使用request的功能了。
透過import的加入指令,我們就可以使用requests套件了。

那以下就是使用Request處理代理IP的例子:
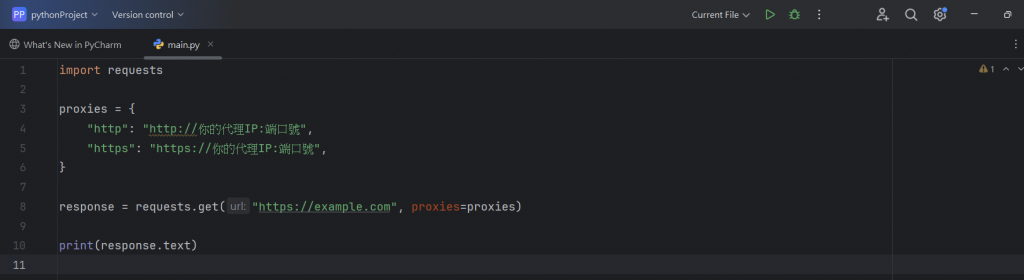
下面我就來分別一行一行的解釋他們的功用及目的:
proxies = {
"http": "http://你的代理IP:端口號",
"https": "https://你的代理IP:端口號",
}:
這邊我們先從上面的proxies開始講起,
這個單字翻譯成中文就是「代理商」的意思,
那在這邊就是指一個「代理」的概念。
proxies 在這裡是指 代理伺服器(proxy servers) 的一個設置,
也可以把它當作一個字典,
而功用就是用來指定 HTTP 和 HTTPS 請求使用的代理 IP 地址和端口。
代理伺服器作為用戶和目標伺服器之間的中介,當你通過代理發送請求時,
請求首先會經過代理伺服器,然後代理伺服器再將請求轉發到目標伺服器。
這樣目標伺服器收到的請求看起來是來自代理伺服器的,而不是直接來自你的電腦。
舉一個大家一定耳熟能詳的名詞-翻牆,
其實就是由代理伺服器所進行的一個經典案例,當某個國家封鎖了某個網站時,
它通常是根據該處的IP地址來進行封鎖的,
因此,像我們舉例的翻牆,或者是最近突然開始盛行的VPN,
其實都是依照這個概念下去運作的。
而上面的另外一行"http": http://你的代理IP:端口號”,就是指指定HTTP使用的代理IP(同理HTTPS那行也一樣)。那我們要去哪裡獲得這些代理IP呢?
其實只要在網路上進行搜尋,就可以找到許多可以利用的資源,
例如我所發現可以使用的網站就有Free Proxy List (免費),以及Smartproxy、Oxylabs(付費)等網站可以為使用者提供代理IP的服務。
為上述提到的Free Proxy List以及Smartproxy
也當然,每一個網站都有他們不同的地方,
使用者可以依據各自的需求去選擇想使用的網站。
response = requests.get("https://example.com", proxies=proxies)
print(response.text):
而在最後一行的這個部分,如果有看我前幾天的程式碼撰寫,
應該就不會太陌生了。這邊主要就是使用了我們前面導入的requests套件
發出了一個GET請求,並使用已經定義好的代理IP去做訪問。
而要特別注意的是,後面的https://example.com是指目標網站的URL,要記得別搞錯了。
最後,就是印出所爬取到的文本(text)資料,這邊通常會是目標網站的HTML純文字資料。
除了上述簡單的爬取,其實還可以增加其他新的功能,
讓爬蟲變得更不容易被抓取:例如像是新增random套件以用來生成隨機數,
並用它來隨機選擇代理 IP 和設置隨機的請求間隔。
或者是使用time套件,來對發送IP的時間進行間隔延遲。
不過今天我只想要先陳述大概念,這些細項會等到之後的實作再一併加入,
這邊只是先讓讀者參閱一下,知道說還有這些內容可以新增。
今天詳細對於代理IP進行了一次學習,讓我又對於爬蟲的技巧知識了解了更多。
我希望可以趕快進行到實作的部分,如此我才可以真的實際的去
爬取我想要網站的資料,但也因為應該要先打好相關的基礎,
所以這些基本概念的學習還是不可少的。
參考資料:
https://zh.wikipedia.org/zh-tw/%E4%BB%A3%E7%90%86%E6%9C%8D%E5%8A%A1%E5%99%A8
https://utrustcorp.com/python-requests/
https://medium.com/@hightowerburtonc/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8curl%E8%A8%AD%E7%BD%AE%E4%BB%A3%E7%90%86ip%E9%80%B2%E8%A1%8C%E7%B6%B2%E8%B7%AF%E7%88%AC%E8%9F%B2-okey-proxy-14a8e2371845
https://medium.com/@hightowerburtonc/python%E7%88%AC%E8%9F%B2%E4%BB%A3%E7%90%86ip%E6%B1%A0%E7%9A%84%E6%A7%8B%E5%BB%BA-okey-proxy-35d7825c6ad5

