
大家應該都很習慣跟LLM聊天時,輸入文字然後 LLM 就會輸出文字的這個 text2(to)text 的過程。今天要教大家怎麼操作向量空間中的 embedding,嘗試直接輸入一個連續向量,然後對這個 embedding 做加減乘除平移轉換等操作,最後解碼這個客製化 embedding 得到你想要的文字 ,一起體驗一個 vector2text 的過程:)
昨天文章的結尾有邀請大家針對初步的解題思路,想想看可能會遇上什麼問題,今天我們繼續討論一些實行上的困難以及可能的解決思路:
問題 1:合成數據集中的重寫提示有時不合適
問題 2:配置模型生成重寫文本的難度
問題 3:生成的重寫文本品質有時不理想
問題 4:預測合成重寫提示可能會出現偏差
問題 5:評估嵌入空間與訓練嵌入空間不同
問題描述:
模型在訓練過程中的嵌入空間與最終評估使用的T5嵌入空間可能有所不同,導致相似度評估存在偏差。
可能解決方案:
參賽者目前仍在探索解決方案,可能需要使用強化學習或在微調小型模型時加入額外損失函數來解決這個問題。
問題 6:不確定主辦方的預處理或後處理
問題描述:
不清楚主辦方是否進行了額外的數據處理,例如刪除前綴語句、特殊字符或截短文本,這些都可能影響生成結果。
可能解決方案:
通過探測測試集,嘗試確認主辦方是否對數據進行了這些處理,並根據結果調整生成策略。
從上面這些挑戰看得出來,因為這場比賽缺乏訓練資料,從生成資料到評估結果都有太多不確定性,所以在很多人嘗試從各種資料來源,用人工或是LLM生成 dataset,再用各式各樣的開源 LLM 訓練來預測 rewrite prompt之後,發現效果都不好,而且很難確定到底是哪個環節出問題。
於是有人提出 Mean Prompt 的概念!
所謂的 Mean Prompt 就是不管輸入的 origin text 和 rewrite text 是什麼,我統一都給出一模一樣的 rewrite prompt 當作答案!
原因是根據不同的輸入(origin_text, rewrite_text)要相應地預測他們的 rewrite_prompt 太難了,很難把模型訓練得很好,使得模型可以很好地 transfer 到 Host 的 hidden test set上。
那不然我們換一種思路:
既然最後的評估方式是把ground truth prompt 和我們預測出來的 predict prompt 都轉成向量以計算相似度,那我們不如找出一個prompt,他在向量空間中會介在所有 prompt 的中心。
也就是說這個 prompt 的向量距離所有 ground truth prompt 的向量都不會太遠,這樣即便每一題我們都寫同樣的 prompt,因為是所有prompt的中心點,所以成績也不會太差。
這樣的做法聽起來有點保守,但卻幾乎是所有得獎團隊都採取的作法。
我們可以用下圖來解釋:
在不知主辦方 test data 底細的情況下,大家訓練出來的 LLM 在預測 prompt 都表現得滿爛的,與其讓一個不確定很高的 LLM 幫每一題都預測一個特製的 prompt(圖上的黃點) ,卻不一定貼近 ground truth(藍點),還不如就找到 ground truth prompt 的中心點(紅點),這樣在向量空間中計算的距離整體來看還比較近,我們找到後再嘗試把這個紅點向量解碼成文字輸出即可。
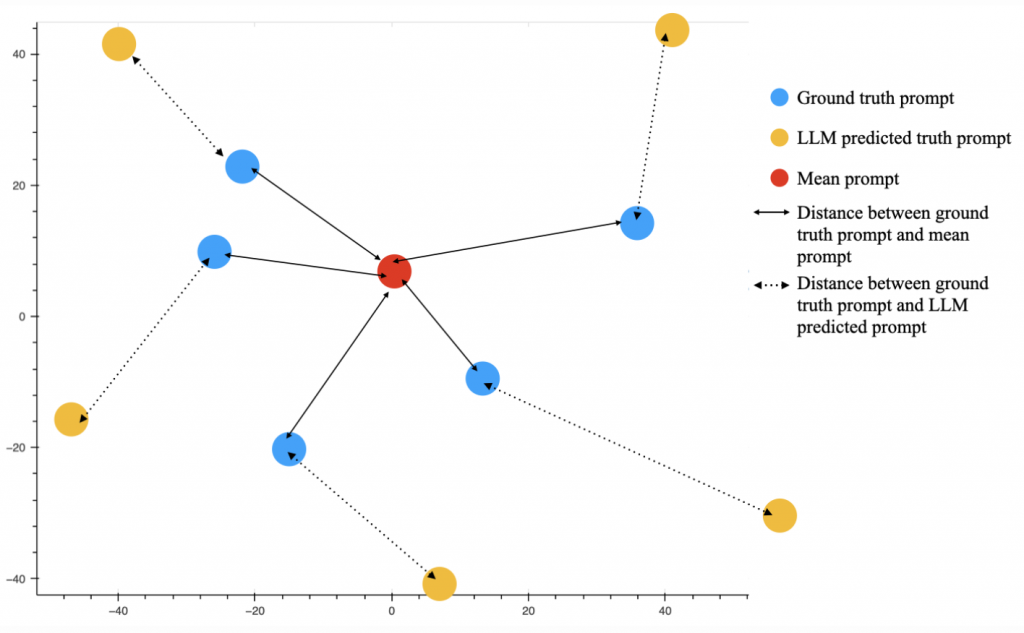
也許可以更簡單粗暴地理解為,因為大家這題都做得不太好,接近盲猜,就像是以前我們唸書裸考的時候,與其每一題自作聰明四個選項努力猜一個,還不如兩眼一閉全部猜 C ,分數可能還比較好看。
但是要找到這個 Mean Prompt 也不是件容易的事情(畢竟我們看不到 test data 的正解 prompt),這其中也是有很多技巧可以挖掘的呦!
我很喜歡第七名的解法,思路清晰且有效,我們一起來欣賞看看~
作者的解法主要分為四個主要部分:
1. 不斷迭代 mean prompt 以優化這個 prompt
2. 訓練兩個大型語言模型(LLM)根據輸入預測可能的 rewrite prompt
3. 在 T5 嵌入空間中尋找最佳點
4. 解碼該點為字符串。
所以有別於努力找到一個 mean prompt 之後每一題都回答一樣,作者會在第一步找到的 mean prompt 的基礎上,再根據每一題的輸入(origin_text, rewrite_text) 進行微調!
如果使用上面的圖來解釋的話,他的想法就是先找到一個 mean_prompt(紅點),然後再根據每一題不同的輸入,想辦法調整這個mean prompt 的 embedding(紅點)靠近該題 ground truth 所在的位置(藍點)。 (可以參考文章末尾小結部分的說明圖)
聰明的想法!
以下代碼為我重構作者的 inference code,以幫助大家更清楚地理解他的思路,原始版本請參考:1
Step I. 迭代優化 Mean Prompt - Iterative Mean Prompt Optimization(離線進行)
這部分是作者利用有限的提交次數,不斷嘗試找到一個還不錯的 mean prompt ,留待之後以它為起點繼續修正。
他的步驟如下:
以下是實現的代碼:
# Initialize the best string and its embedding
best_str = "Improve this text"
best_embedding = t5_model.encode(best_str, convert_to_tensor=True)
best_score = LB Score
print(f"Initial string: '{best_str}'")
print(f"Initial cosine similarity to mean_t: {best_score:.4f}")
# Define token modification functions
def delete_token(tokens):
if len(tokens) > 0:
idx = random.randint(0, len(tokens) - 1)
del tokens[idx]
return tokens
def insert_token(tokens, vocab):
idx = random.randint(0, len(tokens))
new_token = random.choice(vocab)
tokens.insert(idx, new_token)
return tokens
def replace_token(tokens, vocab):
if len(tokens) > 0:
idx = random.randint(0, len(tokens) - 1)
new_token = random.choice(vocab)
tokens[idx] = new_token
return tokens
# Prepare the vocabulary (a list of token IDs)
vocab = list(tokenizer.get_vocab().values())
# Iterative optimization
num_iterations = 1000 # Adjust as needed
operation = random.choice(['delete', 'insert', 'replace'])
for iteration in range(num_iterations):
# Choose a random operation: delete, insert, or replace
# Tokenize the current best string
tokens = tokenizer.encode(best_str, add_special_tokens=False)
# Apply the chosen operation
if operation == 'delete':
new_tokens = delete_token(tokens.copy())
elif operation == 'insert':
new_tokens = insert_token(tokens.copy(), vocab)
elif operation == 'replace':
new_tokens = replace_token(tokens.copy(), vocab)
# Decode the new token sequence to a string
new_str = tokenizer.decode(new_tokens, skip_special_tokens=True)
# Compute the embedding of the new string
new_embedding = t5_model.encode(new_str, convert_to_tensor=True)
# Compute the cosine similarity to mean_t
new_score = util.cos_sim(new_embedding, mean_t).item()
# If the new string has a higher score, update best_str and best_score
if new_score > best_score:
best_str = new_str
best_embedding = new_embedding
best_score = new_score
print(f"Iteration {iteration}: New best string found!")
print(f"Best string: '{best_str}'")
print(f"Cosine similarity to mean_t: {best_score:.4f}")
operation = random.choice(['delete', 'insert', 'replace'])
else:
operation = random.choice(['delete', 'insert', 'replace'].remove(operation))
看起來最終找到的 mean prompt 是這個:
"""bestow Improve the such text out to this and having enhance articleify somehow complete seamless fresh succinpth tone of or interactions please Moditate at any identifiable tone settingh bitte leave PubliORE wordingHU cm would I flair dem revisitlies such originalampevocative and grand spin uninterrupted new desire to have those connected/4 would diary entities sweat of warmth/ sticky accuracy lead useful maudiler q any wisdom to simplify someonerucliv this text' einzu physical by alter THAT tone than words"""
由於是隨機插入、刪除、取代 token,最後產生的結果就看起來像是亂碼一樣。
Step II: 使用兩個 LLM 預測 rewrite prompt - Two LLM Predictions
使用兩個大型語言模型(mistral 和 openchat)生成預測prompt,並將這些預測作為後續優化的基礎。每個模型的預測都會與StepI結合,產生更好的 rewrite prompt。
使用的模型:
Functions:
predict_all(df, model_str_id, prompt_version): 用指定的 LLM model 為當前輸入的 origin_text, rewrite_text 預測可能的 rewrite prompt。
res0 = predict_all(test_df, "mistral", prompt_version="v2")
res1 = predict_all(test_df, "openchat", prompt_version="v0")
Step III: 在 T5 嵌入空間中尋找最佳點 - Finding an Optimal Point in T5-space
前面有提到所有的 ground truth rewrite prompt 和我們產生的 predicted rewrite prompt,都會被 t5-base model 轉成向量後計算 cosine similarity。所以我們現在想要在 T5 model 的 embedding space 中,盡可能找到逼近該題 ground truth 的位置。
他的作法就是利用兩個不同 LLM 預測出該題可能的 rewrite prompt,來指導 mean prompt embedding 之後要修改的方向。
如果兩個 LLM 預測出來的 rewrite prompt 非常相似,那是不是代表兩個相異的 LLM 對這題是有共識的,我們應該比較側重 LLM 生成的 rewrite prompt 而不是前面找到的 mean prompt;相反,如果兩者非常不像的話,代表這題兩個 LLM 的分歧有點大,那還是主要參考 mean prompt 比較保險。
具體的實現方式如下:
計算兩個 string 的 CosineSimilarity
def scs(v, w, dim):
return CosineSimilarity(dim=dim, eps=1e-08)(v, w) ** 3
def alles_auswuchten(predictions):
# Load T5 model and tokenizer
t5 = SentenceTransformer(path_to_sentence_t5, device=device).eval()
tokenizer = AutoTokenizer.from_pretrained(path_to_sentence_t5)
refined_preds = []
for all_preds in predictions:
# Generate variants of the predictions
variants = []
mean_vecs = []
for pred in all_preds:
new_variants = get_variants(pred)
variants.extend(new_variants)
vs = t5.encode(new_variants, convert_to_tensor=True, show_progress_bar=False)
mean_vecs.append(vs.mean(dim=0))
# Calculate agreement
todo_agreement = scs(mean_vecs[0], mean_vecs[1], dim=0).item()
w_pred = compute_weight_based_on_agreement(todo_agreement)
# Proceed to step 4
res = prediction_auswuchten(prefix, prediction, mean_vecs, w_pred, t5, tokenizer)
refined_preds.append(res)
return refined_preds
重點在這一段:
todo_agreement = scs(mean_vecs[0], mean_vecs[1], dim=0).item()
w_pred = compute_weight_based_on_agreement(todo_agreement)
todo_agreement 會計算兩個 LLM 生成的 predicted_rewrite_prompt 之間的相似度,這邊叫做 agreement(共識),然後用下面的 function compute_weight_based_on_agreement,根據 argeement 計算到底要給 LLM predict 出來的rewrite prompt 多少的關注度(weight):
def compute_weight_based_on_agreement(todo_agreement):
"""
Compute the weighting factor based on the agreement between two LLM predictions.
Parameters:
- todo_agreement (float): Sharpened cosine similarity between the embeddings of the two LLM predictions.
Returns:
- w_pred (float): Weighting factor for the LLM predictions, between 0.2 and 0.6.
"""
# Calculate initial weight based on a quadratic function
w_pred = 0.4 * (todo_agreement ** 2) + 0.0 * todo_agreement + 0.2
# Ensure w_pred is at least 0.2
w_pred = max(w_pred, 0.2)
# Ensure w_pred does not exceed 0.6
w_pred = min(w_pred, 0.6)
return w_pred
接下來透過 w_pred,我們就可以組合 mean_prompt 和兩個 LLM 生成的 rewrite prompt 的 t5 embedding,以產生我們的最佳向量。
作者組合的方法如下:
anchor_vecs = (1-w_pred)*mean_prompt_embedding + w_pred / 2 * predict_prompt[0] + w_pred / 2 * predict_prompt1
也就是兩個llm產生的 prompt 平分剛剛算出來的 w_pred,然後 mean_prompt 就乘上剩下的 weight,產生出來的最佳向量連同LLM生成的rewrite prompt 的 embedding,會一起被存入 anchor_vecs 裡面。
Step IV. 解碼最佳向量為字符串 - Decoding the Point to a String
我們現在的目標是解碼上一個步驟找到的「最佳向量」。
但是文字是離散的,向量是連續的,我們要怎麼去解碼向量呢?
我們只能在文字的離散空間中找到一個最優的string,使這個 string 的 t5 embedding 會很逼近我們的最佳向量,這樣我們就可以說這個最佳向量解碼出來的字串就是該個 string。
找到這個字符串string的方法也不難,就是透過不斷修改初始字符串,選擇那些能提高與最佳向量相似度的修改進而優化結果。
首先,我們先提供一個初始的字符串,這邊是直接把 mean_prompt 和 LLM 生成的 rewrite prompt 的其中一個接起來。
best_str = mean_str.strip() + " " + best_pred_str.strip()
best_tokens = tokenizer.encode(best_str, add_special_tokens=False)
接下來主要的邏輯是這邊:
def prediction_auswuchten(mean_str, best_pred_str, anchor_vec, w_pred, t5, tokenizer):
# Initialization
best_str = mean_str.strip() + " " + best_pred_str.strip()
best_tokens = tokenizer.encode(best_str, add_special_tokens=False)
# Iterative Optimization
for epoch in range(num_epochs):
# Generate candidate modifications
cands = []
for _ in range(batch_size):
mod_tokens = apply_random_modification(best_tokens)
mod_str = tokenizer.decode(mod_tokens, skip_special_tokens=True)
cands.append(mod_str)
# Evaluate candidates
mod_vecs = t5.encode(cands, convert_to_tensor=True, show_progress_bar=False).to(device)
scores = calc_score(mod_vecs, anchor_vecs, anchor_weight, dim=1)
# Update best string
if scores.max() > best_score:
sid = scores.argmax().cpu().item()
best_str = cands[sid]
best_tokens = tokenizer.encode(best_str, add_special_tokens=False)
best_score = scores.max()
return best_str
我們來一步一步解釋:
第一步,是生成候選字符串:
apply_random_modification(best_tokens):
這個 function 會隨機修改當前的 best_tokens,可能的操作包括:
第二步,開始評估每個候選tokens:
mod_tokens)用tokenized.decode 將之解碼為字符串(mod_str),存入 mod_vectors 備用mod_str轉成 embedding(mod_vecs)。第三步,開始計算每一個mod_vec和anchor_vecs裡面所有向量的cosine similarity的加權總和。如果某個候選字符串的得分高於當前的 best_score,則更新 best_str 和 best_score。持續 200 個 epochs 後,輸出 bset_str 當作這題的答案。
總結一下,今天介紹的第七名解法,首先藉由暴力搜索試探出 LB 分數較高的 mean prompt 當作起始點,再利用兩個 LLM 達成「共識」的程度,調整 mean prompt 的內容,看要比較靠近 LLM 生成出的東西,還是要堅守本心就用一開始找到的 mean prompt 就好。
以下是圖解,可以幫助大家更容易理解他的作法:
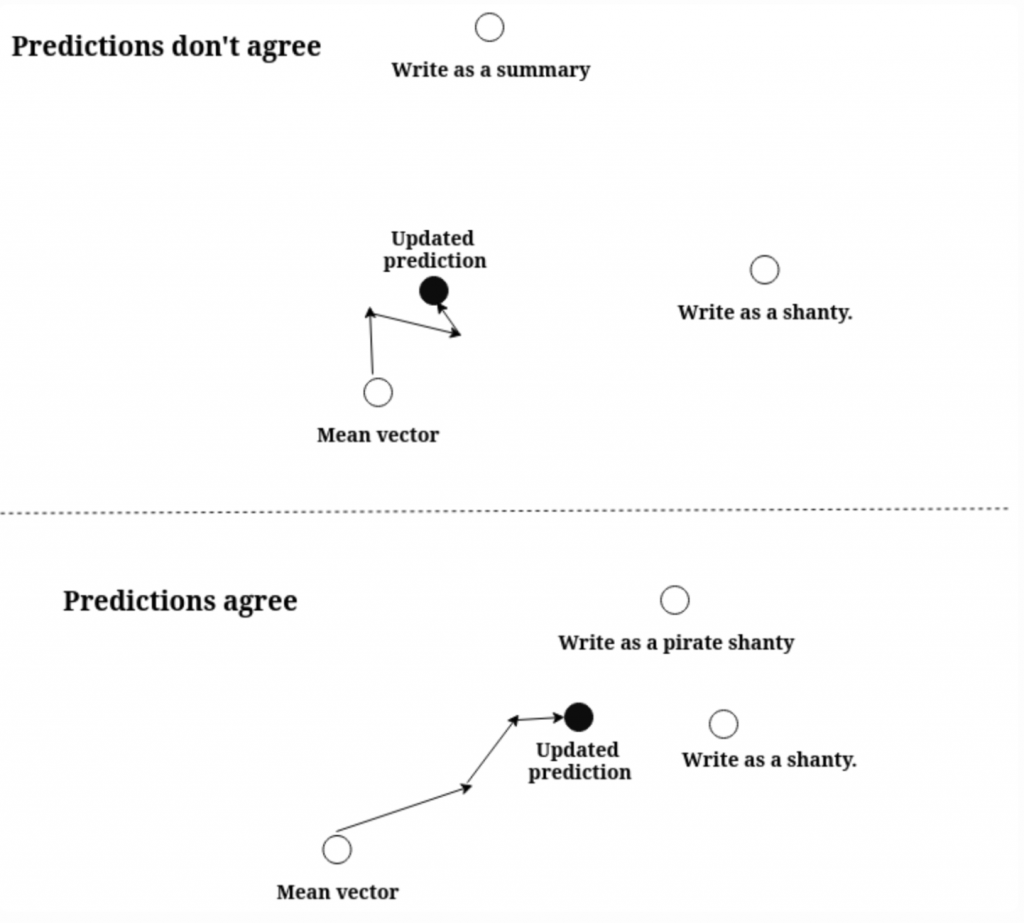
上圖是兩個 LLM 的預測 prompt agreement (相似度很低)的情況,這樣 update 的 prediction 就會比較靠近原始的 mean vector;下面則是 llm 之間達成共識(相似度很低),那 update 的 prediction 就會從 mean prompt 這個原點多走幾步去靠近兩個 llm 的輸出。
沒想到一個解法就寫這麼多...這個比賽比想像中還有趣好玩,我可能擴大研究範圍從前 10 名的解法中收集比較有趣的作法來介紹~
我們明天見!
謝謝讀到最後的你,希望你會覺得有趣!
如果喜歡這系列,別忘了按下訂閱,才不會錯過最新更新,也可以按讚給我鼓勵唷!
如果有任何回饋和建議,歡迎在留言區和我說✨✨
(Kaggle - LLM Prompt Recovery 解法分享系列)

 iThome鐵人賽
iThome鐵人賽