
有時候,大型語言模型(LLM)並不總是按照我們的意願工作。馬上12點快到了,你可能希望chatgpt趕快將一篇你正在寫的鐵人賽文章改寫得生動有趣、增加觸及,但它卻給出了平淡無奇甚至偏離主題的內容;或者你想讓它提升一篇技術文章的品質,但它卻添加了一些無關緊要的信息,讓你感到無奈煩躁。然而,總有一些高手能夠用一些神秘的提示詞(prompt),就像咒術回戰裡的咒言師狗卷一樣,讓這些模型乖乖地按照他們的要求工作。
想象一下,如果你是一名作家,想要將一篇草稿改寫得更加吸引人;或者你是一名編輯,希望快速提升一篇文章的意境。來自谷歌新研發的“Gemma”系列開放模型,它能夠對文本進行重寫,使其煥發出新的光彩。然而,如何有效地引導Gemma,讓它按照人們的意願進行重寫,成了一個亟待解決的謎題。這場比賽就是要找到那個關鍵的提示詞(prompt),讓Gemma成為你最得力的助手。
提示工程(Prompt Engineering),是這一兩年隨著 chatgpt 問世開始爆火的一種技術,甚至還出現 prompt engineer 這樣專門的工種,其工作內容就是開發和優化輸入給 LLM 的提示,以便有效地使用語言模型(LM)進行各種應用和研究主題。現在從學生寫作業到科學家做研究,許多人早已離不開大語言模型的輔助。
有大量的研究發現,透過精心設計的 prompt ,可以激發大語言模型的內在潛能,使模型的回答更符合我們心中所想(參考1, 2)。
最近在 X(前身為 Twitter) 上有一個自稱"prompt god"提示詞之神的用戶@BLUECOW009,開發一個超級 prompt,裡面只有寥寥數句人類可以理解的話,其餘都是一些 XML 標籤、符號、函數等文字。
據說這個超像亂碼的 prompt ,可以讓 LLM 乖乖照個你所想的去做,還能讓 LLM 具備創造性科學思維(尊督假督啦??)

今年二月,kaggle 上舉辦 LLM Prompt Recovery:Recover the prompt used to transform a given text 這個為期兩個月的競賽。
我們可以把平常和 LLM 互動的模式用數學表示如下: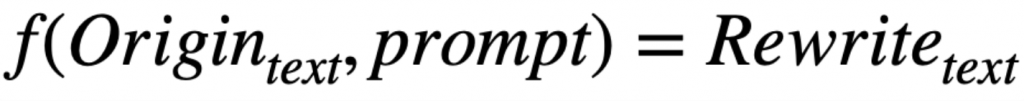
那這個比賽就是要根據 Gemma-7B LLM 改寫好的文字以及原始的文字,推測出你給 LLM 的改寫指令,也就是找到 function g: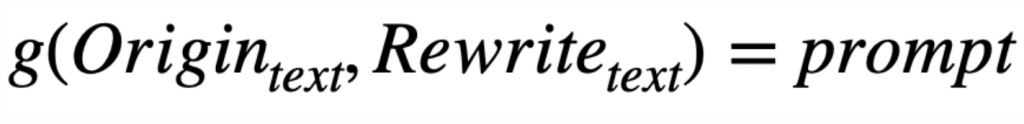
舉實際的例子會更清楚。
這一個原始的文本段落:
The competition dataset comprises text passages that have been rewritten by the Gemma LLM according to some rewrite_prompt instruction. The goal of the competition is to determine what prompt was used to rewrite each original text. Please note that this is a Code Competition. When your submission is scored, this example test data will be replaced with the full test set. Expect roughly 2,000 original texts in the test set.
這是一個經過 Gemma LLM 根據某個 prompt 改寫後的文本:
Here is your shanty: (Verse 1) The text is rewritten, the LLM has spun, With prompts so clever, they've been outrun. The goal is to find, the prompt so bright, To crack the code, and shine the light. (Chorus) Oh, this is a code competition, my dear, With text and prompts, we'll compete. Two thousand texts, a challenge grand, To guess the prompts, hand over hand.(Verse 2) The original text, a treasure lost, The rewrite prompt, a secret to be
你有發現這個改寫過的文本好像句子更短促、三四個字為一小句,就好像有節奏的歌詞嗎?
其實就是 Gemma LLM 根據下面的 prompt 所修改的:
Convert this into a sea shanty: """The competition dataset comprises text passages that have been rewritten by the Gemma LLM according to some rewrite_prompt instruction. The goal of the competition is to determine what prompt was used to rewrite each original text. Please note that this is a Code Competition. When your submission is scored, this example test data will be replaced with the full test set. Expect roughly 2,000 original texts in the test set."""
"Convert this into a sea shanty" 的意思是「將這段文字轉換成海員歌曲(海洋民謠)」。海員歌曲,或稱 Sea Shanty,是一種傳統的航海歌曲,通常以簡單的韻律和重複的旋律來表達海員在工作時的節奏與團結。這種歌曲往往有強烈的節奏感,容易傳唱。
這個比賽也是 code competition,而且他甚至不算有提供 training data,他的 trainset 只有一筆 data(就上面這個例子),提供給我們的 testing data 也只有一個範例。
實際在評測時,後台 host 的 testset 有包含 1,400 筆主辦方自己的未公開的 origin text 與 prompt,以及用這些 prompt 輸入到 Gemma 生成的 rewrite text。只是這些我們當然是都看不到的啦!
整個比賽很清楚就是要參賽者自己想辦法去產生訓練資料,Host 甚至有提供一個 starter notebook,教大家怎麼去生成可用的訓練資料。(這個比賽有有史以來最高的 (price money)/(training samples) ratio呦xdd)
比賽使用的評估指標是基於 sentence-t5-base 模型來生成文本的嵌入向量,然後通過銳化餘弦相似度來比較預測結果和真實答案的語義相似度。具體的計算步驟如下:
對於每一行提交的預測結果和相應的真實答案,使用 sentence-t5-base 模型來計算每個文本的嵌入向量(embedding vectors)。這些向量表示文本在語義空間中的位置。
接著,對每一對預測和真實答案的嵌入向量,計算它們之間的 Sharpened Cosine Similarity(SCS,銳化餘弦相似度)。
餘弦相似度 是一種常用來衡量兩個向量之間角度相似性的指標,範圍通常在 -1 到 1 之間。1 表示兩個向量完全相同,0 表示兩個向量正交,-1 表示完全相反。
這裡的 Sharpened Cosine Similarity 使用了一個指數參數,設定為 3,來對餘弦相似度進行「銳化」。這意味著,該公式會對餘弦相似度進行變換,使高相似度的分數進一步增強,而對於錯誤答案(即相似度較低的向量)會產生較小的分數。
具體例子:
假設我們有三個預測答案的餘弦相似度分數,分別是:
預測 1:相似度 0.9(非常接近正確答案)
預測 2:相似度 0.5(部分相似,但不完全正確)
預測 3:相似度 0.2(幾乎是錯誤答案)
當我們應用 Sharpened Cosine Similarity,指數為 3 時,公式是: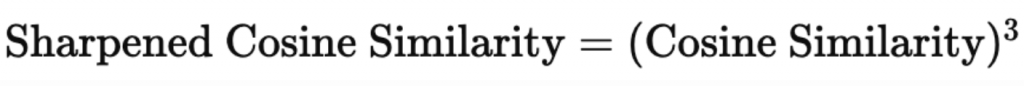
預測 1:
餘弦相似度為 0.9,經過銳化處理後:
SCS=(0.9)^3=0.729
原本的 0.9 分數,經過銳化,略微下降,但還是維持較高的分數。
預測 2:
餘弦相似度為 0.5,經過銳化處理後:
SCS=(0.5)^3=0.125
原本 0.5 的分數,被壓低到 0.125。這顯示出 SCS 對於不完全正確的預測,分數會大幅減少。
預測 3:
餘弦相似度為 0.2,經過銳化處理後:
SCS=(0.2)^3=0.008
原本的 0.2 分數,經過銳化後接近於 0。這意味著錯誤答案得分進一步降低。
目前為止,你已經了解比賽的目標、資料集的概況以及 output 的格式了,與評分所使用的 metric 了。
❓❓可以暫停一下,思考看看,如果你是參賽者,你會如何設計你的第一個解題方案呢?你的第一步是什麼❓❓
我承認....這題真的滿難的🤯(但獎金也很高💰💰💰💰
以前不知道要幹嘛,至少可以開始就 training data 開始做 EDA 分析,現在連資料都要自己生....我怎麼知道生出來的 data 和主辦方那邊的會不會差異很大....
既然如此,我們就先來看看Host提供的 Starter Notebook 吧!
在這次競賽中,我們的最終目標是拿到一段原始文本和由Gemma重寫後的新版本文本,並找出用於生成新版本的提示詞(prompt)。一個有用的初步步驟是能夠生成大量這樣的示例,這樣我們就可以學習原始文本、重寫提示詞和重寫後文本之間的關系。
為了生成這些示例,我們需要以下幾樣東西:
雖然我們對競賽測試集中使用的原始文本了解不多,但一個可能的初步嘗試,是使用 meta-kaggle 裡面關於 kaggle 討論區訊息的一些文本,ForumMessages.csv,作為 origin text。
然後自己設定幾個可能的 rewrite prompt 如下:
rewrite_prompts = [
'Explain this to me like I\'m five.',
'Convert this into a sea shanty.',
'Make this rhyme.',
]
現在來到有趣的部分!我們可以使用Gemma-7b來根據我們創建的rewrite prompt重寫origin text。
需要注意的重要事項如下:
我們使用的是有 7b 參數的 instruction tuned quantized model,這意味著:
7B parameters:這是兩個Gemma模型中較大的一個(另一個有2B參數)。一般來說,較大的模型在處理覆雜任務時表現更好,但對資源的要求也更高。你可以在這里看到Gemma 7B與Gemma 2B的具體對比。
instruction tuned:instruction tuned是一個額外的訓練步驟,使得模型能夠更好地遵循用戶的指令。我們的rewrite prompt就是一種指令,所以我們需要這一點!
quantized:量化是一種通過降低每個參數的精度來減小模型大小的方法;因此,盡管我們的模型仍然有7B個參數,但在有限的硬件上運行起來更容易。
接下來我們嘗試 load gemma-7b model,可以使用gemma_pytorch的工具:
import sys
sys.path.append("/kaggle/working/gemma_pytorch/")
from gemma.config import GemmaConfig, get_config_for_7b, get_config_for_2b
from gemma.model import GemmaForCausalLM
from gemma.tokenizer import Tokenizer
import contextlib
import os
import torch
# Load the model
VARIANT = "7b-it-quant"
MACHINE_TYPE = "cuda"
weights_dir = '/kaggle/input/gemma/pytorch/7b-it-quant/2'
@contextlib.contextmanager
def _set_default_tensor_type(dtype: torch.dtype):
"""Sets the default torch dtype to the given dtype."""
torch.set_default_dtype(dtype)
yield
torch.set_default_dtype(torch.float)
# Model Config.
model_config = get_config_for_2b() if "2b" in VARIANT else get_config_for_7b()
model_config.tokenizer = os.path.join(weights_dir, "tokenizer.model")
model_config.quant = "quant" in VARIANT
# Model.
device = torch.device(MACHINE_TYPE)
with _set_default_tensor_type(model_config.get_dtype()):
model = GemmaForCausalLM(model_config)
ckpt_path = os.path.join(weights_dir, f'gemma-{VARIANT}.ckpt')
model.load_weights(ckpt_path)
model = model.to(device).eval()
接下來開始產生data:
rewrite_data = []
for original_text in original_texts:
rewrite_prompt = random.choice(rewrite_prompts)
prompt = f'{rewrite_prompt}\n{original_text}'
rewritten_text = model.generate(
USER_CHAT_TEMPLATE.format(prompt=prompt),
device=device,
output_len=100,
)
rewrite_data.append({
'original_text': original_text,
'rewrite_prompt': rewrite_prompt,
'rewritten_text': rewritten_text,
})
當然除了使用 forum dataset,也可以使用像是下面的不同資料集當作 origin text 的來源:
那麼我們整理一下,現在初步的解題思路應該是這樣:
示意圖如下: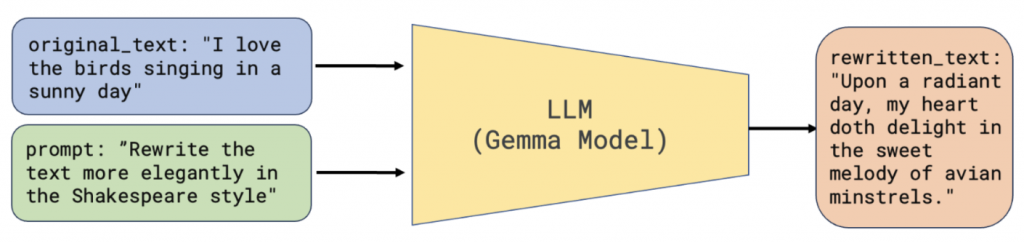
(reference to 3)
訓練一個 LLM,根據輸入的 origin_text 和 rewrite_text,預測生成其 rewrite_prompt>
示意圖如下: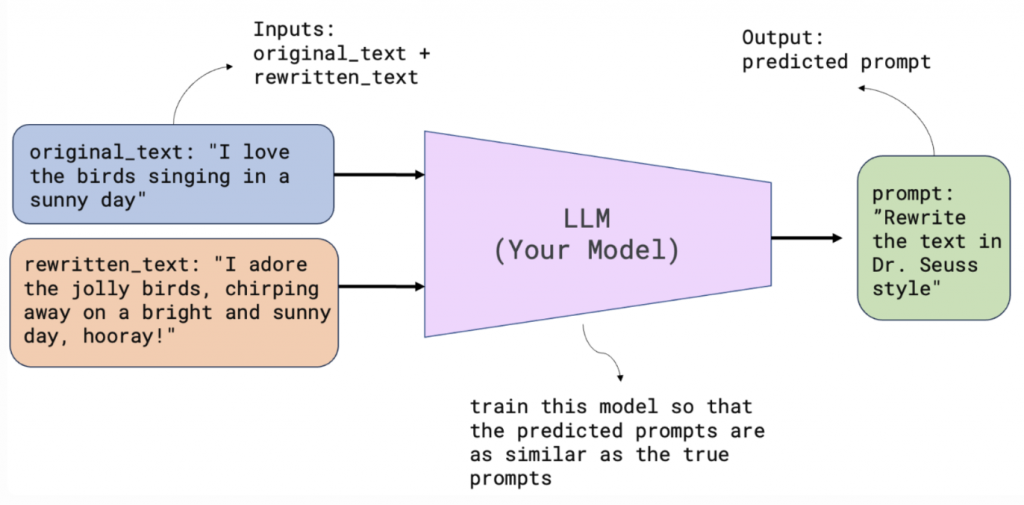
(reference to 3)
有了預測出來的predict_rewrite_prompt,就可以用 sentence-t5 model 將它還有 ground truth 轉成向量,計算Sharpened Cosine Similarity。
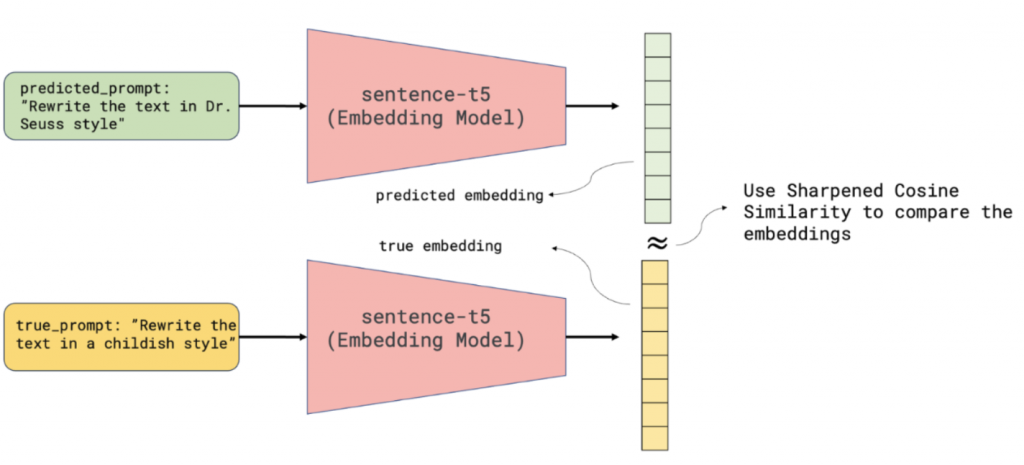
❓❓接下來,你可以暫停一下,試想看看以上每個步驟可能會遇上哪些問題呢❓❓
我先來:
我們不管是自己想的、或是基於某種規則產生的 rewrite prompt(也許又是找另外一個如 gpt4 生成的) 可能不那麼適合,或甚至有點怪異:
例如:
"Rewrite this as a brief to be briefed"
"Transform this text into a powerpoint presentation"
這些就有點怪怪,而且我們也不知道到底這些 rewrite prompt 要多長多短有什麼特色。
Gemma 根據 origin_text 和 rewrite prompt 產生的 rewrite text 不一定適合。
要知道,要讓一個語言模型生成文字,可以設定很多東西,像是 decode 的 temperature, top_p 等等,我們也不知道生成的 rewrite text 是否貼近 test data。
其他可能還會遇到一些問題....
明天會直接帶大家看看一些simple baseline,以及這些方法遇到的問題;再逐漸解析前幾名的優勝作法!
那我們明天見~
註:本章開始因為我個人研究興趣有所偏好,文章順序會和一開始的規劃有些不同,但是當初說好會會介紹的賽題都會寫到喔!不過後續賽題,不太會像前面幾天的在 EDA 上著墨甚多,後續會更著重在前幾名的優勝解法分析,大約每個賽題會花三天去寫,所以後面可能會加碼一個 LLM 幻覺(Hallucination)的專題討論。
謝謝讀到最後的你,希望你會覺得有趣!
如果喜歡這系列,別忘了按下訂閱,才不會錯過最新更新,也可以按讚給我鼓勵唷!
如果有任何回饋和建議,歡迎在留言區和我說✨✨
(Kaggle - LLM Prompt Recovery 解法分享系列)
